160
73
Stroustrup has recently posted a series of posts debunking popular myths about C++. The fifth myth is: “C++ is for large, complicated, programs only”. To debunk it, he wrote a simple C++ program downloading a web page and extracting links from it. Here it is:
#include <string>
#include <set>
#include <iostream>
#include <sstream>
#include <regex>
#include <boost/asio.hpp>
using namespace std;
set<string> get_strings(istream& is, regex pat)
{
set<string> res;
smatch m;
for (string s; getline(is, s);) // read a line
if (regex_search(s, m, pat))
res.insert(m[0]); // save match in set
return res;
}
void connect_to_file(iostream& s, const string& server, const string& file)
// open a connection to server and open an attach file to s
// skip headers
{
if (!s)
throw runtime_error{ "can't connect\n" };
// Request to read the file from the server:
s << "GET " << "http://" + server + "/" + file << " HTTP/1.0\r\n";
s << "Host: " << server << "\r\n";
s << "Accept: */*\r\n";
s << "Connection: close\r\n\r\n";
// Check that the response is OK:
string http_version;
unsigned int status_code;
s >> http_version >> status_code;
string status_message;
getline(s, status_message);
if (!s || http_version.substr(0, 5) != "HTTP/")
throw runtime_error{ "Invalid response\n" };
if (status_code != 200)
throw runtime_error{ "Response returned with status code" };
// Discard the response headers, which are terminated by a blank line:
string header;
while (getline(s, header) && header != "\r")
;
}
int main()
{
try {
string server = "www.stroustrup.com";
boost::asio::ip::tcp::iostream s{ server, "http" }; // make a connection
connect_to_file(s, server, "C++.html"); // check and open file
regex pat{ R"((http://)?www([./#\+-]\w*)+)" }; // URL
for (auto x : get_strings(s, pat)) // look for URLs
cout << x << '\n';
}
catch (std::exception& e) {
std::cout << "Exception: " << e.what() << "\n";
return 1;
}
}
Let's show Stroustrup what small and readable program actually is.
- Download
http://www.stroustrup.com/C++.html List all links:
http://www-h.eng.cam.ac.uk/help/tpl/languages/C++.html http://www.accu.org http://www.artima.co/cppsource http://www.boost.org ...
You can use any language, but no third-party libraries are allowed.
Winner
C++ answer won by votes, but it relies on a semi-third-party library (which is disallowed by rules), and, along with another close competitor Bash, relies on a hacked together HTTP client (it won't work with HTTPS, gzip, redirects etc.). So Wolfram is a clear winner. Another solution which comes close in terms of size and readability is PowerShell (with improvement from comments), but it hasn't received much attention. Mainstream languages (Python, C#) came pretty close too.

Athari
Posted 2015-01-07T05:08:24.560
Reputation: 2 319

















































3Comments purged as they were all either obsolete or off-topic. – Doorknob – 2015-01-08T12:43:12.293
1Clarification: Shall the list of links be as incomplete as Stroustrup's one, i.e. skip any non-http-links that don't include
www(including the https, ftp, local and anchor ones on that very site) and report false-positives, i.e. non-linked mentions ofhttp://as well (not here, but in general)? – Tobias Kienzler – 2015-01-08T14:34:12.323Why is pointing out that ALL of the posted answers don't apply to what the OP asked, obsolete or off-topic? – Dunk – 2015-01-08T15:32:21.973
43To each his own, I've been called worse. If the OP's goal wasn't to try and somehow prove that Stroustrup is wrong, then I'd agree with your assessment. But the entire premise of the question is to show how "your favorite language" can do the same thing as this 50 lines of C++ in much less lines of code. The problem is that none of the examples do the same thing. In particular, none of the answers perform any error checking, none of the answers provide reusable functions, most of the answers don't provide a complete program. The Stroustrup example provides all of that. – Dunk – 2015-01-08T15:40:09.407
