C - 319 348 lines
This is a more or less direct translation of my Postscript program to C. Of course the stack usage is replaced with explicit variables. An instruction's fields are broken up into the variables o - instruction opcode byte, d - direction field, w - width field. If it's a "mod-reg-r/m" instruction, the m-r-rm byte is read into struct rm r. Decoding the reg and r/m fields proceeds in two steps: calculating the pointer to the data and loading the data, reusing the same variable. So for something like ADD AX,BX, first x is a pointer to ax and y is a pointer to bx, then x is the contents (ax) and y is the contents (bx). There's lots of casting required to reuse the variable for different types like this.
The opcode byte is decoded with a table of function pointers. Each function body is composed using macros for re-usable pieces. The DW macro is present in all opcode functions and decodes the d and w variables from the o opcode byte. The RMP macro performs the first stage of decoding the "m-r-rm" byte, and LDXY performs the second stage. Opcodes which store a result use the p variable to hold the pointer to the result location and the z variable to hold the result value. Flags are calculated after the z value has been computed. The INC and DEC operations save the carry flag before using the generic MATHFLAGS function (as part of the ADD or SUB submacro) and restore it afterwords, to preserve the Carry.
Edit: bugs fixed!
Edit: expanded and commented. When trace==0 it now outputs an ANSI move-to-0,0 command when dumping the video. So it better simulates an actual display. The BIGENDIAN thing (that didn't even work) has been removed. It relies in some places on little-endian byte order, but I plan to fix this in the next revision. Basically, all pointer access needs to go through the get_ and put_ functions which explicitly (de)compose the bytes in LE order.
#include<ctype.h>
#include<stdint.h>
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<sys/stat.h>
#include<unistd.h>
#define P printf
#define R return
#define T typedef
T intptr_t I; T uintptr_t U;
T short S; T unsigned short US;
T signed char C; T unsigned char UC; T void V; // to make everything shorter
U o,w,d,f; // opcode, width, direction, extra temp variable (was initially for a flag, hence 'f')
U x,y,z; // left operand, right operand, result
void *p; // location to receive result
UC halt,debug=0,trace=0,reg[28],null[2],mem[0xffff]={ // operating flags, register memory, RAM
1, (3<<6), // ADD ax,ax
1, (3<<6)+(4<<3), // ADD ax,sp
3, (3<<6)+(4<<3), // ADD sp,ax
0xf4 //HLT
};
// register declaration and initialization
#define H(_)_(al)_(ah)_(cl)_(ch)_(dl)_(dh)_(bl)_(bh)
#define X(_)_(ax) _(cx) _(dx) _(bx) _(sp)_(bp)_(si)_(di)_(ip)_(fl)
#define SS(_)_(cs)_(ds)_(ss)_(es)
#define HD(_)UC*_; // half-word regs declared as unsigned char *
#define XD(_)US*_; // full-word regs declared as unsigned short *
#define HR(_)_=(UC*)(reg+i++); // init and increment by one
#define XR(_)_=(US*)(reg+i);i+=2; // init and increment by two
H(HD)X(XD)SS(XD)V init(){I i=0;H(HR)i=0;X(XR)SS(XR)} // declare and initialize register pointers
