10
1
Consider the following standard 15×15 crossword puzzle grid.
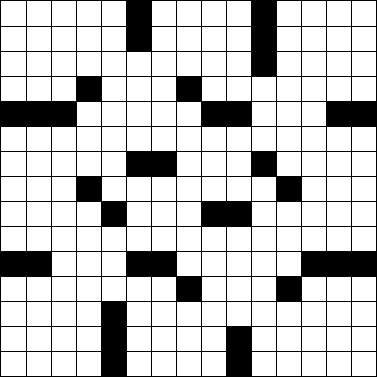
We can represent this in ASCII art by using # for blocks and (space) for white squares.
# #
# #
#
# #
### ## ##
## #
# #
# ##
## ## ###
# #
#
# #
# #
Given a crossword grid in the ASCII art format above, determine how many words it holds. (The above grid has 78 words. It happens to be last Monday's New York Times puzzle.)
A word is a group of two or more consecutive spaces running vertically or horizontally. A word starts and ends with either a block or the edge of the grid and always runs top to bottom or left to right, never diagonally or backwards. Note that words can span the whole width of the puzzle, as in the sixth row of the puzzle above. A word does not have to be connected to another word.
Details
- Input will always be a rectangle containing the characters
#or(space), with rows separated by a newline (\n). You can assume the grid is made of any 2 distinct printable ASCII characters instead of#and. - You may assume there is an optional trailing newline. Trailing space characters DO count, as they affect the number of words.
- The grid will not always be symmetrical, and it may be all spaces or all blocks.
- Your program should theoretically be able to work on a grid of any size, but for this challenge it will never be larger than 21×21.
- You may take the grid itself as input or the name of a file containing the grid.
- Take input from stdin or command line arguments and output to stdout.
- If you prefer, you may use a named function instead of a program, taking the grid as a string argument and outputting an integer or string via stdout or function return.
Test cases
Input:
# # #Output:
7(There are four spaces before each#. The result would be the same if each number sign were removed, but Markdown strips spaces from otherwise empty lines.)Input:
## # ##Output:
0(One-letter words don't count.)Input:
###### # # #### # ## # # ## # #### #Output:
4Input: (May 10's Sunday NY Times puzzle)
# ## # # # # # # # ### ## # # ## # # # ## # ## # ## # # ### ## # ## ## # ## ### # # ## # ## # ## # # # ## # # ## ### # # # # # # # ## #Output:
140
Scoring
Shortest code in bytes wins. Tiebreaker is oldest post.

NinjaBearMonkey
Posted 2015-06-05T14:05:37.590
Reputation: 9 925





Why are the two flags three bytes? – lirtosiast – 2015-06-05T15:45:07.340
@ThomasKwa I think the current policy with command line flags is this meta post, which counts the number of bytes as the difference from the usual invocation of the code. So here the difference is between
– Sp3000 – 2015-06-05T16:06:22.213py -3 slip.py regex.txt input.txtandpy -3 slip.py regex.txt input.txt no, which is three bytes (including the space beforen)That makes sense. I was thinking about it from an entropy perspective; sometimes I forget that it's characters we count. – lirtosiast – 2015-06-05T16:32:33.560