33
3
Introduction
A229037 has a quite intriguing plot (at least for the first few terms):
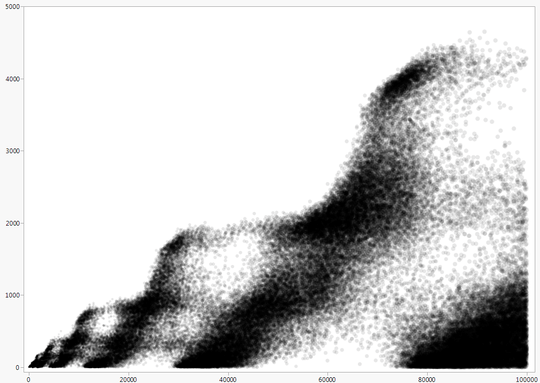
There is the conjecture, that it might indeed have some kind of fractal property.
How is this sequence constructed?
Define a(1) = 1, a(2) = 1 then for each n>2 find a minimal positive integer a(n) such that for every arithmetic 3 term sequence n,n+k,n+2k of indices, the corresponding values of the sequence a(n),a(n+k),a(n+2k) is not an arithmetic sequence.
Challenge
Given a positive integer n as an input, output the first n terms a(1), ... , a(n) of this sequence. (With any reasonable formatting. Possible leading/trainling characters/strings are irrelevant.)
There are snippets for generating this sequence available, but I think other approaches might be more golfable/more suitable for certain languages.
Please let us know how your progrm works. If you come a cross a particularly efficient algorithm you might want to mention that too, as it would allow to plot more terms of the sequence in shorter time.
First few test cases:
1, 1, 2, 1, 1, 2, 2, 4, 4, 1, 1, 2, 1, 1, 2, 2, 4, 4, 2, 4, 4, 5, 5, 8, 5, 5, 9, 1, 1, 2, 1, 1, 2, 2, 4, 4, 1, 1, 2, 1, 1, 2, 2, 4, 4, 2, 4, 4, 5, 5, 8, 5, 5, 9, 9, 4, 4, 5, 5, 10, 5, 5, 10, 2, 10, 13, 11, 10, 8, 11, 13, 10, 12, 10, 10, 12, 10, 11, 14, 20, 13
More testcases:
a(100) = 4
a(500) = 5
a(1000) = 55
a(5000) = 15
a(10000) = 585
All terms up to n=100000 are available here: https://oeis.org/A229037/b229037.txt
Thanks @MartinBüttner for the help and encouragement.

flawr
Posted 2016-01-12T18:44:30.810
Reputation: 40 560








2Hey, where have I seen this graph before? :-D – Luis Mendo – 2016-01-12T19:01:53.107
12Shift your head somewhat to the left, zoom in a bit, there you go! (: – flawr – 2016-01-12T19:05:50.670
4
A numberphile video just popped up: https://www.youtube.com/watch?v=o8c4uYnnNnc
– flawr – 2019-08-14T19:05:17.7032I bet his code is not nearly as golfy! – Luis Mendo – 2019-08-14T20:18:27.440