enum { CF=1<<0, PF=1<<2, AF=1<<4, ZF=1<<6, SF=1<<7, OF=1<<11 };
#define HP(_)P(#_ ":%02x ",*_); // dump a half-word reg as zero-padded hex
#define XP(_)P(#_ ":%04x ",*_); // dump a full-word reg as zero-padded hex
V dump(){ //H(HP)P("\n");
P("\n"); X(XP)
if(trace)P("%s %s %s %s ",*fl&CF?"CA":"NC",*fl&OF?"OV":"NO",*fl&SF?"SN":"NS",*fl&ZF?"ZR":"NZ");
P("\n"); // ^^^ crack flag bits into strings ^^^
}
// get and put into memory in a strictly little-endian format
I get_(void*p,U w){R w? *(UC*)p + (((UC*)p)[1]<<8) :*(UC*)p;}
V put_(void*p,U x,U w){ if(w){ *(UC*)p=x; ((UC*)p)[1]=x>>8; }else *(UC*)p=x; }
// get byte or word through ip, incrementing ip
UC fetchb(){ U x = get_(mem+(*ip)++,0); if(trace)P("%02x(%03o) ",x,x); R x; }
US fetchw(){I w=fetchb();R w|(fetchb()<<8);}
T struct rm{U mod,reg,r_m;}rm; // the three fields of the mod-reg-r/m byte
rm mrm(U m){ R(rm){ (m>>6)&3, (m>>3)&7, m&7 }; } // crack the mrm byte into fields
U decreg(U reg,U w){ // decode the reg field, yielding a uintptr_t to the register (byte or word)
if (w)R (U)((US*[]){ax,cx,dx,bx,sp,bp,si,di}[reg]);
else R (U)((UC*[]){al,cl,dl,bl,ah,ch,dh,bh}[reg]); }
U rs(US*x,US*y){ R get_(x,1)+get_(y,1); } // fetch and sum two full-words
U decrm(rm r,U w){ // decode the r/m byte, yielding uintptr_t
U x=(U[]){rs(bx,si),rs(bx,di),rs(bp,si),rs(bp,di),get_(si,1),get_(di,1),get_(bp,1),get_(bx,1)}[r.r_m];
switch(r.mod){ case 0: if (r.r_m==6) R (U)(mem+fetchw()); break;
case 1: x+=fetchb(); break;
case 2: x+=fetchw(); break;
case 3: R decreg(r.r_m,w); }
R (U)(mem+x); }
// opcode helpers
// set d and w from o
#define DW if(trace){ P("%s:\n",__func__); } \
d=!!(o&2); \
w=o&1;
// fetch mrm byte and decode, setting x and y as pointers to args and p ptr to dest
#define RMP rm r=mrm(fetchb());\
x=decreg(r.reg,w); \
y=decrm(r,w); \
if(trace>1){ P("x:%d\n",x); P("y:%d\n",y); } \
p=d?(void*)x:(void*)y;
// fetch x and y values from x and y pointers
#define LDXY \
x=get_((void*)x,w); \
y=get_((void*)y,w); \
if(trace){ P("x:%d\n",x); P("y:%d\n",y); }
// normal mrm decode and load
#define RM RMP LDXY
// immediate to accumulator
#define IA x=(U)(p=w?(UC*)ax:al); \
x=get_((void*)x,w); \
y=w?fetchw():fetchb();
// flags set by logical operators
#define LOGFLAGS *fl=0; \
*fl |= ( (z&(w?0x8000:0x80)) ?SF:0) \
| ( (z&(w?0xffff:0xff))==0 ?ZF:0) ;
// additional flags set by math operators
#define MATHFLAGS *fl |= ( (z&(w?0xffff0000:0xff00)) ?CF:0) \
| ( ((z^x)&(z^y)&(w?0x8000:0x80)) ?OF:0) \
| ( ((x^y^z)&0x10) ?AF:0) ;
// store result to p ptr
#define RESULT \
if(trace)P(w?"->%04x ":"->%02x ",z); \
put_(p,z,w);
// operators, composed with helpers in the opcode table below
// most of these macros will "enter" with x and y already loaded with operands
#define PUSH(x) put_(mem+(*sp-=2),*(x),1)
#define POP(x) *(x)=get_(mem+(*sp+=2)-2,1)
#define ADD z=x+y; LOGFLAGS MATHFLAGS RESULT
#define ADC x+=(*fl&CF); ADD
#define SUB z=d?x-y:y-x; LOGFLAGS MATHFLAGS RESULT
#define SBB d?y+=*fl&CF:(x+=*fl&CF); SUB
#define CMP p=null; SUB
#define AND z=x&y; LOGFLAGS RESULT
#define OR z=x|y; LOGFLAGS RESULT
#define XOR z=x^y; LOGFLAGS RESULT
#define INC(r) w=1; d=1; p=(V*)r; x=(S)*r; y=1; f=*fl&CF; ADD *fl=(*fl&~CF)|f;
