Test generation
Test generation is the process of creating a set of test data or test cases for testing the adequacy of new or revised software applications. Test Generation is seen to be a complex problem and though a lot of solutions have come forth most of them are limited to toy programs. Test Generation is one aspect of software testing. Since testing is labor-intensive, accounting for nearly one third of the cost of the system development, the problem of generating quality test data quickly, efficiently and accurately is seen to be important.[1]
Basic concepts
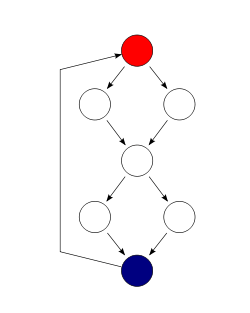
Mathematical modelling
A program P could be considered as a function, P:S → R, where S is the set of all possible inputs and R the set of all possible outputs. An input variable of function P is mapped to an input parameter of P. P(x) denotes execution of program for certain input x.[1][2]
Control flow graph
A Control Flow Graph of a program P is a directed graph G = (N, E, s, e) consisting of a set of nodes N and a set of edges E = {(n, m)|n, m ∈ N } connecting the nodes.[1][2]
Each node denotes a basic block which itself is a sequence of instructions. It is important to note that in every basic block the control enters through the entry node and leaves at the end without stopping or branching except at the end. Basically, a block is always executed as a whole. The entry and exit nodes are two special nodes denoted by s and e respectively.
An edge in a control flow graph represents possible transfer of control. All edges have associated with them a condition or a branch predicate. The branch predicate might be the empty predicate which is always true. In order to traverse the edge the condition of the edge must hold. If a node has more than one outgoing edge the node is a condition and the edges are called branches.
A model
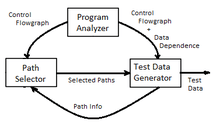
A Test Data Generator follows the following steps
- Program Control Flow Graph Construction
- Path Selection
- Generating Test Data
The basis of the Generator is simple. The path selector identifies the paths. Once a set of test paths is determined the test generator derives input data for every path that results in the execution of the selected path. Essentially, our aim is to find an input data set that will traverse the path chosen by the path selector. This is done in two steps:
- Find the path predicate for the path
- Solve the path predicate
The solution will ideally be a system of equations which will describe the nature of input data so as to traverse the path. In some cases the generator provides the selector with feedback concerning paths which are infeasible etc.[2]
Test data generators
Based on the Mathematical Modelling above we can simply state the Test Data Generator Problem as: Given a program P and a path u, generate input x ∈ S, so that x traverses path u.
Random test data generators
Random test data generation is probably the simplest method for generation of test data. The advantage of this is that it can be used to generate input for any type of program. Thus to generate test data we can randomly generate a bit stream and let it represent the data type needed. However, random test data generation does not generate quality test data as it does not perform well in terms of coverage. Since the data generated is based solely on probability it cannot accomplish high coverage as the chances of it finding semantically small faults is quite low.[3]
If a fault is only revealed by a small percentage of the program input it is said to be a semantically small fault. For an example of a semantically small fault consider the following code:
void test(char x, char y) {
if (x == y)
printf("Equal");
else
printf("Not Equal");
}
It is easy to see that the probability of execution of the first statement is significantly lesser than that of the second statement. As the structures in it grow complex so does the probability of its execution. Thus, such semantically small faults are hard to find using random test data generation.
However, Random Test Data Generation is usually used as a benchmark as it has the lowest acceptable rate of generating test data.
Goal-oriented test data generators
The Goal-Oriented approach provides a guidance towards a certain set of paths. The Test Data Generators in this approach generate an input for any path u instead of the usual approach of generating input from the entry to the exit of a block of code. Thus, the generator can find any input for any path p which is a subset of the path u. This drastically reduces the risk of generating relatively infeasible paths and provides a way to direct the search. Two methods follow this technique:
- The Chaining approach
- Assertion-oriented approach.
Chaining approach
The chaining approach is an extension of the goal-oriented approach. It is seen that the main limitation of the test data generation methods is that only the control flow graph is used to generate the test data. This limited knowledge may make our selection harder. Thus, it is seen that the path-oriented approach usually has to generate a large number of paths before it finds the "right" path. This is because the path selection is blind.[4] The chaining approach tries to identify a chain of nodes that are vital to the execution of the goal node. The chaining approach starts by executing for any arbitrary input x. The search program, during the execution of each branch decides whether to continue execution through this branch or if an alternative branch be taken because the current branch does not lead to the goal node. If it is observed that execution flow is undesirable then search algorithms are used to automatically find new input to change the flow execution. However, if for this point also the search process cannot find input X to change the flow of execution then the chaining approach attempts to alter the flow at node p due to which an alternative branch at p can be executed.[4][5]
Assertion-oriented approach
The assertion-oriented approach is an extension of the chaining approach. In this approach assertions - that is constraint conditions are inserted. This can be done either manually or automatically. If the program doesn't hold on execution there is an error in the program or the assertion.
