76
10
In the popular (and essential) computer science book, An Introduction to Formal Languages and Automata by Peter Linz, the following formal language is frequently stated:
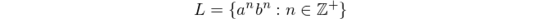
mainly because this language can not be processed with finite-state automata. This expression mean "Language L consists all strings of 'a's followed by 'b's, in which the number of 'a's and 'b's are equal and non-zero".
Challenge
Write a working program/function which gets a string, containing "a"s and "b"s only, as input and returns/outputs a truth value, saying if this string is valid the formal language L.
Your program cannot use any external computation tools, including network, external programs, etc. Shells are an exception to this rule; Bash, e.g., can use command line utilities.
Your program must return/output the result in a "logical" way, for example: returning 10 instead of 0, "beep" sound, outputting to stdout etc. More info here.
Standard code golf rules apply.
This is a code-golf. Shortest code in bytes wins. Good luck!
Truthy test cases
"ab"
"aabb"
"aaabbb"
"aaaabbbb"
"aaaaabbbbb"
"aaaaaabbbbbb"
Falsy test cases
""
"a"
"b"
"aa"
"ba"
"bb"
"aaa"
"aab"
"aba"
"abb"
"baa"
"bab"
"bba"
"bbb"
"aaaa"
"aaab"
"aaba"
"abaa"
"abab"
"abba"
"abbb"
"baaa"
"baab"
"baba"
"babb"
"bbaa"
"bbab"
"bbba"
"bbbb"
Leaderboard
Here is a Stack Snippet to generate both a regular leaderboard and an overview of winners by language.
/* Configuration */
var QUESTION_ID = 85994; // Obtain this from the url
// It will be like https://XYZ.stackexchange.com/questions/QUESTION_ID/... on any question page
var ANSWER_FILTER = "!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe";
var COMMENT_FILTER = "!)Q2B_A2kjfAiU78X(md6BoYk";
var OVERRIDE_USER = 48934; // This should be the user ID of the challenge author.
/* App */
var answers = [], answers_hash, answer_ids, answer_page = 1, more_answers = true, comment_page;
function answersUrl(index) {
return "https://api.stackexchange.com/2.2/questions/" + QUESTION_ID + "/answers?page=" + index + "&pagesize=100&order=desc&sort=creation&site=codegolf&filter=" + ANSWER_FILTER;
}
function commentUrl(index, answers) {
return "https://api.stackexchange.com/2.2/answers/" + answers.join(';') + "/comments?page=" + index + "&pagesize=100&order=desc&sort=creation&site=codegolf&filter=" + COMMENT_FILTER;
}
function getAnswers() {
jQuery.ajax({
url: answersUrl(answer_page++),
method: "get",
dataType: "jsonp",
crossDomain: true,
success: function (data) {
answers.push.apply(answers, data.items);
answers_hash = [];
answer_ids = [];
data.items.forEach(function(a) {
a.comments = [];
var id = +a.share_link.match(/\d+/);
answer_ids.push(id);
answers_hash[id] = a;
});
if (!data.has_more) more_answers = false;
comment_page = 1;
getComments();
}
});
}
function getComments() {
jQuery.ajax({
url: commentUrl(comment_page++, answer_ids),
method: "get",
dataType: "jsonp",
crossDomain: true,
success: function (data) {
data.items.forEach(function(c) {
if (c.owner.user_id === OVERRIDE_USER)
answers_hash[c.post_id].comments.push(c);
});
if (data.has_more) getComments();
else if (more_answers) getAnswers();
else process();
}
});
}
getAnswers();
var SCORE_REG = /<h\d>\s*([^\n,]*[^\s,]),.*?(\d+)(?=[^\n\d<>]*(?:<(?:s>[^\n<>]*<\/s>|[^\n<>]+>)[^\n\d<>]*)*<\/h\d>)/;
var OVERRIDE_REG = /^Override\s*header:\s*/i;
function getAuthorName(a) {
return a.owner.display_name;
}
function process() {
var valid = [];
answers.forEach(function(a) {
var body = a.body;
a.comments.forEach(function(c) {
if(OVERRIDE_REG.test(c.body))
body = '<h1>' + c.body.replace(OVERRIDE_REG, '') + '</h1>';
});
var match = body.match(SCORE_REG);
if (match)
valid.push({
user: getAuthorName(a),
size: +match[2],
language: match[1],
link: a.share_link,
});
});
valid.sort(function (a, b) {
var aB = a.size,
bB = b.size;
return aB - bB
});
var languages = {};
var place = 1;
var lastSize = null;
var lastPlace = 1;
valid.forEach(function (a) {
if (a.size != lastSize)
lastPlace = place;
lastSize = a.size;
++place;
var answer = jQuery("#answer-template").html();
answer = answer.replace("{{PLACE}}", lastPlace + ".")