#define DEC(r) w=1; d=1; p=(V*)r; x=(S)*r; y=1; f=*fl&CF; SUB *fl=(*fl&~CF)|f;
#define F(f) !!(*fl&f)
#define J(c) U cf=F(CF),of=F(OF),sf=F(SF),zf=F(ZF); y=(S)(C)fetchb(); \
if(trace)P("<%d> ", c); \
if(c)*ip+=(S)y;
#define JN(c) J(!(c))
#define IMM(a,b) rm r=mrm(fetchb()); \
p=(void*)(y=decrm(r,w)); \
a \
x=w?fetchw():fetchb(); \
b \
d=0; \
y=get_((void*)y,w); \
if(trace){ P("x:%d\n",x); P("y:%d\n",y); } \
if(trace){ P("%s ", (C*[]){"ADD","OR","ADC","SBB","AND","SUB","XOR","CMP"}[r.reg]); } \
switch(r.reg){case 0:ADD break; \
case 1:OR break; \
case 2:ADC break; \
case 3:SBB break; \
case 4:AND break; \
case 5:SUB break; \
case 6:XOR break; \
case 7:CMP break; }
#define IMMIS IMM(w=0;,w=1;x=(S)(C)x;)
#define TEST z=x&y; LOGFLAGS MATHFLAGS
#define XCHG f=x;z=y; LDXY if(w){*(US*)f=y;*(US*)z=x;}else{*(UC*)f=y;*(UC*)z=x;}
#define MOV z=d?y:x; RESULT
#define MOVSEG
#define LEA RMP z=((UC*)y)-mem; RESULT
#define NOP
#define AXCH(r) x=(U)ax; y=(U)(r); w=1; XCHG
#define CBW *ax=(S)(C)*al;
#define CWD z=(I)(S)*ax; *dx=z>>16;
#define CALL x=w?fetchw():(S)(C)fetchb(); PUSH(ip); (*ip)+=(S)x;
#define WAIT
#define PUSHF PUSH(fl)
#define POPF POP(fl)
#define SAHF x=*fl; y=*ah; x=(x&~0xff)|y; *fl=x;
#define LAHF *ah=(UC)*fl;
#define mMOV if(d){ x=get_(mem+fetchw(),w); if(w)*ax=x; else*al=x; } \
else { put_(mem+fetchw(),w?*ax:*al,w); }
#define MOVS
#define CMPS
#define STOS
#define LODS
#define SCAS
#define iMOVb(r) (*r)=fetchb();
#define iMOVw(r) (*r)=fetchw();
#define RET(v) POP(ip); if(v)*sp+=v*2;
#define LES
#define LDS
#define iMOVm if(w){iMOVw((US*)y)}else{iMOVb((UC*)y)}
#define fRET(v) POP(cs); RET(v)
#define INT(v)
#define INT0
#define IRET
#define Shift rm r=mrm(fetchb());
#define AAM
#define AAD
#define XLAT
#define ESC(v)
#define LOOPNZ
#define LOOPZ
#define LOOP
#define JCXZ
#define IN
#define OUT
#define INv
#define OUTv
#define JMP x=fetchw(); *ip+=(S)x;
#define sJMP x=(S)(C)fetchb(); *ip+=(S)x;
#define FARJMP
#define LOCK
#define REP
#define REPZ
#define HLT halt=1
#define CMC *fl=(*fl&~CF)|((*fl&CF)^1);
#define NOT
#define NEG
#define MUL
#define IMUL
#define DIV
#define IDIV
#define Grp1 rm r=mrm(fetchb()); \
y=decrm(r,w); \
if(trace)P("%s ", (C*[]){}[r.reg]); \
switch(r.reg){case 0: TEST; break; \
case 2: NOT; break; \
case 3: NEG; break; \
case 4: MUL; break; \
case 5: IMUL; break; \
case 6: DIV; break; \
case 7: IDIV; break; }
#define Grp2 rm r=mrm(fetchb()); \
y=decrm(r,w); \
if(trace)P("%s ", (C*[]){"INC","DEC","CALL","CALL","JMP","JMP","PUSH"}[r.reg]); \
switch(r.reg){case 0: INC((S*)y); break; \
case 1: DEC((S*)y); break; \
case 2: CALL; break; \
case 3: CALL; break; \
case 4: *ip+=(S)y; break; \
case 5: JMP; break; \
case 6: PUSH((S*)y); break; }
#define CLC *fl=*fl&~CF;
#define STC *fl=*fl|CF;
#define CLI
#define STI
#define CLD
#define STD
// opcode table
// An x-macro table of pairs (a, b) where a becomes the name of a void function(void) which
// implements the opcode, and b comprises the body of the function (via further macro expansion)
#define OP(_)\
/*dw:bf wf bt wt */ \
_(addbf, RM ADD) _(addwf, RM ADD) _(addbt, RM ADD) _(addwt, RM ADD) /*00-03*/\
