Quantile
In statistics and probability, quantiles are cut points dividing the range of a probability distribution into continuous intervals with equal probabilities, or dividing the observations in a sample in the same way. There is one fewer quantile than the number of groups created. Thus quartiles are the three cut points that will divide a dataset into four equal-sized groups. Common quantiles have special names: for instance quartile, decile (creating 10 groups: see below for more). The groups created are termed halves, thirds, quarters, etc., though sometimes the terms for the quantile are used for the groups created, rather than for the cut points.
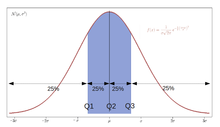
q-quantiles are values that partition a finite set of values into q subsets of (nearly) equal sizes. There are q − 1 of the q-quantiles, one for each integer k satisfying 0 < k < q. In some cases the value of a quantile may not be uniquely determined, as can be the case for the median (2-quantile) of a uniform probability distribution on a set of even size. Quantiles can also be applied to continuous distributions, providing a way to generalize rank statistics to continuous variables (see percentile rank). When the cumulative distribution function of a random variable is known, the q-quantiles are the application of the quantile function (the inverse function of the cumulative distribution function) to the values {1/q, 2/q, …, (q − 1)/q}.
Specialized quantiles
Some q-quantiles have special names:
- The only 2-quantile is called the median
- The 3-quantiles are called tertiles or terciles → T
- The 4-quantiles are called quartiles → Q; the difference between upper and lower quartiles is also called the interquartile range, midspread or middle fifty → IQR = Q3 − Q1
- The 5-quantiles are called quintiles → QU
- The 6-quantiles are called sextiles → S
- The 7-quantiles are called septiles
- The 8-quantiles are called octiles
- The 10-quantiles are called deciles → D
- The 12-quantiles are called duo-deciles or dodeciles
- The 16-quantiles are called hexadeciles → H
- The 20-quantiles are called ventiles, vigintiles, or demi-deciles → V
- The 100-quantiles are called percentiles → P
- The 1000-quantiles have been called permilles or milliles, but these are rare and largely obsolete[1]
Quantiles of a population
As in the computation of, for example, standard deviation, the estimation of a quantile depends upon whether one is operating with a statistical population or with a sample drawn from it. For a population, of discrete values or for a continuous population density, the k-th q-quantile is the data value where the cumulative distribution function crosses k/q. That is, x is a k-th q-quantile for a variable X if
- Pr[X < x] ≤ k/q or, equivalently, Pr[X ≥ x] ≥ 1 − k/q
and
- Pr[X ≤ x] ≥ k/q and Pr[X ≥ x] ≥ k/q.
For a finite population of N equally probable values indexed 1, …, N from lowest to highest, the k-th q-quantile of this population can equivalently be computed via the value of Ip = N k/q. If Ip is not an integer, then round up to the next integer to get the appropriate index; the corresponding data value is the k-th q-quantile. On the other hand, if Ip is an integer then any number from the data value at that index to the data value of the next can be taken as the quantile, and it is conventional (though arbitrary) to take the average of those two values (see Estimating quantiles from a sample).
If, instead of using integers k and q, the “p-quantile” is based on a real number p with 0 < p < 1 then p replaces k/q in the above formulas. Some software programs (including Microsoft Excel) regard the minimum and maximum as the 0th and 100th percentile, respectively; however, such terminology is an extension beyond traditional statistics definitions.
Examples
The following two examples use the Nearest Rank definition of quantile with rounding. For an explanation of this definition, see percentiles.
Even-sized population
Consider an ordered population of 10 data values {3, 6, 7, 8, 8, 10, 13, 15, 16, 20}. What are the 4-quantiles (the "quartiles") of this dataset?