.replace("{{NAME}}", a.user)
.replace("{{LANGUAGE}}", a.language)
.replace("{{SIZE}}", a.size)
.replace("{{LINK}}", a.link);
answer = jQuery(answer);
jQuery("#answers").append(answer);
var lang = a.language;
if (/<a/.test(lang)) lang = jQuery(lang).text();
languages[lang] = languages[lang] || {lang: a.language, user: a.user, size: a.size, link: a.link};
});
var langs = [];
for (var lang in languages)
if (languages.hasOwnProperty(lang))
langs.push(languages[lang]);
langs.sort(function (a, b) {
if (a.lang > b.lang) return 1;
if (a.lang < b.lang) return -1;
return 0;
});
for (var i = 0; i < langs.length; ++i)
{
var language = jQuery("#language-template").html();
var lang = langs[i];
language = language.replace("{{LANGUAGE}}", lang.lang)
.replace("{{NAME}}", lang.user)
.replace("{{SIZE}}", lang.size)
.replace("{{LINK}}", lang.link);
language = jQuery(language);
jQuery("#languages").append(language);
}
}body { text-align: left !important}
#answer-list {
padding: 10px;
width: 290px;
float: left;
}
#language-list {
padding: 10px;
width: 290px;
float: left;
}
table thead {
font-weight: bold;
}
table td {
padding: 5px;
}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b">
<div id="answer-list">
<h2>Leaderboard</h2>
<table class="answer-list">
<thead>
<tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr>
</thead>
<tbody id="answers">
</tbody>
</table>
</div>
<div id="language-list">
<h2>Winners by Language</h2>
<table class="language-list">
<thead>
<tr><td>Language</td><td>User</td><td>Score</td></tr>
</thead>
<tbody id="languages">
</tbody>
</table>
</div>
<table style="display: none">
<tbody id="answer-template">
<tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
<table style="display: none">
<tbody id="language-template">
<tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>














































































"Your program cannot use any external computation tools , including network , external programs etc" is already in our standard loopholes. – Leaky Nun – 2016-07-20T19:35:04.303
24Can the input be empty? (You're saying it's not part of the language, but not whether it's an input we need to consider.) – Martin Ender – 2016-07-20T20:04:01.697
1What if our language doesn't have truthy or falsy? Would
empty string == truthyandnon-empty string == falsybe acceptable? – James – 2016-07-20T20:20:26.190@LeakyNun it never hurts to specify it explicitly anyways – John Dvorak – 2016-07-21T07:43:52.533
I recommend a falsey test case like
"aababb". Also please clarify, are concatenations of valid strings valid? – LLlAMnYP – 2016-07-21T08:36:06.423@LLIAMnYP No , they aren't . Only strings in format of ab where a is before b and their counts are equal and non-zero , as explained in main post . – None – 2016-07-21T08:38:21.753
Oh, I see now, I've overlooked an appropriate falsey test case. – LLlAMnYP – 2016-07-21T08:59:43.570
5Nice challenge, but I think the title could be a little less ambiguous (i.e. a mention of
a^n b^nor similar, rather than just the number ofas equalling the number ofbs) – Sp3000 – 2016-07-21T12:28:28.8671@Sp3000 I choosed this title because it looked fun . I may change it later to sth else ... – None – 2016-07-21T13:27:05.897
When you say "can not be processed with finite-state automata", you're not talking about finite state automata with loops, right? If you are, how do you explain that I did it in sed?
– someonewithpc – 2016-07-22T22:25:04.1771I'm a little surprised that in 50+ answers I'm the only one to use a paser generator. To be sure it's not strictly competitive on length, but the problem posed is one of parsing a simple but non-trivial language. I'd very much like to see answers in other compiler-compiler syntaxes because I am not widely familiar with the choices. – dmckee --- ex-moderator kitten – 2016-07-22T22:47:41.583
1@someonewithpc this is what I found in Peter Linz's book . I also believe that it's not possible , because the automata must store
nin some way . the main problem is that , the count ofas andbs must be equal , otherwise it was possible . (note that for a finite possibilities ofnit's possible to make a machine with many states that accepts this language, (likea^2k b^2k) but I haven't specified any limit forn. ) also I think yoursedanswer is actually a Turing machine , but I'm not sure about that. – None – 2016-07-25T10:06:21.167Is it a given that the string will contain as and bs only? Or do we have to make sure we're not allowing cs and ds? – SQB – 2016-07-25T15:45:37.623
@SQB I'm not sure that I understood what you meant but input contains nothing other than as and bs . – None – 2016-07-25T17:26:00.677
@GLASSIC He wants to know if the parser needs to be prepared to reject an input like
aaabbc(which I have assumed it must), or if it can assume that nocwill appear in the input. – dmckee --- ex-moderator kitten – 2016-07-25T22:42:03.450@dmckee indeed. One approach could be checking if the second half of the word is the first half of the word, +1 on each letter. (I'm entertaining the thought of a brainf*ck entry). – SQB – 2016-07-26T10:50:11.603
@dmckee The fact that the Python answer using translate is a valid one, indicates that my assumption is correct. Otherwise
printabwould be incorrectly deemed a correct input. – SQB – 2016-07-27T16:01:59.483What about "rrss" or "rrzz"? It depends from the alphabetical letter too? – RosLuP – 2017-08-30T01:08:05.363