_(addbi, IA ADD) _(addwi, IA ADD) _(pushes, PUSH(es)) _(popes, POP(es)) /*04-07*/\
_(orbf, RM OR) _(orwf, RM OR) _(orbt, RM OR) _(orwt, RM OR) /*08-0b*/\
_(orbi, IA OR) _(orwi, IA OR) _(pushcs, PUSH(cs)) _(nop0, ) /*0c-0f*/\
_(adcbf, RM ADC) _(adcwf, RM ADC) _(adcbt, RM ADC) _(adcwt, RM ADC) /*10-13*/\
_(adcbi, IA ADC) _(adcwi, IA ADC) _(pushss, PUSH(ss)) _(popss, POP(ss)) /*14-17*/\
_(sbbbf, RM SBB) _(sbbwf, RM SBB) _(sbbbt, RM SBB) _(sbbwt, RM SBB) /*18-1b*/\
_(sbbbi, IA SBB) _(sbbwi, IA SBB) _(pushds, PUSH(ds)) _(popds, POP(ds)) /*1c-1f*/\
_(andbf, RM AND) _(andwf, RM AND) _(andbt, RM AND) _(andwt, RM AND) /*20-23*/\
_(andbi, IA AND) _(andwi, IA AND) _(esseg, ) _(daa, ) /*24-27*/\
_(subbf, RM SUB) _(subwf, RM SUB) _(subbt, RM SUB) _(subwt, RM SUB) /*28-2b*/\
_(subbi, IA SUB) _(subwi, IA SUB) _(csseg, ) _(das, ) /*2c-2f*/\
_(xorbf, RM XOR) _(xorwf, RM XOR) _(xorbt, RM XOR) _(xorwt, RM XOR) /*30-33*/\
_(xorbi, IA XOR) _(xorwi, IA XOR) _(ssseg, ) _(aaa, ) /*34-37*/\
_(cmpbf, RM CMP) _(cmpwf, RM CMP) _(cmpbt, RM CMP) _(cmpwt, RM CMP) /*38-3b*/\
_(cmpbi, IA CMP) _(cmpwi, IA CMP) _(dsseg, ) _(aas, ) /*3c-3f*/\
_(incax, INC(ax)) _(inccx, INC(cx)) _(incdx, INC(dx)) _(incbx, INC(bx)) /*40-43*/\
_(incsp, INC(sp)) _(incbp, INC(bp)) _(incsi, INC(si)) _(incdi, INC(di)) /*44-47*/\
_(decax, DEC(ax)) _(deccx, DEC(cx)) _(decdx, DEC(dx)) _(decbx, DEC(bx)) /*48-4b*/\
_(decsp, DEC(sp)) _(decbp, DEC(bp)) _(decsi, DEC(si)) _(decdi, DEC(di)) /*4c-4f*/\
_(pushax, PUSH(ax)) _(pushcx, PUSH(cx)) _(pushdx, PUSH(dx)) _(pushbx, PUSH(bx)) /*50-53*/\
_(pushsp, PUSH(sp)) _(pushbp, PUSH(bp)) _(pushsi, PUSH(si)) _(pushdi, PUSH(di)) /*54-57*/\
_(popax, POP(ax)) _(popcx, POP(cx)) _(popdx, POP(dx)) _(popbx, POP(bx)) /*58-5b*/\
_(popsp, POP(sp)) _(popbp, POP(bp)) _(popsi, POP(si)) _(popdi, POP(di)) /*5c-5f*/\
_(nop1, ) _(nop2, ) _(nop3, ) _(nop4, ) _(nop5, ) _(nop6, ) _(nop7, ) _(nop8, ) /*60-67*/\
_(nop9, ) _(nopA, ) _(nopB, ) _(nopC, ) _(nopD, ) _(nopE, ) _(nopF, ) _(nopG, ) /*68-6f*/\
_(jo, J(of)) _(jno, JN(of)) _(jb, J(cf)) _(jnb, JN(cf)) /*70-73*/\
_(jz, J(zf)) _(jnz, JN(zf)) _(jbe, J(cf|zf)) _(jnbe, JN(cf|zf)) /*74-77*/\
_(js, J(sf)) _(jns, JN(sf)) _(jp, ) _(jnp, ) /*78-7b*/\
_(jl, J(sf^of)) _(jnl_, JN(sf^of)) _(jle, J((sf^of)|zf)) _(jnle,JN((sf^of)|zf))/*7c-7f*/\
_(immb, IMM(,)) _(immw, IMM(,)) _(immb1, IMM(,)) _(immis, IMMIS) /*80-83*/\
_(testb, RM TEST) _(testw, RM TEST) _(xchgb, RMP XCHG) _(xchgw, RMP XCHG) /*84-87*/\
_(movbf, RM MOV) _(movwf, RM MOV) _(movbt, RM MOV) _(movwt, RM MOV) /*88-8b*/\
_(movsegf, RM MOVSEG) _(lea, LEA) _(movsegt, RM MOVSEG) _(poprm,RM POP((US*)p))/*8c-8f*/\
_(nopH, ) _(xchgac, AXCH(cx)) _(xchgad, AXCH(dx)) _(xchgab, AXCH(bx)) /*90-93*/\
_(xchgasp, AXCH(sp)) _(xchabp, AXCH(bp)) _(xchgasi, AXCH(si)) _(xchadi, AXCH(di)) /*94-97*/\
_(cbw, CBW) _(cwd, CWD) _(farcall, ) _(wait, WAIT) /*98-9b*/\
_(pushf, PUSHF) _(popf, POPF) _(sahf, SAHF) _(lahf, LAHF) /*9c-9f*/\
_(movalb, mMOV) _(movaxw, mMOV) _(movbal, mMOV) _(movwax, mMOV) /*a0-a3*/\
_(movsb, MOVS) _(movsw, MOVS) _(cmpsb, CMPS) _(cmpsw, CMPS) /*a4-a7*/\
_(testaib, IA TEST) _(testaiw, IA TEST) _(stosb, STOS) _(stosw, STOS) /*a8-ab*/\
_(lodsb, LODS) _(lodsw, LODS) _(scasb, SCAS) _(scasw, SCAS) /*ac-af*/\