| Quartile | Calculation | Result |
|---|---|---|
| Zeroth quartile | Although not universally accepted, one can also speak of the zeroth quartile. This is the minimum value of the set, so the zeroth quartile in this example would be 3. | 3 |
| First quartile | The rank of the first quartile is 10×(1/4) = 2.5, which rounds up to 3, meaning that 3 is the rank in the population (from least to greatest values) at which approximately 1/4 of the values are less than the value of the first quartile. The third value in the population is 7. | 7 |
| Second quartile | The rank of the second quartile (same as the median) is 10×(2/4) = 5, which is an integer, while the number of values (10) is an even number, so the average of both the fifth and sixth values is taken—that is (8+10)/2 = 9, though any value from 8 through to 10 could be taken to be the median. | 9 |
| Third quartile | The rank of the third quartile is 10×(3/4) = 7.5, which rounds up to 8. The eighth value in the population is 15. | 15 |
| Fourth quartile | Although not universally accepted, one can also speak of the fourth quartile. This is the maximum value of the set, so the fourth quartile in this example would be 20. Under the Nearest Rank definition of quantile, the rank of the fourth quartile is the rank of the biggest number, so the rank of the fourth quartile would be 10. | 20 |
So the first, second and third 4-quantiles (the "quartiles") of the dataset {3, 6, 7, 8, 8, 10, 13, 15, 16, 20} are {7, 9, 15}. If also required, the zeroth quartile is 3 and the fourth quartile is 20.
Odd-sized population
Consider an ordered population of 11 data values {3, 6, 7, 8, 8, 9, 10, 13, 15, 16, 20}. What are the 4-quantiles (the "quartiles") of this dataset?
| Quartile | Calculation | Result |
|---|---|---|
| Zeroth quartile | Although not universally accepted, one can also speak of the zeroth quartile. This is the minimum value of the set, so the zeroth quartile in this example would be 3. | 3 |
| First quartile | The first quartile is determined by 11×(1/4) = 2.75, which rounds up to 3, meaning that 3 is the rank in the population (from least to greatest values) at which approximately 1/4 of the values are less than the value of the first quartile. The third value in the population is 7. | 7 |
| Second quartile | The second quartile value (same as the median) is determined by 11×(2/4) = 5.5, which rounds up to 6. Therefore, 6 is the rank in the population (from least to greatest values) at which approximately 2/4 of the values are less than the value of the second quartile (or median). The sixth value in the population is 9. | 9 |
| Third quartile | The third quartile value for the original example above is determined by 11×(3/4) = 8.25, which rounds up to 9. The ninth value in the population is 15. | 15 |
| Fourth quartile | Although not universally accepted, one can also speak of the fourth quartile. This is the maximum value of the set, so the fourth quartile in this example would be 20. Under the Nearest Rank definition of quantile, the rank of the fourth quartile is the rank of the biggest number, so the rank of the fourth quartile would be 11. | 20 |
So the first, second and third 4-quantiles (the "quartiles") of the dataset {3, 6, 7, 8, 8, 9, 10, 13, 15, 16, 20} are {7, 9, 15}. If also required, the zeroth quartile is 3 and the fourth quartile is 20.
Estimating quantiles from a sample
The asymptotic distribution of -th sample quantile is well-known: it is asymptotically normal around the -th quantile with variance equal to


where is the value of the distribution density at the -th quantile.[2] However, this distribution relies on knowledge of the population distribution; which is equivalent to knowledge of the population quantiles, which we are trying to estimate! Modern statistical packages thus rely on a different technique — or selection of techniques — to estimate the quantiles.[3]

Mathematica,[4] Matlab,[5] R[6] and GNU Octave[7] programming languages include nine sample quantile methods. SAS includes five sample quantile methods, SciPy[8] and Maple[9] both include eight, EViews[10] includes the six piecewise linear functions, Stata[11] includes two, Python[12] includes two, and Microsoft Excel includes two. Mathematica supports an arbitrary parameter for methods that allows for other, non-standard, methods.
In effect, the methods compute Qp, the estimate for the k-th q-quantile, where p = k/q, from a sample of size N by computing a real valued index h. When h is an integer, the h-th smallest of the N values, xh, is the quantile estimate. Otherwise a rounding or interpolation scheme is used to compute the quantile estimate from h, x⌊h⌋, and x⌈h⌉. (For notation, see floor and ceiling functions).