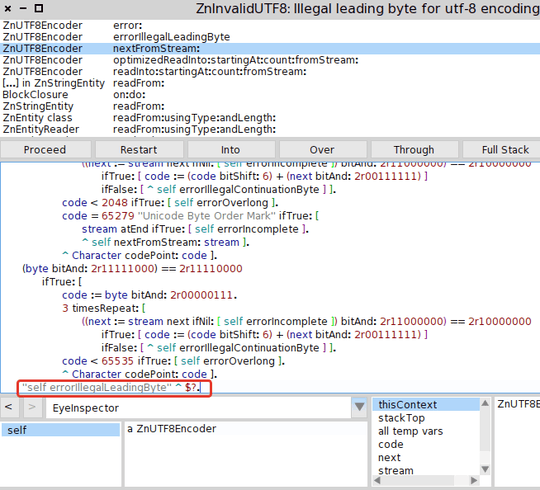
19What's sad is his web page isn't even valid UTF-8. Now I've gotta work around that, despite his server advertising
Content-Type: text/html; charset=UTF-8... I'm gonna email him. – Cornstalks – 2015-01-08T16:33:30.830I wish I'd thought of coming here and asking this question when I read that piece. Certainly C++ is better than it was in the past, but it's by no means optimal. – Mark Ransom – 2015-01-08T17:53:11.753
27@Dunk The other examples don't provide reusable functions because they accomplish the entire functionality of those functions in a single line and it makes no sense to make that a whole function on its own, and the C++ example doesn't perform any error checking that isn't handled natively in almost an identical manner, and the phrase "complete program" is almost meaningless. – Jason – 2015-01-08T21:09:56.453
16"You can use any language, but no third-party libraries are allowed." I don't think that's a fair requirement considering
boost/asiois used up there which is a third-party library. I mean how will languages that don't include url/tcp fetching as part of its standard library compete? – greatwolf – 2015-01-09T06:43:10.313@greatwolf They don't. That's the point. – Athari – 2015-01-09T12:21:08.510
1@Jason - upvote for "C++ example doesn't perform any error checking that isn't handled natively in almost an identical manner". – None – 2015-01-09T15:13:13.257
1
Virtually all the answers fail the task (including the original lol) because they don't pick up relative links! I did mine herE: http://forum.dlang.org/thread/tqegmjcofcnwapqitrdo@forum.dlang.org#post-nxcpwmyjfbfbjxqtmrzd:40forum.dlang.org
– Adam D. Ruppe – 2015-01-09T17:19:03.1504Is nobody gonna talk about using regexes to parse HTML? Really? I mean Stroustrup does it himself but at least his regex doesn't rely on the HTML-attribute using
"and only ever"to delimit its value. 9 out of 10 answers here would fail on<a href='http://htmlparsing.com/regexes.html'>– funkwurm – 2015-01-12T12:44:03.563@funkwurm Problems with the provided solutions have been mentioned many times, you just need to look through comments. The famous "parsing HTML with regex" answer from SO has been brought up too. Many comments have been removed by the mod though. – Athari – 2015-01-12T19:59:37.993
@undergroundmonorail BF++ does. It is giving me strange and deviant thoughts. – ymbirtt – 2015-01-14T16:29:33.650
2I have to admit, I'm surprised by Stroustrup's claim that most people believe that C++ is used for large programs. I (probably incorrectly) believe the opposite - that for large programs, it's worthwhile to use a language like Java or C# that makes it harder to shoot yourself in the foot! – Kevin – 2015-01-15T00:22:42.010
11
He's... parsing... html... with... regex... twitch
– Riot – 2015-01-15T05:53:35.8271Its a little odd to me that Stroustrup's challenge is to write C++ code that imports no third party code and the first line (or so, I'm not going to page back and lose my post thus far) is an import of boost's asio library. It kind of makes OP's opinion suspect. But in any case, comparing different languages in this task is very much like comparing apples and oranges. It doesn't really make much sense to use a hammer to tap in a pin, but it can be done; it doesn't make much sense to write assembly code to extract url's from a web page but it can be done. I suspect you could write a RoR program – None – 2015-01-15T04:07:04.293
2
This code snippet appears in a hacking scene on the Netflix series "Limitless"; Season 1, Episode 10, ~13:05. Proof: http://i.imgur.com/7a16H8y.png
– Dan – 2017-02-03T02:15:16.490