GolfScript, 300 chars
~8-:m;'!5?HZi " A 9 "$??HLTZ^`eik 5Z`e <^ $k H ,Sds ?LT /5@MUav I " i ? "5i G !#+.4;>@K]_cdhjy{| *HCRJD@:64122/42.,,*860-40-0.+9?B<862//?D<7=@:420-/5:60.-20.+./384/162.-HCRJD@:64122/42.,,*)! !""$&&('{32-}/]1,/~:&;:L;:T;]:S;0m>{&m=}{L,,{.49=\71=+}%:V{,(,{).V=\T?S={(V=+}/}%0+:V}m*,,0\{.V=\L=8-*+}/}if
Here's a slightly shorter entry. Reads a number m from stdin, writes the length of the m-th term in the look-and-say sequence to stdout.
For example, input 50 produces output 894810, while input 1000 produces (after a few seconds):
21465050086246039983937316427688400486337379416867195943208935654503780844828013651860410256502890125611856727316762
I'll post a more detailed explanation of the code later, but basically this also works by repeatedly multiplying a vector with a sparse matrix, encoded as an ASCII string. Some clever compression tricks, such as leaving out the all-ones superdiagonal of the matrix, are employed.
Ps. Here's a link to an online demo. The server has been pretty slow lately, though, so if you see an error message about a timeout, try again (or just download the interpreter and run it yourself).
Addendum: Here's the promised detailed explanation. First, let me repost the code with whitespace and comments added:
# Parse input, subtract 8, save in variable m:
~ 8- :m;
# This long string encodes all the constants used by the program (I'll describe it below):
'!5?HZi " A 9 "$??HLTZ^`eik 5Z`e <^ $k H ,Sds ?LT /5@MUav I " i ? "5i G !#+.4;>@K]_cdhjy{| *HCRJD@:64122/42.,,*860-40-0.+9?B<862//?D<7=@:420-/5:60.-20.+./384/162.-HCRJD@:64122/42.,,*)! !""$&&('
# Parse the data string:
# The data consists of several arrays of positive integers, encoded as printable ASCII
# characters and separated by spaces. (Note that this means that the range of possible
# data values starts from 1, which requires some adjustment below. Also, the values in
# L are actually shifted up by 8 to avoid having single quotes in the data string.)
{32-}/ # Subtract 32 (ASCII code of space) from each char and dump result on stack.
] # Collect numbers from stack into an array.
1,/ ~ # Split array on zeros (formerly spaces) and dump pieces on stack.
:&; # Save topmost piece (canned responses for inputs 1-7) in var &.
:L; # Save second piece (element lengths) in var L.
:T; # Save third piece (nonstandard decay targets) in var T.
]:S; # Collect remaining pieces (nonstd decay sources) in array and save it in S.
# If m < 0, return a precomputed response from &, else run the indented code below:
0 m > { & m = } {
# Set V to be the initial element abundance vector (1 Hf + 1 Sn):
# (Note: both L and V have an extra sentinel 0 at the end to avoid overruns below.)
L,, { . 49= \ 71= + } % :V
# Update the element abundances m times:
{
# Run the following block for all numbers i from 0 to length(V)-2,
# collecting the results in an array:
,(, {
# Start with the abundance of element i+1 in V (all elements except H decay
# downwards; the extra 0 at the end of V is needed to avoid a crash here):
).V=\
# If this element is one of the decay targets listed in T, find the corresponding
# list of source elements in S and add their abundances from V to the total:
# (If this element is not in T, we just loop over an empty array at the end of S.)
T? S= { ( V= + } /
} %
# Append a new sentinel 0 to the end of the array and save it as the new V:
0+:V
} m *
# Multiply the element abundances from V with their lengths from L and sum them:
,,0\{.V=\L=8-*+}/
} if
The key fact that allows this code to work is that, as the look-and-say transformation is repeatedly applied to any string, it eventually splits into substrings which evolve independently, in the sense that we can obtain all the following elements of the look-and-say sequence starting from that string by taking each of the substrings, applying the look-and-say transformation to each of them independently n times and concatenating the results.
Furthermore, in his 1986 article "The Weird and Wonderful Chemistry of Audioactive Decay" (which basically introduced the look-and-say sequence to the world), John Conway proved a remarkable (and, for this challenge, crucial) result which he called the "cosmological theorem":
Cosmological theorem (Conway): There is a set of 92 finite strings of numbers 1–3 (which Conway named after the chemical elements; see table here), and two infinite families of strings each consisting of a fixed prefix followed by some number higher than 3 (these can only appear if the initial string contained number higher than 3 or sequences of more than 3 identical numbers), such that, after at most 24 applications of the look-and-say transformation, any string splits into a chain of such elements, each of which thereafter evolves independently (and splits into further elements).
Thus, to determine the length of a string sufficiently far in the look-and-say sequence, it's sufficient to know how many times each element appears in it. And, since each element evolves independently, knowing these "elemental abundances" is also sufficient for calculating the corresponding abundances of the next string in the sequence, and so on.
As it happens, the look-and-say sequence starting from the string 1 splits into two Conway elements (Hf72 = 11132 and Sn50 = 13211) after just seven iterations. Thus, thereafter, we only need to keep track of the abundances of the 92 "common" elements (as the two families of "transuranic" elements cannot arise from common elements).
Mathematically, we can treat the elemental abundances as a vector of length 92. Calculating the abundances in the next step of the look-and-say sequence is then just equivalent to multiplying this vector with a 92 × 92 matrix, which is what r.e.s.'s solution does literally.