The estimate types and interpolation schemes used include:
| Type | h | Qp | Notes |
|---|---|---|---|
| R-1, SAS-3, Maple-1 | Np + 1/2 | x⌈h – 1/2⌉ | Inverse of empirical distribution function. |
| R-2, SAS-5, Maple-2, Stata | Np + 1/2 | (x⌈h – 1/2⌉ + x⌊h + 1/2⌋) / 2 | The same as R-1, but with averaging at discontinuities. |
| R-3, SAS-2 | Np | x⌊h⌉ | The observation numbered closest to Np. Here, ⌊h⌉ indicates rounding to the nearest integer, choosing the even integer in the case of a tie. |
| R-4, SAS-1, SciPy-(0,1), Maple-3 | Np | x⌊h⌋ + (h − ⌊h⌋) (x⌊h⌋ + 1 − x⌊h⌋) | Linear interpolation of the empirical distribution function. |
| R-5, SciPy-(.5,.5), Maple-4 | Np + 1/2 | x⌊h⌋ + (h − ⌊h⌋) (x⌊h⌋ + 1 − x⌊h⌋) | Piecewise linear function where the knots are the values midway through the steps of the empirical distribution function. |
| R-6, Excel, Python, SAS-4, SciPy-(0,0), Maple-5, Stata-altdef | (N + 1)p | x⌊h⌋ + (h − ⌊h⌋) (x⌊h⌋ + 1 − x⌊h⌋) | Linear interpolation of the expectations for the order statistics for the uniform distribution on [0,1]. That is, it is the linear interpolation between points (ph, xh), where ph = h/(N+1) is the probability that the last of (N+1) randomly drawn values will not exceed the h-th smallest of the first N randomly drawn values. |
| R-7, Excel, Python, SciPy-(1,1), Maple-6, NumPy, Julia | (N − 1)p + 1 | x⌊h⌋ + (h − ⌊h⌋) (x⌊h⌋ + 1 − x⌊h⌋) | Linear interpolation of the modes for the order statistics for the uniform distribution on [0,1]. |
| R-8, SciPy-(1/3,1/3), Maple-7 | (N + 1/3)p + 1/3 | x⌊h⌋ + (h − ⌊h⌋) (x⌊h⌋ + 1 − x⌊h⌋) | Linear interpolation of the approximate medians for order statistics. |
| R-9, SciPy-(3/8,3/8), Maple-8 | (N + 1/4)p + 3/8 | x⌊h⌋ + (h − ⌊h⌋) (x⌊h⌋ + 1 − x⌊h⌋) | The resulting quantile estimates are approximately unbiased for the expected order statistics if x is normally distributed. |
Notes:
- R-1 through R-3 are piecewise constant, with discontinuities.
- R-4 and following are piecewise linear, without discontinuities, but differ in how h is computed.
- R-3 and R-4 are not symmetric in that they do not give h = (N + 1) / 2 when p = 1/2.
- Excel's PERCENTILE.EXC and Python's default "exclusive" method are equivalent to R-6.
- Excel's PERCENTILE and PERCENTILE.INC and Python's optional "inclusive" method are equivalent to R-7. This is R's default method.
- Packages differ in how they estimate quantiles beyond the lowest and highest values in the sample. Choices include returning an error value, computing linear extrapolation, or assuming a constant value.
The standard error of a quantile estimate can in general be estimated via the bootstrap. The Maritz–Jarrett method can also be used.[13]
Approximate quantiles from a stream
Computing approximate quantiles from data arriving from a stream can be done efficiently using compressed data structures. The most popular methods are t-digest[14] and KLL.[15] These methods read a stream of values in a continuous fashion and can, at any time, be queried about the approximate value of a specified quantile.
Both algorithms are based on a similar idea: compressing the stream of values by summarizing identical or similar values with a weight. If the stream is made of a repetition of 100 times v1 and 100 times v2, there is no reason to keep a sorted list of 200 elements, it is enough to keep two elements and two counts to be able to recover the quantiles. With more values, these algorithms maintain a trade-off between the number of unique values stored and the precision of the resulting quantiles. Some values may be discarded from the stream and contribute to the weight of a nearby value without changing the quantile results too much. t-digest uses an approach based on k-means clustering to group similar values whereas KLL uses a more sophisticated "compactor" method that leads to better control of the error bounds.
Both methods belong to the family of data sketches that are subsets of Streaming Algorithms with useful properties: t-digest or KLL sketches can be combined. Computing the sketch for a very large vector of values can be split into trivially parallel processes where sketches are computed for partitions of the vector in parallel and merged later.
Discussion
Standardized test results are commonly reported as a student scoring "in the 80th percentile," for example. This uses an alternative meaning of the word percentile as the interval between (in this case) the 80th and the 81st scalar percentile.[16] This separate meaning of percentile is also used in peer-reviewed scientfic research papers.[17] The meaning used can be derived from its context.