_(movali, iMOVb(al)) _(movcli, iMOVb(cl)) _(movdli, iMOVb(dl)) _(movbli, iMOVb(bl)) /*b0-b3*/\
_(movahi, iMOVb(ah)) _(movchi, iMOVb(ch)) _(movdhi, iMOVb(dh)) _(movbhi, iMOVb(bh)) /*b4-b7*/\
_(movaxi, iMOVw(ax)) _(movcxi, iMOVw(cx)) _(movdxi, iMOVw(dx)) _(movbxi, iMOVw(bx)) /*b8-bb*/\
_(movspi, iMOVw(sp)) _(movbpi, iMOVw(bp)) _(movsii, iMOVw(si)) _(movdii, iMOVw(di)) /*bc-bf*/\
_(nopI, ) _(nopJ, ) _(reti, RET(fetchw())) _(retz, RET(0)) /*c0-c3*/\
_(les, LES) _(lds, LDS) _(movimb, RMP iMOVm) _(movimw, RMP iMOVm) /*c4-c7*/\
_(nopK, ) _(nopL, ) _(freti, fRET(fetchw())) _(fretz, fRET(0)) /*c8-cb*/\
_(int3, INT(3)) _(inti, INT(fetchb())) _(int0, INT(0)) _(iret, IRET) /*cc-cf*/\
_(shiftb, Shift) _(shiftw, Shift) _(shiftbv, Shift) _(shiftwv, Shift) /*d0-d3*/\
_(aam, AAM) _(aad, AAD) _(nopM, ) _(xlat, XLAT) /*d4-d7*/\
_(esc0, ESC(0)) _(esc1, ESC(1)) _(esc2, ESC(2)) _(esc3, ESC(3)) /*d8-db*/\
_(esc4, ESC(4)) _(esc5, ESC(5)) _(esc6, ESC(6)) _(esc7, ESC(7)) /*dc-df*/\
_(loopnz, LOOPNZ) _(loopz, LOOPZ) _(loop, LOOP) _(jcxz, JCXZ) /*e0-e3*/\
_(inb, IN) _(inw, IN) _(outb, OUT) _(outw, OUT) /*e4-e7*/\
_(call, w=1; CALL) _(jmp, JMP) _(farjmp, FARJMP) _(sjmp, sJMP) /*e8-eb*/\
_(invb, INv) _(invw, INv) _(outvb, OUTv) _(outvw, OUTv) /*ec-ef*/\
_(lock, LOCK) _(nopN, ) _(rep, REP) _(repz, REPZ) /*f0-f3*/\
_(hlt, HLT) _(cmc, CMC) _(grp1b, Grp1) _(grp1w, Grp1) /*f4-f7*/\
_(clc, CLC) _(stc, STC) _(cli, CLI) _(sti, STI) /*f8-fb*/\
_(cld, CLD) _(std, STD) _(grp2b, Grp2) _(grp2w, Grp2) /*fc-ff*/
#define OPF(a,b)void a(){DW b;} // generate opcode function
#define OPN(a,b)a, // extract name
OP(OPF)void(*tab[])()={OP(OPN)}; // generate functions, declare and populate fp table with names
V clean(C*s){I i; // replace unprintable characters in 80-byte buffer with spaces
for(i=0;i<80;i++)
if(!isprint(s[i]))
s[i]=' ';
}
V video(){I i; // dump the (cleaned) video memory to the console
C buf[81]="";
if(!trace)P("\e[0;0;f");
for(i=0;i<28;i++)
memcpy(buf, mem+0x8000+i*80, 80),
clean(buf),
P("\n%s",buf);
P("\n");
}
static I ct; // timer memory for period video dump
V run(){while(!halt){if(trace)dump();
if(!ct--){ct=10; video();}
tab[o=fetchb()]();}}
V dbg(){
while(!halt){
C c;
if(!ct--){ct=10; video();}
if(trace)dump();
//scanf("%c", &c);
fgetc(stdin);
//switch(c){
//case '\n':
//case 's':
tab[o=fetchb()]();
//break;
//}
}
}
I load(C*f){struct stat s; FILE*fp; // load a file into memory at address zero
R (fp=fopen(f,"rb"))
&& fstat(fileno(fp),&s) || fread(mem,s.st_size,1,fp); }
I main(I c,C**v){
init();
if(c>1){ // if there's an argument
load(v[1]); // load named file
}
*sp=0x100; // initialize stack pointer
if(debug) dbg(); // if debugging, debug
else run(); // otherwise, just run
video(); // dump final video
R 0;} // remember what R means? cf. line 9
Using macros for the stages of the various operations makes for a very close semantic match to the way the postscript code operates in a purely sequential fashion. For example, the first four opcodes, 0x00-0x03 are all ADD instructions with varying direction (REG -> REG/MOD, REG <- REG/MOD) and byte/word sizes, so they are represented exactly the same in the function table.
