Bayesian
Bayesian refers to any method of analysis that relies on Bayes' equation. Developed by Thomas Bayes (died 1761), the equation assigns a probability to a hypothesis directly - as opposed to a normal frequentist statistical approach, which can only return the probability of a set of data (evidence) given a hypothesis.
| The poetry of reality Science |
| We must know. We will know. |
| A view from the shoulders of giants. |
v - t - e |
In order to translate the probability of data given a hypothesis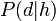 to the probability of a hypothesis given the data
to the probability of a hypothesis given the data 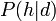 , it is necessary to use prior probability and background information. Bayesian approaches essentially attempt to link known background information with incoming evidence to assign probabilities.
, it is necessary to use prior probability and background information. Bayesian approaches essentially attempt to link known background information with incoming evidence to assign probabilities.
Since science aims to determine the probability of hypotheses, Bayesian approaches to analysis provide a link to what we really want to know. They also help to elucidate the assumptions that go into scientific reasoning and skepticism.
Bayes and probability
Probability of the hypothesis versus the data
The main focus of probability theory is assigning a probability to a statement. However, probabilities cannot be assigned in isolation. Probabilities are always assigned relative to some other statement. The sentence "the probability of winning the lottery is 1 in 100 million" is actually a fairly meaningless sentence. For example, if I never buy a lottery ticket my probability is significantly different than someone who buys 10 every week. A meaningful "sentence" in probability theory must be constructed with both the statement we seek to assign a probability to and the background information used to assign that probability. The essential form is "the probability of x given y is z." The probability calculus short hand for this sentence is  .
.
When we seek answers to a question or understanding of a phenomenon we usually start by forming a hypothesis; data is then collected that seeks to provide information about the reality of that hypothesis. Ultimately we seek to know, what is the probability that our hypothesis is correct? In this case our background information is the relevant data we have collected. So in probability speak we seek to know what is equal to. In this case h is our hypothesis and d is our data.
Things start to get a little complicated from here. Let's imagine we are asking a simple question, like "is this coin I have fairly weighted?" We hypothesize that if it is fairly weighted, flipping it should result in an equal numbers of heads and tails. We flip it 10 times and come up with 6 heads and 4 tails. With this information, can we answer the question of what equals? The answer is that we cannot. The only question we can answer is what is equal to.
This is a subtle but very important point. Given only a hypothesis and some relevant data, we can only ever answer how probable our data is given our hypothesis, not the other way around. These two pieces of information are not equal. To see why, let's form some probability sentences with everyday concepts and see what happens when we reverse them:
- The probability that it is cloudy outside given that it is raining does not equal the probability that it is raining given it is cloudy outside.
- The probability that someone is drunk given they consumed 10 beers is not equal to the probability that someone consumed 10 beers given that they are drunk.
- The probability that the Antichrist is coming given that it's in the Bible does not equal the probability that the Antichrist is in the Bible given that he is coming.
So given that does not equal , what sorts of answers can we get about ? This is the classic approach to statistics that has come to be called the frequentist approach.
Frequentist approaches
The frequentist approach is the standard statistical model taught in most high schools, colleges and graduate school programs. It seeks to find the answer to what P( d | h) equals. Based on our example of a coin being flipped, the frequentist essentially asks: if one did a whole lot of sets of 10 flips, how often would I get a distribution of 6 heads and 4 tails? The answer of course depends on whether the coin is fairly weighted or not. The frequentist will usually ask how likely that distribution is to appear if the coin is weighted fairly and if it is not weighted fairly. Since being weighted fairly means that the result of heads or tails is essentially random, that question can be generalized to asking what is the distribution if we assume our results are random. This is known as the null hypothesis and is the "omnibus" test for frequentist statisticians. You can take any data distribution and ask: what are chances of this data distribution appearing given it is caused at random? If there is a high chance that it can appear, then we say that it appeared as random. If there is a low chance it appeared, we say that something had to cause it. Usually some sort of percentage cut off is used, the standard being 5 percent, meaning that there must be less than a 1/20 chance of forming a given distribution assuming random cause before we are willing to say there must be a non-random cause. This is called "significance".
There are many complicated statistical procedures that can be used to further differentiate causes beyond just "random" or "non-random", but all of them rest on the same basic idea of providing some sort of arbitrary statistical cut off where we assume something is unlikely enough that it has to be something else. This, however, is not really the case. As previously stated, we cannot actually assign a probability to our hypothesis. If our data only has a 1% chance of appearing if the cause is random, this does not mean that there is only a 1 percent chance that the hypothesis that our cause is random is true or that there is a 99 percent chance that our data is caused by something non-random. The frequentist approach, while providing valuable information and hinting at the relationships between hypotheses, can not tell us the probability of a hypothesis being true.