If a distribution is symmetric, then the median is the mean (so long as the latter exists). But, in general, the median and the mean can differ. For instance, with a random variable that has an exponential distribution, any particular sample of this random variable will have roughly a 63% chance of being less than the mean. This is because the exponential distribution has a long tail for positive values but is zero for negative numbers.
Quantiles are useful measures because they are less susceptible than means to long-tailed distributions and outliers. Empirically, if the data being analyzed are not actually distributed according to an assumed distribution, or if there are other potential sources for outliers that are far removed from the mean, then quantiles may be more useful descriptive statistics than means and other moment-related statistics.
Closely related is the subject of least absolute deviations, a method of regression that is more robust to outliers than is least squares, in which the sum of the absolute value of the observed errors is used in place of the squared error. The connection is that the mean is the single estimate of a distribution that minimizes expected squared error while the median minimizes expected absolute error. Least absolute deviations shares the ability to be relatively insensitive to large deviations in outlying observations, although even better methods of robust regression are available.
The quantiles of a random variable are preserved under increasing transformations, in the sense that, for example, if m is the median of a random variable X, then 2m is the median of 2X, unless an arbitrary choice has been made from a range of values to specify a particular quantile. (See quantile estimation, above, for examples of such interpolation.) Quantiles can also be used in cases where only ordinal data are available.
See also
- Flashsort – sort by first bucketing by quantile
- Interquartile range
- Descriptive statistics
- Quartile
- Q–Q plot
- Quantile function
- Quantile normalization
- Quantile regression
- Quantization
- Summary statistics
- Tolerance interval ("confidence intervals for the pth quantile"[18])
References
- Helen Mary Walker, Joseph Lev, Elementary Statistical Methods, 1969, [p. 60 https://books.google.com/books?id=ogYnAQAAIAAJ&dq=permille]
- Stuart, Alan; Ord, Keith (1994). Kendall's Advanced Theory of Statistics. London: Arnold. ISBN 0340614307.
- Hyndman, R.J.; Fan, Y. (November 1996). "Sample Quantiles in Statistical Packages". American Statistician. American Statistical Association. 50 (4): 361–365. doi:10.2307/2684934. JSTOR 2684934.
- Mathematica Documentation See 'Details' section
- "Quantile calculation". uk.mathworks.com.
- Frohne, I.; Hyndman, R.J. (2009). Sample Quantiles. R Project. ISBN 3-900051-07-0.
- "Function Reference: quantile - Octave-Forge - SourceForge". Retrieved 6 September 2013.
- "scipy.stats.mstats.mquantiles — SciPy v1.4.1 Reference Guide". docs.scipy.org.
- "Statistics - Maple Programming Help". www.maplesoft.com.
- "Archived copy". Archived from the original on April 16, 2016. Retrieved April 4, 2016.CS1 maint: archived copy as title (link)
- Stata documentation for the pctile and xtile commands See 'Methods and formulas' section.
- "statistics — Mathematical statistics functions — Python 3.8.3rc1 documentation". docs.python.org.
- Wilcox, Rand R. (2010). Introduction to Robust Estimation and Hypothesis Testing. ISBN 0-12-751542-9.
- Dunning, Ted; Ertl, Otmar (February 2019). "Computing Extremely Accurate Quantiles Using t-Digests". arXiv:1902.04023 [stat.CO].
- Zohar Karnin, Kevin Lang, Edo Liberty (2016). "Optimal Quantile Approximation in Streams". arXiv:1603.05346 [cs.DS].CS1 maint: uses authors parameter (link)
- "percentile". Oxford Reference. doi:10.1093/oi/authority.20110803100316401. Retrieved 2020-08-17.
- Kruger, J.; Dunning, D. (December 1999). "Unskilled and unaware of it: how difficulties in recognizing one's own incompetence lead to inflated self-assessments". Journal of Personality and Social Psychology. 77 (6): 1121–1134. doi:10.1037//0022-3514.77.6.1121. ISSN 0022-3514. PMID 10626367.
- Stephen B. Vardeman (1992). "What about the Other Intervals?". The American Statistician. 46 (3): 193–197. doi:10.2307/2685212. JSTOR 2685212.
Further reading
- Serfling, R. J. (1980). Approximation Theorems of Mathematical Statistics. John Wiley & Sons. ISBN 0-471-02403-1.
External links