_(addbf, RM ADD) _(addwf, RM ADD) _(addbt, RM ADD) _(addwt, RM ADD)
The function table is instantiated with this macro:
OP(OPF)
which applies OPF() to each opcode representation. OPF() is defined as:
#define OPF(a,b)void a(){DW b;} // generate opcode function
So, the first four opcodes expand (once) to:
void addbf(){ DW RM ADD ; }
void addwf(){ DW RM ADD ; }
void addbt(){ DW RM ADD ; }
void addwt(){ DW RM ADD ; }
These functions distinguish themselves by the result of the DW macro which determines direction and byte/word bits straight from the opcode byte. Expanding the body of one of these functions (once) produces:
if(trace){ P("%s:\n",__func__); } // DW: set d and w from o
d=!!(o&2);
w=o&1;
RMP LDXY // RM: normal mrm decode and load
z=x+y; LOGFLAGS MATHFLAGS RESULT // ADD
;
Where the main loop has already set the o variable:
while(!halt){tab[o=fetchb()]();}}
Expanding one more time gives all the "meat" of the opcode:
// DW: set d and w from o
if(trace){ P("%s:\n",__func__); }
d=!!(o&2);
w=o&1;
// RMP: fetch mrm byte and decode, setting x and y as pointers to args and p ptr to dest
rm r=mrm(fetchb());
x=decreg(r.reg,w);
y=decrm(r,w);
if(trace>1){ P("x:%d\n",x); P("y:%d\n",y); }
p=d?(void*)x:(void*)y;
// LDXY: fetch x and y values from x and y pointers
x=get_((void*)x,w);
y=get_((void*)y,w);
if(trace){ P("x:%d\n",x); P("y:%d\n",y); }
z=x+y; // ADD
// LOGFLAGS: flags set by logical operators
*fl=0;
*fl |= ( (z&(w?0x8000:0x80)) ?SF:0)
| ( (z&(w?0xffff:0xff))==0 ?ZF:0) ;
// MATHFLAGS: additional flags set by math operators
*fl |= ( (z&(w?0xffff0000:0xff00)) ?CF:0)
| ( ((z^x)&(z^y)&(w?0x8000:0x80)) ?OF:0)
| ( ((x^y^z)&0x10) ?AF:0) ;
// RESULT: store result to p ptr
if(trace)P(w?"->%04x ":"->%02x ",z);
put_(p,z,w);
;
And the fully-preprocessed function, passed through indent:
void
addbf ()
{
if (trace)
{
printf ("%s:\n", __func__);
}
d = ! !(o & 2);
w = o & 1;
rm r = mrm (fetchb ());
x = decreg (r.reg, w);
y = decrm (r, w);
if (trace > 1)
{
printf ("x:%d\n", x);
printf ("y:%d\n", y);
}
p = d ? (void *) x : (void *) y;
x = get_ ((void *) x, w);
y = get_ ((void *) y, w);
if (trace)
{
printf ("x:%d\n", x);
printf ("y:%d\n", y);
}
z = x + y;
*fl = 0;
*fl |=
((z & (w ? 0x8000 : 0x80)) ? SF : 0) | ((z & (w ? 0xffff : 0xff)) ==
0 ? ZF : 0);
*fl |=
((z & (w ? 0xffff0000 : 0xff00)) ? CF : 0) |
(((z ^ x) & (z ^ y) & (w ? 0x8000 : 0x80)) ? OF : 0) |
(((x ^ y ^ z) & 0x10) ? AF : 0);
if (trace)
printf (w ? "->%04x " : "->%02x ", z);
put_ (p, z, w);;
}
Not the greatest C style for everyday use, but using macros this way seems pretty perfect for making the implementation here very short and very direct.
