Cache placement policies
A CPU cache is a memory which holds the recently utilized data by the processor. A block of memory cannot necessarily be placed randomly in the cache and may be restricted to a single cache line or a set of cache lines[1] by the cache placement policy.[2][3] In other words, the cache placement policy determines where a particular memory block can be placed when it goes into the cache.
There are three different policies available for placement of a memory block in the cache: direct-mapped, fully associative, and set-associative. Originally this space of cache organizations was described using the term "congruence mapping".[4]
Direct-mapped cache
In a direct-mapped cache structure, the cache is organized into multiple sets[1] with a single cache line per set. Based on the address of the memory block, it can only occupy a single cache line. The cache can be framed as a (n*1) column matrix.[5]
To place a block in the cache
- The set is determined by the index[1] bits derived from the address of the memory block.
- The memory block is placed in the set identified and the tag [1] is stored in the tag field associated with the set.
- If the cache line is previously occupied, then the new data replaces the memory block in the cache.
To search a word in the cache
- The set is identified by the index bits of the address.
- The tag bits derived from the memory block address are compared with the tag bits associated with the set. If the tag matches, then there is a cache hit and the cache block is returned to the processor. Else there is a cache miss and the memory block is fetched from the lower memory(main memory, disk).
Advantages
- This placement policy is power efficient as it avoids the search through all the cache lines.
- The placement policy and the replacement policy is simple.
- It requires cheap hardware as only one tag needs to be checked at a time.
Disadvantage
- It has lower cache hit rate, as there is only one cache line available in a set. Every time a new memory is referenced to the same set, the cache line is replaced, which causes conflict miss.[6]
Example
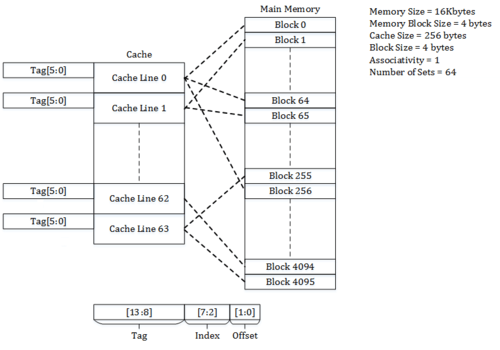
Consider a main memory of 16 kilobytes, which is organized as 4-byte blocks, and a direct-mapped cache of 256 bytes with a block size of 4 bytes.
Since each cache block is of size 4 bytes, the total number of sets in the cache is 256/4, which equals 64 sets.
The incoming address to the cache is divided into bits for Offset, Index and Tag.
Offset corresponds to the bits used to determine the byte to be accessed from the cache line.
In the example, the offset bits are 2 which are used to address the 4 bytes of the cache line.
Index corresponds to bits used to determine the set of the Cache.
In the example, the index bits are 6 which are used to address the 64 sets of the cache.
Tag corresponds to the remaining bits.
In the example, there are 14 – (6+2) = 6 tag bits, which are stored in tag field to match the address on cache request.
Address 0x0000(tag - 00_0000, index – 00_0000, offset – 00) maps to block 0 of the memory and occupies the set 0 of the cache.
Address 0x0004(tag - 00_0000, index – 00_0001, offset – 00) maps to block 1 of the memory and occupies the set 1 of the cache.
Similarly, address 0x00FF(tag – 00_0000, index – 11_1111, offset – 11) maps to block 63 of the memory and occupies the set 63 of the cache.
Address 0x0100(tag – 00_0001, index – 00_0000, offset – 00) maps to block 64 of the memory and occupies the set 0 of the cache.
Fully associative cache
In a fully associative cache, the cache is organized into a single cache set with multiple cache lines. A memory block can occupy any of the cache lines. The cache organization can be framed as (1*m) row matrix.[5]
To place a block in the cache
- The cache line is selected based on the valid bit[1] associated with it. If the valid bit is 0, the new memory block can be placed in the cache line, else it has to be placed in another cache line with valid bit 0.
- If the cache is completely occupied then a block is evicted and the memory block is placed in that cache line.
