Sedna (database)
Sedna is an open-source database management system that provides native storage for XML data. The distinctive design decisions employed in Sedna are (i) schema-based clustering storage strategy for XML data and (ii) memory management based on layered address space.[1]
| Repository | |
|---|---|
| Written in | C, C++ |
| Operating system | Cross-platform |
| Type | Native XML database |
| License | Apache License 2.0 |
| Website | sedna |
Data organization
Data organization in Sedna is designed with the goal of providing a balance in performance between XML queries and updates execution.[1] The two primary design decisions in data organization in Sedna are:
- Direct pointers are used to represent XML node relationships such as parent, child, and sibling ones. Unlike relational-based approaches that require performing joins for traversing an XML document, traversing in Sedna is performed by simply following a direct pointer.
- A descriptive schema-driven storage strategy is developed which consists of clustering nodes of an XML document according to their positions in the descriptive schema of the document. In contrast to a prescriptive schema that is known in advance and is usually specified in DTD or XML Schema, the descriptive schema is generated from data dynamically (and is maintained incrementally) and represents a concise and an accurate structure summary for data. Using the descriptive schema instead of the prescriptive one makes the storage strategy applicable to any XML document, even a one that comes with no prescriptive schema.
The following figure illustrates the overall principles of data organization in Sedna. The descriptive schema represented as a tree of schema nodes is the central component in the data organization. Each schema node is labeled with an XML node kind [2] (e.g. element, attribute, text, etc.) and has a pointer to data blocks that store XML nodes corresponding to the given schema node. Depending on their node kind, some schema nodes are also labeled with names (e.g., element nodes, attribute nodes). Data blocks related to a common schema node are linked via pointers into a bidirectional list. Node descriptors in a list of blocks are partly ordered according to document order.[3]
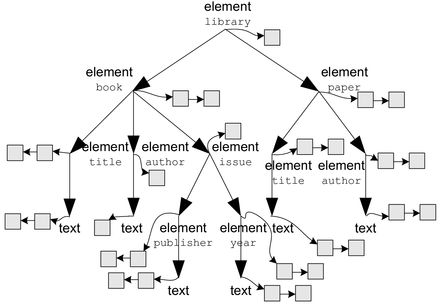
<library>
<book>
<title>Foundations of Databases</title>
<author>Abiteboul</author>
<author>Hull</author>
<author>Vianu</author>
</book>
<book>
<title>An Introduction to Database Systems</title>
<author>Date</author>
<issue>
<publisher>Addison-Wesley</publisher>
<year>2004</year>
</issue>
</book>
...
<paper>
<title>A Relational Model for Large Shared Data Banks</title>
<author>Codd</author>
</paper>
</library>
Citations
- Ilya Taranov et al. Sedna: native XML database management system (internals overview). In ACM SIGMOD '10: Proceedings of the 36th international conference on Association for Computing Machinery's Special Interest Group on Management of Data, pages 1037-1045, New York, NY, USA, 2010. ACM.
- M.F. Fernandez, A. Malhotra, J. Marsh, M.Nagy, and N. Walsh (editors). XQuery 1.0 and XPath 2.0 Data Model (XDM). W3C Recommendation, World Wide Web Consortium, January 2007.
- S. Boag, D. Chamberlin, M. F. Fernandez, D. Florescu, J. Robie, and J. Simeon (editors). XQuery 1.0: An XML query language. W3C recommendation, World Wide Web Consortium, January 2007