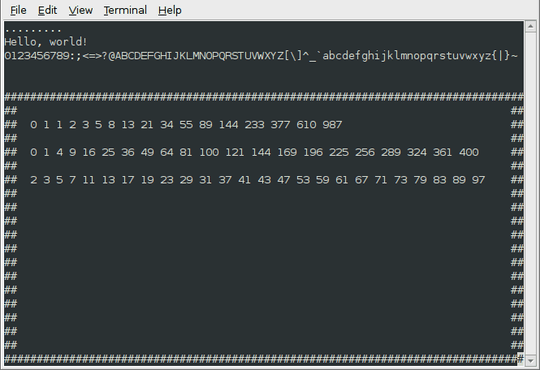
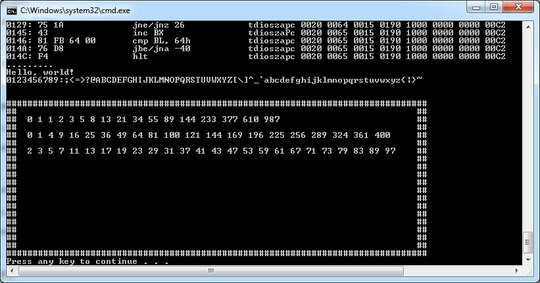
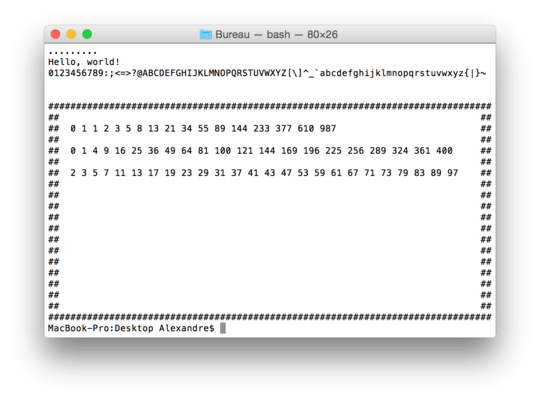
Test program output, with tail of the trace output:
43(103) incbx:
->0065
ax:0020 cx:0015 dx:0190 bx:0065 sp:1000 bp:0000 si:0000 di:00c2 ip:013e fl:0000 NC NO NS NZ
83(203) immis:
fb(373) 64(144) x:100
y:101
CMP ->0001
ax:0020 cx:0015 dx:0190 bx:0065 sp:1000 bp:0000 si:0000 di:00c2 ip:0141 fl:0000 NC NO NS NZ
76(166) jbe:
da(332) <0>
ax:0020 cx:0015 dx:0190 bx:0065 sp:1000 bp:0000 si:0000 di:00c2 ip:0143 fl:0000 NC NO NS NZ
f4(364) hlt:
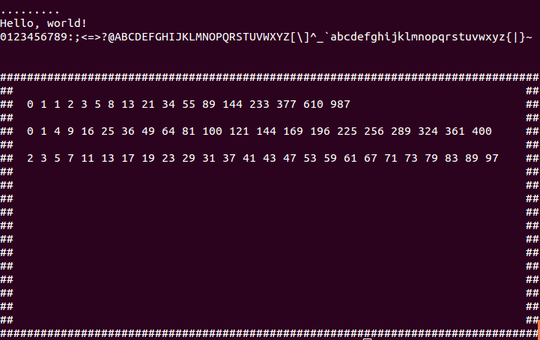
.........
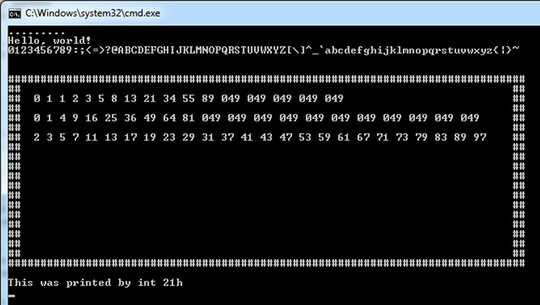
Hello, world!
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
################################################################################
## ##
## 0 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 ##
## ##
## 0 1 4 9 16 25 36 49 64 81 100 121 144 169 196 225 256 289 324 361 400 ##
## ##
## 2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 ##
## ##
## ##
## ##
## ##
## ##
## ##
## ##
## ##
## ##
## ##
## ##
## ##
################################################################################
I shared some earlier versions in comp.lang.c but they weren't very interested.

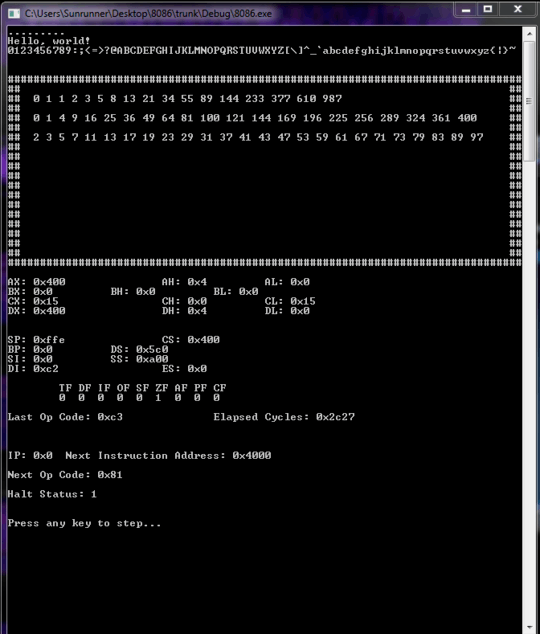
 I included an interactive debugger as well.
I included an interactive debugger as well. 