- The eviction of memory block from the cache is decided by the replacement policy.[7]
To search a word in the cache
- The Tag field of the memory address is compared with tag bits associated with all the cache lines. If it matches, the block is present in the cache and is a cache hit. If it doesn't match, then it's a cache miss and has to be fetched from the lower memory.
- Based on the Offset, a byte is selected and returned to the processor.
Advantages
- Fully associative cache structure provides us the flexibility of placing memory block in any of the cache lines and hence full utilization of the cache.
- The placement policy provides better cache hit rate.
- It offers the flexibility of utilizing a wide variety of replacement algorithms if a cache miss occurs.
Disadvantage
- The placement policy is slow as it takes time to iterate through all the lines.
- The placement policy is power hungry as it has to iterate over entire cache set to locate a block.
- The most expensive of all methods, due to the high cost of associative-comparison hardware.
Example
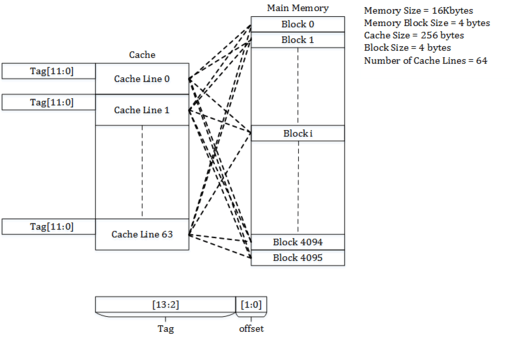
Consider a main memory of 16 kilobytes, which is organized as 4-byte blocks, and a fully associative cache of 256 bytes and a block size of 4 bytes.
Since each cache block is of size 4 bytes, the total number of sets in the cache is 256/4, which equals 64 sets or cache lines.
The incoming address to the cache is divided into bits for offset and tag.
Offset corresponds to the bits used to determine the byte to be accessed from the cache line.
In the example, the offset bits are 2 which are used to address the 4 bytes of the cache line and the remaining bits form the tag.
In the example, the tag bits are 12 (14 – 2), which are stored in the tag field of the cache line to match the address on cache request.
Since any block of memory can be mapped to any cache line, the memory block can occupy one of the cache lines based on the replacement policy.
Set-associative cache
Set-associative cache is a trade-off between direct-mapped cache and fully associative cache.
A set-associative cache can be imagined as a (n*m) matrix. The cache is divided into ‘n’ sets and each set contains ‘m’ cache lines. A memory block is first mapped onto a set and then placed into any cache line of the set.
The range of caches from direct-mapped to fully associative is a continuum of levels of set associativity. (A direct-mapped cache is one-way set-associative and a fully associative cache with m cache lines is m-way set-associative.)
Many processor caches in today's designs are either direct-mapped, two-way set-associative, or four-way set-associative.[5]
To place a block in the cache
- The set is determined by the index bits derived from the address of the memory block.
- The memory block is placed an available cache line in the set identified, and the tag is stored in the tag field associated with the line. If all the cache lines in the set are occupied, then the new data replaces the block identified through the replacement policy.
To locate a word in the cache
- The set is determined by the index bits derived from the address of the memory block.
- The tag bits are compared with the tags of all cache lines present in selected set. If the tag matches any of the cache lines, it is a cache hit and the appropriate line is returned. If the tag doesn't match any of the lines, then it is a cache miss and the data is requested from next level in the memory hierarchy.
Advantages
- The placement policy is a trade-off between direct-mapped and fully associative cache.
- It offers the flexibility of using replacement algorithms if a cache miss occurs.
Disadvantages
- The placement policy will not effectively use all the available cache lines in the cache and suffers from conflict miss.