When an assertion is executed it must hold, otherwise there is an error either in the program or in the assertion. Suppose we have a code as follows:
void test(int a) {
int b, c
b = a-1;
assertion(b != 0);
c = (1/b);
}
In the above code, the program should hold at the assertion statement. If the assertion does not hold it means that the path followed leads to an error. Thus, the goal of this approach is to find any path to an assertion that does not hold. The other major advantage of this approach is that all the other methods expects the value of an execution of the generated test data to be calculated from some other source than the code. However, in this approach it is not necessary since expected value is provided with the assertion.
Pathwise test data generators
Pathwise Test Data Generation is considered to be one of the best approaches to Test Data Generation. This approach does not give the generator the choice of selecting between multiple paths but just gives it one specific path for it to work on. Hence, the name Pathwise Test Data Generator. Thus, except for the fact that this method uses specific paths it is quite similar to Goal-Oriented test data generation. The use of specific paths leads to a better knowledge and prediction of coverage. However, this also makes it harder to generate the needed test data.
Pathwise test data generators require two inputs from the user:
- The program to be tested
- Testing criterion (e.g.: path coverage, statement coverage etc.)
If systems are solely based on the control flow graph to select specific paths it more often than not leads to the selection of infeasible paths. In view of this mechanisms have been proposed for a constraint based test data generation.[6] These mechanisms focuses on fault-based testing introducing deliberate changes in the code. These deliberate changes are called as "mutants" and this type of testing called as Mutation Testing.
Intelligent test data generators
Intelligent Test Data Generators depend on sophisticated analysis of the code to guide the search of the test data. Intelligent Test Data Generators are essentially utilize one of the test data generation method coupled with the detailed analysis of the code. This approach may generate test data quicker than the other approaches but the analysis required for the utilization of this approach over a wide variety of programs is quite complex and requires a great deal of insight to anticipate the different situations that may arise.[7][8] There are open-source packages for this such as DataGenerator.[9]
Chaotic data generators
Chaotic Data Generators generate data from a chaotic attractor. The chaotic attractor generates non-repeating data, and a small change in initial conditions in the attractor may cause a large change later in data generated.[10]
Hypermedia generators
Hypermedia Generators generate hypertext, hypervolumes, and hypermovies.
Quantum data generators
A Quantum Data Generator generates qubits according to some other data generator. In this case, qubits are the data.
Test assertion generators
Once we have some test data, one needs a test oracle to assess the behavior of the program under test for the given test input. There are different kinds of oracles that can be used.[11]
One can also improve the assertions for existing test data. For instance, one can generate and add new assertions in existing test cases. This is what the DSpot system does in the context of the Java programming language: it does dynamic analysis of JUnit test cases and generate missing assertions.[12]
Test case generators
While test data generators generate only inputs, test case generators synthesize full test cases. For example, in an object-oriented language, a test case contains object creations and method calls. When one maximizes coverage, the generated test cases have no assertion.
// Example of generated test case that covers the constructor and two methods.
@Test
void generatedJunitTest() {
Account b = new BankAccount(0);
b.deposit(7);
b.withdraw(3);
}
To add assertions in the generated test cases, one must have a test oracle. For instance, one can use a reference implementation has oracle. Then, the expected value of the generated assertions is the actual value returned by the reference implementation.
@Test
void generatedJunitTest() {
Account b = new BankAccount(0);
b.deposit(7);
b.withdraw(3);
assertEquals(4, b.getAmount());
}
EvoSuite is an example of such a test case generator for Java.
Problems of test generation
Test generation is highly complex. The use of dynamic memory allocation in most of the code written in industry is the most severe problem that the Test Data Generators face as the usage of the software then becomes highly unpredictable, due to this it becomes harder to anticipate the paths that the program could take making it nearly impossible for the Test Data Generators to generate exhaustive Test Data. However, in the past decade significant progress has been made in tackling this problem better by the use of genetic algorithms and other analysis algorithms. The following are problem areas that are encountered while implementing the test data generation techniques for actual industry used code.[2]
Arrays and pointers
Arrays and Pointers can be considered to have similar constructs and also suffer from the same kind of problems. Arrays and pointers create problems during symbolic execution as it complicates the substitution since their values are not known. Also, in order to generate input for arrays and pointers there are multiple problems like the index of the array, or the structure of the input that needs to be given to the pointer. This is further compounded by the possibility of dynamic allocation of arrays and pointers.
Objects
Objects due to its dynamic nature pose a problem for generation. This is further compounded by the use of other object oriented features. All of this makes it hard to determine which code will be called at runtime. An attempt has been made to address the problem of Object Oriented Code by use of mutation.[13]
Loops
Loops that vary their behaviour depending on the input variables are potentially problematic as it is difficult to anticipate the path that could be taken. However, if the given path is specific, that is it doesn't change behaviour the loops cause no problem. There are a few techniques that have been suggested to solve this potential problem with loops.[14]
Modules
A program usually consists of modules which then itself consists of functions. Two solutions have been proposed for generating test data for such functions:[14]
- Brute Force Solution This is done by inlining the called functions into the target
- Analyzing the Called Functions Analyze the called functions first and generate path predicates for those functions.