To understand why this is the case, and to understand how we can do this, we must turn to Bayesian inference.
Bayes' Equation
We have generated our data, run all the stats on it, and come up with the encouraging results that our data should only appear 1 percent of the time if it's randomly caused. Why then are we not safe in assuming, at the very least, that it is not randomly caused and that our hypothesis is more likely than random chance? The answer to this question has to do with the prior probabilities of each hypothesis, or in Bayesian parlance just "priors." Let's illustrate this with a little story:
You're walking down the road when you hear a whisper in the alleyway calling you over. Curious, you enter. A stranger is standing against the wall. He tells you that he can predict any series of numbers that will be chosen by man or machine. This includes tonight's lottery numbers, and he is more than willing to tell you what they will be in exchange for $1000 in cash. That would certainly be a good deal... if his story is true. You, however, are skeptical of his claim for many obvious reasons and ask for him to prove it. The man agrees and asks you to pick a number between 1 and 5, you do so, and seconds later he tells you the exact number you picked. Would you hand over the thousand dollars now? Most people would not, for such a feat is not that impressive. Lets instead say he told you to choose a number between 1 and 100 and guessed it exactly. While this is more intriguing, it is probably not worth the $1000. What about 1 in 1000, 1 in 100,000, 1 in 1,000,000, 1 in 100,000,000? Eventually we will reach a point where we are convinced enough to turn over our money.
Now let's look at a different story. You enter a novelty shop at the local mall and spot a package of dice that tells you they are weighted to roll a 6 every time. Intrigued, you open a package and roll a die. Sure enough, it comes up 6. Are you willing to say that these dice are probably weighted? Maybe you will roll a second time, but how many people will remain unconvinced after the 2nd or 3rd roll? Not many.
So in the first scenario most people are willing to ascribe to random chance when it was only 1 in 100 or 1 in 1000 likelihood, while in the second a 1 in 6 or 1 in 36 chance was all it took to convince people that it was not random. What is the difference? It is the prior likelihood for each hypothesis that separates these out. In this first scenario nothing makes sense. Everyone knows psychic abilities have never been demonstrated, why is this guy in an alley and why is he selling a $100 million lottery ticket for $1000? Sure it might be true, but the chances are tiny. In the second scenario you are in a respected shop looking at a commercial good with clearly labeled and professional packaging, so it's probably telling you the truth about being weighted.
Let's break this down into something a little more quantifiable. For the sake of argument, let's assume that the chance the guy in the alley is telling the truth is 1 in 10,000,000. What is more likely; the 1 in 10,000,000 chance that he is telling the truth, or the 1 in 100 chance that he guessed your number randomly? In the second scenario, let's say that the chances the package is lying about the dice is 1 in 100, so the chances that it's lying and you randomly rolled a 6 is 1 in 600 while the chances that the package is telling the truth is 99/100 (100 percent chance you will roll a 6). In this case, the probability a single roll of a 6 with a die in a wrongly labeled package is far lower than the package being labeled correctly.
As these examples hopefully show, the only way to move from to is to take into account our prior beliefs about the probability of each hypothesis. The Bayes equation is the equation that relates and our priors, and calculates what equals. The equation is simple and is made up of three parts, the first is the priors which we just talked about or 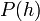 , the second is called the likelihood probability, which is simply , and the last is called the posterior probability, which is . Bayes equation then looks like:
, the second is called the likelihood probability, which is simply , and the last is called the posterior probability, which is . Bayes equation then looks like:
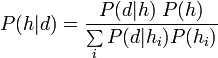
Since the posterior probability is the holy grail of most questions humanity has asked, understanding the Bayes equation and its parts and how they relate to each other can tell us much about the optimal way of gaining and testing knowledge about the world.
Bayes and Science
Science is predominantly interested in comparing various hypotheses to determine which are the more probable among a set. This means that, with very rare exceptions, the probability researchers want is . However, the vast majority of statistics used in modern publications are based on frequentist approaches that can only return . Since frequentist approaches cannot tell you directly about the probability of a hypothesis, various ad hoc approaches have been attempted to force the results to fit this mold. The most frequently used device is the concept of statistical significance. This approach assigns an often arbitrary cut off to such that when the probability is below the threshold, it's “significant” and supports the hypothesis, and when it's above the threshold, a given hypothesis is rejected and random chance is favored.