Example
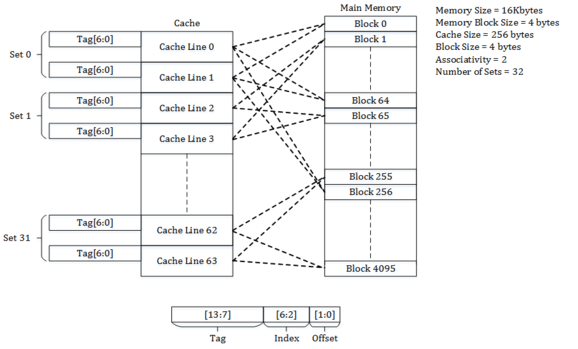
Consider a main memory of 16 kilobytes, which is organized as 4-byte blocks, and a 2-way set-associative cache of 256 bytes with a block size of 4 bytes.
Since each cache block is of size 4 bytes and is 2-way set-associative, the total number of sets in the cache is 256/(4 * 2), which equals 32 sets.
In this example, there are 2 offset bits, which are used to address the 4 bytes of a cache line; there are 5 index bits, which are used to address the 32 sets of the cache; and there are 7 = (14 – (5+2)) tag bits, which are stored in tag to match against addresses from cache requests.
Address 0x0000(tag – 000_0000, index – 0_0000, offset – 00) maps to block 0 of the memory and occupies the set 0 of the cache. The block occupies one of the cache lines of the set 0 and is determined by the replacement policy for the cache.
Address 0x0004(tag – 000_0000, index – 0_0001, offset – 00) maps to block 1 of the memory and occupies one of the cache lines of the set 1 of the cache.
Similarly, address 0x00FF(tag – 000_0001, index – 1_1111, offset – 11) maps to block 63 of the memory and occupies one of the cache lines of the set 31 of the cache.
Address 0x0100(tag – 000_0010, index – 0_0000, offset – 00) maps to block 64 of the memory and occupies one of the cache lines of the set 0 of the cache.
Two-way skewed associative cache
Other schemes have been suggested, such as the skewed cache,[8] where the index for way 0 is direct, as above, but the index for way 1 is formed with a hash function. A good hash function has the property that addresses which conflict with the direct mapping tend not to conflict when mapped with the hash function, and so it is less likely that a program will suffer from an unexpectedly large number of conflict misses due to a pathological access pattern. The downside is extra latency from computing the hash function.[9] Additionally, when it comes time to load a new line and evict an old line, it may be difficult to determine which existing line was least recently used, because the new line conflicts with data at different indexes in each way; LRU tracking for non-skewed caches is usually done on a per-set basis. Nevertheless, skewed-associative caches have major advantages over conventional set-associative ones.[10]
Pseudo-associative cache
A true set-associative cache tests all the possible ways simultaneously, using something like a content addressable memory. A pseudo-associative cache tests each possible way one at a time. A hash-rehash cache and a column-associative cache are examples of a pseudo-associative cache.
In the common case of finding a hit in the first way tested, a pseudo-associative cache is as fast as a direct-mapped cache, but it has a much lower conflict miss rate than a direct-mapped cache, closer to the miss rate of a fully associative cache.[9]
See also
- Associativity
- Cache replacement policy
- Cache hierarchy
- Writing Policies
- Cache coloring
References
- {{Cite web|url=https://cseweb.ucsd.edu/classes/su07/cse141/cache-handout.pdf%7Ctitle=The Basics of Cache}
- "Cache Placement Policies".
- "Placement Policies".
- Mattson, R.L.; Gecsei, J.; Slutz, D. R.; Traiger, I (1970). "Evaluation Techniques for Storage Hierarchies". IBM Systems Journal. 9 (2): 78–117. doi:10.1147/sj.92.0078.
- Solihin, Yan (2015). Fundamentals of Parallel Multi-core Architecture. Taylor & Francis. pp. 136–141. ISBN 978-1482211184.
- "Cache Miss Types" (PDF).
- "Fully Associative Cache".
- André Seznec (1993). "A Case for Two-Way Skewed-Associative Caches". ACM Sigarch Computer Architecture News. 21 (2): 169–178. doi:10.1145/173682.165152.
- C. Kozyrakis. "Lecture 3: Advanced Caching Techniques" (PDF). Archived from the original (PDF) on September 7, 2012.
- Micro-Architecture "Skewed-associative caches have ... major advantages over conventional set-associative caches."