However, often source code of the modules is not accessible and hence a complete static analysis is not always possible.
Infeasible paths
To generate test data so as to traverse a path involves solving a system of equations. If there are no solutions then the path given is infeasible. However, in this we are limited by the problem of undecidable nature of the system of equations. The most common method adopted is to set a highest number of iterations to be done before declaring the path as in-feasible.
Constraint satisfaction
Constraint satisfaction as the name suggests is the process of finding a solution that conforms to a set of constraints that the variables must satisfy. A solution is therefore a vector of variables that satisfies all constraints. Constraint satisfaction is a difficult problem to solve and hence is not usually properly implemented. All the programs need to satisfy some constraint in some way or the other. There have been many methods like iterative relaxation, genetic algorithms etc. which allow to solve for constraints.[6] [7]
Readability of generated tests
One of challenges of test generation is readability: when the generated tests are meant to be committed to the test suite, developers have been able to easily understand the generated test cases. However, generated test cases often contain obscure generated variable names. [15] One way to overcome this problem is that, instead of generating new tests, to improve existing tests already written by humans, this is known as test amplification.[16]
See also
- Software Testing
- Test Plan
- Test Suite
- Test Data
- Fuzzing
References
- Korel, Bogdan (August 1990). "Automated Software Test Data Generation". IEEE Transactions on Software Engineering. 16 (8): 870–879. CiteSeerX 10.1.1.121.8803. doi:10.1109/32.57624.
- Edvardsson, Jon (October 1999). "A Survey on Automatic Test Data Generation". Proceedings of the Second Conference on Computer Science and Engineering in Linkoping. CiteSeerX 10.1.1.20.963.
- Offutt, J.; J. Hayes (1996). "A Semantic Model of Program Faults". International Symposium on Software Testing and Analysis. CiteSeerX 10.1.1.134.9338.
- Korel, Bogdan (1990). "A Dynamic Approach of Automated Test Data Generation". Conference on Software Maintenance.
- Ferguson, Roger; Bogdan Korel (1996). "The Chaining Approach for Software Test Data Generation" (PDF). ACM.
- DeMillo, R.A.; Offutt A.J. (September 1991). "Constraint-based automatic test data generation". IEEE Transactions on Software Engineering. 19 (6): 640. CiteSeerX 10.1.1.91.1702. doi:10.1109/32.232028.
- Pargas, Roy; Harrold, Mary; Peck, Robert (1999). "Test Data Generation using Genetic Algorithms" (PDF). Journal of Software Testing, Verification and Reliability. 9 (4): 263–282. CiteSeerX 10.1.1.33.7219. doi:10.1002/(sici)1099-1689(199912)9:4<263::aid-stvr190>3.0.co;2-y.
- Michael, C.C.; McGraw, G.E.; Schatz, M.A.; Walton, C.C. (1997). "Genetic algorithms for dynamic test data generation". Proceedings 12th IEEE International Conference Automated Software Engineering. pp. 307–308. CiteSeerX 10.1.1.50.3866. doi:10.1109/ASE.1997.632858. ISBN 978-0-8186-7961-2.
- "The DataGenerator". finraos.github.io. Retrieved 2019-09-01.
- "Chaos Data Generator".
- Barr, Earl T.; Harman, Mark; McMinn, Phil; Shahbaz, Muzammil; Yoo, Shin (2015-05-01). "The Oracle Problem in Software Testing: A Survey". IEEE Transactions on Software Engineering. 41 (5): 507–525. doi:10.1109/TSE.2014.2372785. ISSN 0098-5589.
- Danglot, Benjamin; Vera-Pérez, Oscar Luis; Baudry, Benoit; Monperrus, Martin (2019). "Automatic test improvement with DSpot: a study with ten mature open-source projects". Empirical Software Engineering. 24 (4): 2603–2635. arXiv:1811.08330. doi:10.1007/s10664-019-09692-y. ISSN 1573-7616.
- Seater, Robert; Gregory Dennis. "Automated Test Data Generation with SAT" (PDF). Cite journal requires
|journal=(help) - Ramamoorthy, C. V.; S. F. Ho; W. T. Chen (December 1976). "On the Automated Generation of Program Test Data". IEEE Transactions on Software Engineering. SE-2 (4): 293–300. doi:10.1109/tse.1976.233835.
- Grano, Giovanni; Scalabrino, Simone; Gall, Harald C.; Oliveto, Rocco (2018). "An empirical investigation on the readability of manual and generated test cases" (PDF). Proceedings of the 26th Conference on Program Comprehension - ICPC '18. pp. 348–351. doi:10.1145/3196321.3196363. ISBN 9781450357142.
- Danglot, Benjamin; Vera-Perez, Oscar; Yu, Zhongxing; Zaidman, Andy; Monperrus, Martin; Baudry, Benoit (2019). "A snowballing literature study on test amplification". Journal of Systems and Software. 157: 110398. arXiv:1705.10692. doi:10.1016/j.jss.2019.110398.