While this approach is immensely popular and dominates current reporting techniques in most peer reviewed journals, it is fraught with problems (see: statistical significance for a discussion of these issues). Bayesian approaches offer a solution to many of the problems exhibited by frequentist methods. Since Bayes equation returned directly, there is no need for arbitrary devices such as statistical significance. For these reasons, there is a growing group of researchers that advocate the use of Bayesian statistics in reporting on scientific findings.
However, Bayesian statistics is not without its own issues. The most prominent issue surrounds the construction of priors. Since priors are fundamental to any Bayesian approach, they must be considered carefully. If two different researchers used two different priors, then the results of the statistics would be very different. Since posterior probabilities from previous work can be used as priors for future tests, the real issue centers around the initial priors before very much information is available. Some feel that setting priors is so arbitrary that it negates any benefit of using Bayesian approaches. If no information is available when setting initial priors, most people will use what is referred to as uniform prior. A uniform prior merely sets all possible hypotheses to an equal initial prior probability. Another approach is to use a reference prior, which is often a complex distribution created to specifically eliminate as much role of the prior in calculating a posterior as possible. However, this method is criticized as essentially eliminating any gain from using a Bayesian approach at all.
Bayesian reasoning and the rational mind
For many years, social sciences used the formulated concept that humans were inherently rational to guide predictive models of social, political and economic interactions. This concept is often labeled Homo economicus and has come under fire for a myriad of reasons, not the least of which is that people do not appear to behave rationally at all. A great amount of evidence in both economics and psychology have shown what appears to be consistent sub-optimal and irrational reasoning in laboratory experiments. Several of the more widely cited examples are:
Co-variation analysis
When attempting to gather information about whether two variables correlate with each other, there are four frequencies that can be gathered :
- A is present and B is absent
- B is present and A is absent
- A is present and B is present
- A is absent and B is absent
Each of these should a priori carry the same weight when assessing correlation, but people will give far more weight to the case when both are present, and the least amount of weight to the case when both are absent.
Another related and classic task is the Wason selection task, where subjects are asked to test a conditional hypothesis ' if p then q '. Subjects are usually requested to turn over cards that obey the given rule. For example, the hypothesis might be "If there is a vowel on one side, then there is an even number on the other side" then four cards are displayed such that two cards show the p and q and two cards show not p and not q for example A,K,2,7. In classic reasoning the cards to turn over are p and not q (A, 7)as these are the only ones that could falsify the rule. Fewer than ten percent of people will follow this pattern and most will instead turn over p and q cards (A, 2). This is viewed as classic irrationality. Surprisingly, people fare a lot better on this task when the problem is formulated in terms of cheating in a social exchange, e.g. "A child can eat the dessert only if s/he ate the dinner".
Framing effects
Descriptions of events can often be phrased in more than one logically equivalent way, but are often viewed differently. One common example is reporting survival statistics after diagnosis of disease. People will feel more optimistic when told that they have a "75 percent chance of survival" than when told they have a "25 percent chance of dying." These statements are logically equivalent and should not invoke different responses, but they clearly do. This has also been assessed many times in risk tasks, where people are told they have a "75 percent chance of winning points" versus a "25 percent chance of losing points." People will select the task phrased in positive language and not select the task when phrased in negative language.
Bayes to the rescue
These examples plus others have been used to argue that people are actually irrational actors. However, these tasks are fairly contrived in the laboratory setting. The major missing ingredient in all of this is that people do not make choices in a vacuum. Prior information and experience can alter what choice is the most optimal. Reasoning that takes into account prior information along with basic logical and likelihood information is inherently Bayesian. A significant amount of evidence has emerged in the fields of cognitive psychology and neuroscience that humans use Bayesian approaches to assess their environment and make predictions. This occurs both at a low level in sensory processing, where neuron firing patterns seem to encode the probability distributions and handle the computations, and at a higher level of thought with people making executive decisions. When Bayesian approaches are used to analyze the above tasks, it turns out people are performing fairly optimally.
Subject performance in the co-variation tasks and task selection above makes a lot more sense when you consider that most conditional hypotheses are formulated for the rare events rather than the common events. For example, if we are testing the correlation that smoking causes cancer, we know that smoking is relatively rare, and we know that cancer is relatively rare, then the four types of frequencies should no longer be equally weighted. Since there are a lot of people who do not smoke and a lot who do not have cancer, finding someone who does not smoke and does not have cancer is going to happen far more frequently by random chance than finding people who smoke and have cancer. This is exactly the distribution of weighting we see in the laboratory tests.