In fact, r.e.s.'s solution actually tracks the abundance of each element multiplied with its length (i.e. the "total mass" of that element in the string), adjusting the matrix accordingly, so that the total length of the string is given simply by adding the numbers in the abundance vector together. However, I did not find that a particularly convenient representation for code golf. (It was convenient for Nathaniel Johnston's derivation of Conway's polynomial, since it encodes the lengths into the matrix and thus gives the right eigenvalue for the asymptotic growth rate, but we don't care about that here.)
Instead, I just track the raw abundances of the elements, and only multiply them with the lengths at the end. This has, combined with the convenient fact that none of the decay products of any element contain more than one copy of any element, means that the entries of the transition matrix are just zeros and ones. Also, by far most of them are, in fact, zeros (in math jargon, the matrix is sparse), so I can save a lot of space by only storing the indices of those entries which are ones.
Also, in his article, Conway ordered the elements such that (except for H1 = 22, which is a fixed point of the look-and-say transformation), each element decays to the next lower element in the sequence (and possibly some others).
In fact, most elements decay only to the next lower elements. Thus, by using Conway's ordering of the elements, I can hardcode this "standard decay" as part of the iteration, so that I only need to store the matrix entries corresponding to the other, "nonstandard" decays, saving even more space.
(In fact, what I actually do, for reasons mostly to do with how GolfScript's array operations work, is store one array listing the matrix rows containing non-zero entries (i.e. the elements which are produced in nonstandard decays) and another array of arrays listing, for each of these rows, the columns where the non-zero entries occur (i.e. the elements which produce these elements in such decays). See the code and comments above for how these arrays are actually used to calculate the updated element abundances.)
The final space-saving trick I used was to encode all these arrays as strings of ASCII characters. Conveniently, there are 95 printable ASCII characters from space (32) to ~ (126), and the largest value that appears in any of the arrays is 92, so they fit very well. One extra tweak I made was to shift the values in the element length array (which only go up to 42 anyway) up by 8 so that I could avoid the character ' (39) and thus store my data in a single quoted string without having to add any backslash escape characters.
There are some other minor optimizations too, but those are just standard GolfScript coding tricks. I should note that the actual code is not all that carefully optimized — it's quite possible that it could be golfed down further.
In any case, despite the inherent slowness of a double-interpreted language like GolfScript, the code runs quite fast and scales well: computing the length of the 10,000th string in the look-and-say sequence takes about 1.5 minutes on my computer.
Conveniently, GolfScript stores all numbers as arbitrary-length integers (bignums), so I didn't have to do anything special to make it produce exact results even for large inputs.
The expected time complexity of this program is O(n log n) (as the element abundances grow linearly with n, and bignum addition takes O(log n) time), and the actual runtime seems to fit that prediction pretty well, as the graph below shows:
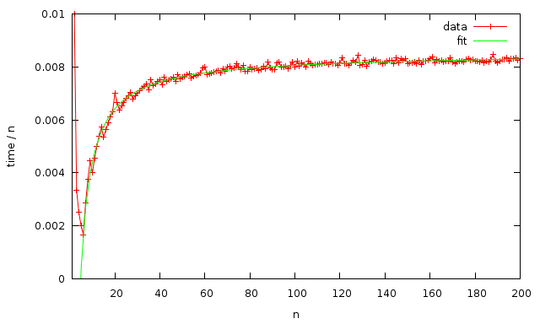
(Time is in seconds; for what it's worth, the green curve is given by y = (a x log(b + x) + c) / x, where a = 0.00106462026133545, b = 2720.25843721031 and c = -0.0401630789530016. The spike on the left mainly comes from the roughly constant runtimes for n < 8, which become relatively large when divided by small n. I did not include it in the curve fit.)





This is not like this.
– Soham Chowdhury – 2012-09-25T08:40:37.8472I don't understand. – flodel – 2012-09-25T09:49:01.330
@flodel "One 1. Two 1(s). One 2, one 1. One 1, one 2, two 1(s)..." – DavidC – 2012-09-25T15:33:22.103
2@DavidCarraher But what does
Numbers allowedmean? – Gareth – 2012-09-25T15:41:20.2971Yes, I know what the look and say sequence is. I don't understand without calculating the terms (or am puzzled how it would be possible without it) and numbers allowed. – flodel – 2012-09-25T15:53:45.227
The sequence starting from
1splits into the Conway elements Hf (11132) and Sn (13211) after seven iterations. From than point onwards, it should be possible to calculate the length of the sequence by iterating the element decay matrix. The biggest difficulty in golfing this is going to be compressing the matrix. – Ilmari Karonen – 2012-09-25T16:04:07.567@flodel I'm guessing that the poser meant that you can make numerical computations but cannot generate the LookAndSay output itself (nor use it internally). As for myself, I don't think it can be done. But I could easily be wrong. – DavidC – 2012-09-25T16:44:59.187
"Numbers allowed" is presumably because the "this" of "not like this" is a problem which explicitly disallows the use of any numerical character in the program. – Peter Taylor – 2012-09-25T21:43:46.427
1http://oeis.org/A005341 mentions an order-71 recurrence. It's linear and its characteristic polynomial is given at http://en.wikipedia.org/wiki/Look-and-say_sequence , so there is a closed form in terms of 71 constants. – Peter Taylor – 2012-09-25T22:04:19.267
To avoid ambiguity about what "without calculating the terms" means, may I suggest requiring that valid entries must run in at most O(n log n) time with respect to the input n? This should rule out any naive brute-force solution (which need exponential time and space), whereas I believe both r.e.s.'s solution and mine should pass. – Ilmari Karonen – 2012-09-26T17:39:31.640
I agree, will do. – Soham Chowdhury – 2012-09-26T17:43:17.780