Unseen species problem
The unseen species problem is commonly referred to in ecology and deals with the estimation of the number of species represented in an ecosystem that were not observed by samples. It more specifically relates to how many new species would be discovered if more samples were taken in an ecosystem. The study of the unseen species problem was started in the early 1940s by Alexander Steven Corbet. He spent 2 years in British Malaya trapping butterflies and was curious how many new species he would discover if he spent another 2 years trapping. Many different estimation methods have been developed to determine how many new species would be discovered given more samples. The unseen species problem also applies more broadly, as the estimators can be used to estimate any new elements of a set not previously found in samples. An example of this is determining how many words William Shakespeare knew based on all of his written works. The unseen species problem can be broken down mathematically as follows:
If independent samples are taken, , and then if more independent samples were taken, the number of unseen species that will be discovered by the additional samples is given by




with being the second set of samples.


History
In the early 1940s Alexander Steven Corbet spent 2 years in British Malaya trapping butterflies.[1] He kept track of how many species he observed, and how many members of each species were captured. For example, he captured only 2 members of 74 different species. When he returned to the United Kingdom, he approached statistician Ronald Fisher, and asked how many new species of butterflies he could expect to catch if he went trapping for another two years.[2] In essence, Corbet was asking how many species he observed zero times. Fisher responded with a simple estimation: for an additional 2 years of trapping, Corbet could expect to capture 75 new species. He did this using a simple summation (data provided by Orlitsky[2] in Table 1 below in the Example section):

Here, corresponds to the number of individual species which were observed times. Fisher's sum was later confirmed by Good–Toulmin.[1]


Estimators
To estimate the number of unseen species, let be number of future samples () divided by the number of past samples (), or . Let be the number of individual species observed times (for example, if there were 74 species of butterflies with 2 observed members throughout the samples, then ).






The Good–Toulmin estimator
The Good–Toulmin estimator was developed by I. J. Good and G. H. Toulmin in 1953.[3] The estimate of the unseen species based on the Good–Toulmin estimator is given by

The Good–Toulmin Estimator has been shown to be a good estimate for values of . The Good–Toulmin estimator also approximates that


This means that estimates to within as long as . However, for , the Good–Toulmin estimator fails to capture accurate results. This is because, if , increases by for with , meaning that if , grows super-linearly in , but can grow at most linearly with . Therefore, when , grows faster than and does not approximate the true value.[2] To compensate for this, Efron and Thisted[4] showed that a truncated Euler transform can also be a usable estimate:










with

and

where is the location chosen to truncate the Euler transform.

The smoothed Good–Toulmin estimator
Similar to the approach by Efron and Thisted, Alon Orlitsky, Ananda Theertha Suresh, and Yihong Wu developed the smooth Good–Toulmin estimator. They realized that the Good–Toulmin estimator failed for because of the exponential growth, and not its bias.[2] Therefore, they estimated the number of unseen species by truncating the series.

Orlitsky, Suresh, and Wu also noted that for distributions with , the driving term in the summation estimate is the term, regardless of which value of is chosen.[1] To solve this, they elected a random nonnegative integer , truncated the series at , and then took the average over a distribution about .[2] The resulting estimator is




This method was chosen because the bias of shifts signs due to the coefficient. Averaging over a distribution of therefore reduces the bias. This means that the estimator can be written as the linear combination of the prevalence:[1]



Depending on the distribution of chosen, the results will vary. With this method, estimates can be made for , and this is the best possible.[2]

Species discovery curve
The species discovery curve can also be used. This curve relates the number of species found in an area as a function of the time. These curves can also be created by using estimators (such as the Good–Toulmin estimator) and plotting the number of unseen species at each value for .[5]
A species discovery curve is always increasing, as there is never a sample that could decrease the number of discovered species. Furthermore, the species discovery curve is also decelerating; the more samples taken, the fewer unseen species are expected to be discovered. The species discovery curve will also never asymptote, as it is assumed that although the discovery rate might become infinitely slow, it will never actually stop.[5] Two common models for a species discovery curve are the logarithmic and the exponential function.
Example – Corbet's butterflies
As an example, consider the data Corbet provided Fisher in the 1940s.[2] Using the Good–Toulmin model, the number of unseen species is found using

This can then be used to create a relationship between and .
| Number of observed members, | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Number of species, | 118 | 74 | 44 | 24 | 29 | 22 | 20 | 19 | 20 | 15 | 12 | 14 | 6 | 12 | 6 |
This relationship is shown in the plot below.
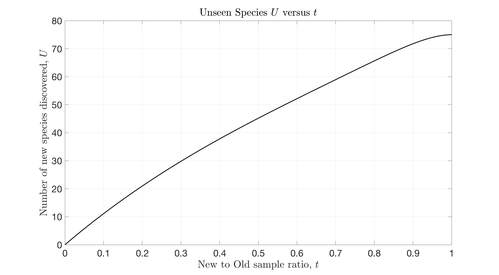
From the plot, it is seen that at , which was the value of that Corbet brought to Fisher, the resulting estimate of is 75, matching what Fisher found. This plot also acts as a species discovery curve for this ecosystem, and defines how many new species will be discovered as increases (and more samples are taken).

Other uses
There are numerous uses for the predictive algorithm. Knowing that the estimators are accurate, it allows scientists to extrapolate accurately the results of polling people by a factor of 2. They can predict the number of unique answers based on the number of people that have answered similarly. The method can also be used to determine the extent of someone's knowledge. A prime example is determining how many unique words Shakespeare knew based on the written works we have today.
Example – How many words did Shakespeare know?
Based on research done by Thisted and Efron, of Shakespeare's known works, there are 884,647 total words.[4] The research also found that there are at total of different words that appear more than 100 times. Therefore, the total number of unique words was found to be 31,534.[4] Applying the Good–Toulmin model, if an equal number of works by Shakespeare were discovered, then it is estimated that unique words would be found. The goal would be to derive for . Thisted and Efron estimate that , meaning that Shakespeare most likely knew over twice as many words as he actually used in all of his writings.[4]





References
- Orlitsky, Alon; Suresh, Ananda Theertha; Wu, Yihong (2016-11-22). "Optimal prediction of the number of unseen species". Proceedings of the National Academy of Sciences. 113 (47): 13283–13288. doi:10.1073/pnas.1607774113. PMC 5127330. PMID 27830649.
- Orlitsky, Alon; Suresh, Ananda Theertha; Wu, Yihong (2015-11-23). "Estimating the number of unseen species: A bird in the hand is worth log n in the bush". arXiv:1511.07428 [math.ST].
- GOOD, I. J.; TOULMIN, G. H. (1956). "The Number of New Species, and the Increase in Population Coverage, when a Sample is Increased". Biometrika. 43 (1–2): 45–63. doi:10.1093/biomet/43.1-2.45. ISSN 0006-3444.
- Efron, Bradley; Thisted, Ronald (1976). "Estimating the Number of Unsen Species: How Many Words Did Shakespeare Know?". Biometrika. 63 (3): 435–447. doi:10.2307/2335721. JSTOR 2335721.
- Bebber, D. P; Marriott, F. H.C; Gaston, K. J; Harris, S. A; Scotland, R. W (7 July 2007). "Predicting unknown species numbers using discovery curves". Proceedings of the Royal Society B: Biological Sciences. 274 (1618): 1651–1658. doi:10.1098/rspb.2007.0464. PMC 2169286. PMID 17456460.