55
6
According to some controversial story, the odrer of ltteres in a wrod deos not mttaer much for raednig, as lnog as the frist and lsat lteter macth with the orignial wrod.
So, for fun, what would be the shortest function to randomize letter order in a word while keeping the first and the last letter in place?
Here's my stab at it with JavaScript. All whitespace removed it's at 124 130 characters.
function r(w) {
var l=w.length-1;
return l<3?w:w[0]+w.slice(1,l).split("").sort(function(){return Math.random()-.5}).join("")+w[l];
}
Shorter JavaScript always welcome.
- Edit: length check added. Function should not fail for short words.

Tomalak
Posted 2011-08-03T11:25:05.427
Reputation: 901




























































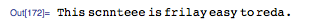





Can we assume that the word is not empty? – Martin Ender – 2015-03-27T16:31:23.040
Throughout the other answers valid results for edge cases ("short input") were required. The empty string qualifies as an edge case, so I'd say no. – Tomalak – 2015-03-27T17:03:46.427
Is there any reason this isn't just as simple as using a built in shuffle function? – Cyoce – 2015-12-27T07:56:30.947
@ThomasEding shuffling arbitrarily long strings uniformly would require that the random number generator has arbitrarily many bits in its state, so
idis a good compromise. – Angs – 2016-11-10T19:10:05.8073Haskell, 4 characters:
r=id. – Thomas Eding – 2011-08-03T20:01:53.710@trinithis Huh? – Tomalak – 2011-08-03T20:11:09.793
The randomizing function always returns the same (AHEM) random outcome. (
id x = xis a built in function. For Haskellers out there, I still thinkidshould be able to be written point-free style:id=) – Thomas Eding – 2011-08-03T20:14:10.440@trinithis I'm afraid I know nothing about Haskell. ;) Does that keep the first and last letters in place? – Tomalak – 2011-08-03T20:24:35.447
2Yes. It returns the exact same thing as the input. On another note, what do we do about punctuation? Do we only operate on words consisting only of letters? – Thomas Eding – 2011-08-03T20:28:38.617
@trinithis Yeah I assumed the function would only be fed with valid input, i.e. one word. ;) – Tomalak – 2011-08-03T20:33:36.793
1@trinithis not sure what you talking about, but
idis the identity function. I would still like to see Haskell solution to this problem in less than 100 characters. – Arlen – 2011-08-04T07:37:12.460To clarify the spec: is it required that the function takes an argument and returns the result or are other solutions acceptable? For instance, in C++ it’s much shorter not to bother with arguments and return type and just mutate some global state. – Konrad Rudolph – 2011-08-04T10:51:08.640
3Should the specification be updated to require a uniform distribution of outcomes? This would disallow the 4 character Haskell solution. It would also disallow your example Javascript solution (shuffling by doing a sort like that is not uniform). – Thomas Eding – 2011-08-04T17:25:24.497
1I would like to clarify that by uniform, we should treat the problem as if each character was unique. That is, duplicate letters will 'apparently' skew the distribution, but in actuality, it doesn't, because we are really working on the problem of permuting [1, 2, ..., n] while keeping 1 and n in the same spot. – Thomas Eding – 2011-08-04T17:49:52.073
2+1 for the first sentence: it actually took me a few seconds to realize it was spelled wrong XP – Nate Koppenhaver – 2011-08-04T18:33:09.900