For framing effects, it's important to realize that information in the real world is rarely communicated completely accurately. Social psychologists have found that people choose to phrase things in an optimistic or pessimistic fashion not randomly, but in a predictable way. People will describe a glass as "half-full" if it was empty and they watched it filled up half-way, but describe it as "half-empty" if it was full and was emptied by half. Therefore, taking into account social information and communication as background information, Bayesian reasoning may treat seemingly equivalent logical statements as actually conveying different information. Once again, this is how people behave in the laboratory.
Evidence then seems to point to the fact that people are Bayesian reasoners, and can perform far more optimally and rationally than they are usually given credit for.
Bayes and illusions
In addition to the evidence that higher order cognitive functioning follows a Bayesian approach, there is a lot of evidence that lower order systems in the subconscious also use an analogous method. It appears that neurons encode and analyze sensory information using firing patterns to form probability distributions. This means that both a likelihood and priors are calculated for any stimuli. This may help explain many interesting aspects of cognitive processing. One recent example is this block of text which has been circling around the internet:
“”Aoccdrnig to rscheearch at Cmabrigde Uinervtisy, it deosn't mttaer in waht oredr the ltteers in a wrod are, the olny iprmoatnt tihng is taht the frist and lsat ltteer be at the rghit pclae. The rset can be a toatl mses and you can sitll raed it wouthit a porbelm. Tihs is bcuseae the huamn mnid deos not raed ervey lteter by istlef, but the wrod as a wlohe. |
The ability to read this paragraph so easily can be attributed to the Bayesian nature of cognitive processing. The letters present, as well as the anchoring of the first and last letter, provide fodder for a calculation of word likelihood. Having learned the priors after exposure to many sentences over a lifetime, it is very easy to reconstruct the actual meaning, even though the input is jumbled. Bayesian analysis of sensory input may also be the cause of many optical illusions. One example is illusions that are based on concave and convex. Below are two copies of the same image, rotated 180 degrees with respect to each other:

The shift in concavity relies on a prior assumption that the light source comes from above. This is a perfectly sane and rational prior to build into the sensory system and would work under most conditions. But when there is actually no light source, and the difference in shades of color is real, the Bayesian mind winds up with the "wrong" hypothesis and hence the illusion. The "light from above" prior is one of the more specific Bayesian priors for optical illusions.
Another very powerful illusion created by the assumption of a light source is the Adelson's shadowed checkerboard illusion. This image is shown below. Take a close look at the squares marked A and B; they are actually the same shade of grey.

The illusion is caused because the various squares around A and B are shaded to create the image of a shadow. The prior assumption is that the difference in perceived shading is really due to a shadow cast by an unseen light source. The perceived brightness of the squares are then adjusted under the assumption of light and shadow.
One of the first optical illusions to be tackled in psychology is the famous Gestalt triangle shown below.

People tend to see a triangle occluding the other objects, rather than the other objects just lacking those pieces. Gestalt psychologists explained this as people processing objects as a whole rather than by pieces. The assumption is that there are three spheres and a dark lined triangle. The only way to make sense of this image then is to view an occluding second triangle. Knowing that the sensory system is Bayesian, this illusion can be explained more fully. A circle with a sector missing is a very rare occurrence. The prior for any such shape is that it is a whole sphere or circle. Additionally, the likelihood that all such objects with missing parts were to accidentally line up to create the shape of a triangle is very small. When these elements are combined in a Bayesian fashion, the hypothesis with the greatest probability is that there is an occluding triangle.
Sometimes the information a Bayesian analysis returns is ambiguous, with two or more competing hypotheses with about equal posterior probabilities. In this case, slight perturbations in the sensory stream (random noise, slight changes in perceptional environment, etc.) will cause the brain to switch back and forth between perceptions. This is probably the cause of the shifting in the perceived depth of the Necker cube shown below.

Optical illusions like the Necker cube that rely on ambiguous posterior probabilities can be highly sensitive to prior expectations. If two hypotheses for the perceived image are equal under uniform priors, then setting one prior higher than another should force the illusion to at least initially appear in that direction.
See also
- Essay:Bayesian Inference and the Power of Skepticism
- LessWrong
- Doomsday argument: does Bayesian reasoning imply that humans will become extinct within one thousand years? Spoiler alert: Maybe!
- Common sense
- Bayes' theorem and jurisprudence