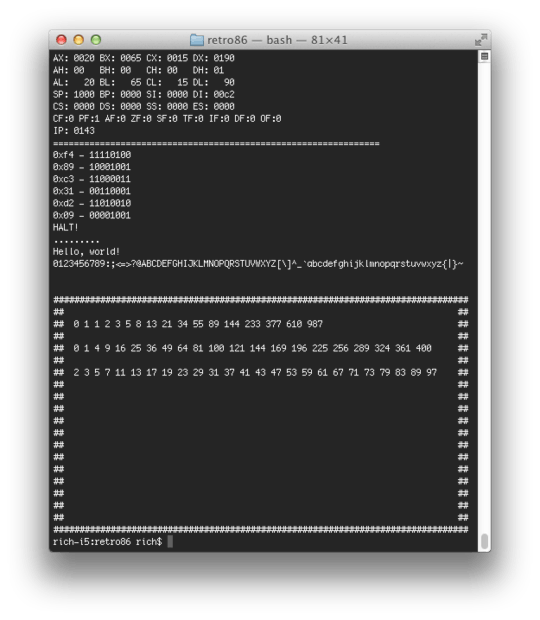









I can never remember whether
push spdecrementsspbefore or after pushing it on the 8086 :( – J B – 2012-01-30T15:42:29.6931@JB remember it's the less intuitive one:
mem[sp - 2] = reg; sp = sp - 2– copy – 2012-01-30T16:12:40.260@copy I'd assume it's out of bounds to your simplified problem, but it really looks as though on the 8086 and 80186 it's the opposite: http://www.ukcpu.net/Programming/Hardware/x86/CPUID/x86-ID.asp
– J B – 2012-01-30T16:35:24.0231@JB wow you're right. I had this in mind from newer x86s but didn't know it had changed some time. Yeah, it really does not make a difference for this challenge, but it's an interesting fact :) – copy – 2012-01-30T16:55:26.993
2+1 +favorite ...i can't begin to express the feeling i got when i saw this question. – ixtmixilix – 2012-02-26T21:33:27.723
2@MartinBüttner Sure, the question is older than that tag and has basically been a popularity contest anyway – copy – 2015-03-21T00:32:37.857
@copy Thank you. And congrats on the gold badge. ;) – Martin Ender – 2015-03-21T01:21:25.820
Hey guys I'm trying this out and having some trouble with the sample program. Not sure if it's me. I'm inputting the sample binary, coming to location 41h. The hex is
72 C3 51 83 E1, which my code correctly interprets asjc hlt, push cx. But83 E1is not valid according to the datasheets. The asm listing file saysand cx, 1, which would be81 E1I believe. Am I missing something here? Can anyone else directly input the binary at the link above? – JoeFish – 2012-11-15T22:02:53.3201@JoeFish nasm has generated some instructions that were added on the 80386.
83is the same opgroup (add, or, ...) as81with a sign-extended single byte immediate (81has a word immediate). Soand cx, 1can be assembled as83 E1 01or81 E1 01 00– copy – 2012-11-15T23:23:02.927If anyone needs it, I've got a Postscript type-3 font of the Code Page 437 at http://code.google.com/p/xpost/downloads/list . It contains the full bitmap in ASCII hex (via
– luser droog – 2012-11-16T04:21:16.497convert png->xbm|vi-hacking).I'm actually looking for some more complete programs to test with. Anyyone have links to early programs or more involved sample code? Almost all of what I've found so far has 80186+ instructions. – JoeFish – 2012-11-28T21:19:58.347
I'm finding copy's test program to be marvellously useful in sniffing out one bug after another. @JoeFish, I assume you've tried porting x86 codegolf answers from elsewhere on this site? If not, there's a start. – luser droog – 2012-11-30T05:56:35.480
2@copy It is never too late to make a golf competition for every single language/host pair – Yauhen Yakimovich – 2012-12-17T00:21:17.703
@YauhenYakimovich my initial thought was that the challenge is too complex and at this point, people might not be interested in golfing their old code. If anyone disagrees, just post your golfed solution and I'll keep track in the original post – copy – 2012-12-22T22:09:00.397
1
Anyone reading this question has probably already seen JSLinux but if not, you'll probably like it: http://bellard.org/jslinux/
– Matt Lyons – 2014-01-01T21:19:43.103One more great resource for the list: Explanation of the Octal nature of the 80x86 encoding
– luser droog – 2018-06-05T06:11:37.6075far too advanced for me, but I'm very eager to see answers to this question as it's precisely the sort of stuff I'm most interested in! I may take a crack at it later if I'm feeling particularly masochistic... – Chris Browne – 2012-01-23T13:17:52.000
3@ChrisBrowne good luck being masochistic! I am currently turning my 8086 into a 80386 and have learned a lot from this project so far. – copy – 2012-01-23T17:24:42.403
Aarghh, very intriguing question (and very well scoped imo). I might pick up the challenge but I'm afraid it will be a great time sink ;-) – ChristopheD – 2012-01-25T21:03:37.083