STRING
In molecular biology, STRING (Search Tool for the Retrieval of Interacting Genes/Proteins) is a biological database and web resource of known and predicted protein–protein interactions. [1][2][3][4][5][6]
 | |
|---|---|
| Content | |
| Description | Search Tool for the Retrieval of Interacting Genes/Proteins |
| Contact | |
| Research center | Academic Consortium |
| Primary citation | PMID 30476243 |
| Access | |
| Website | STRING website |
| Download URL | url |
| Web service URL | rest |
| Miscellaneous | |
| Version | 11.0 (January 2019) |
The STRING database contains information from numerous sources, including experimental data, computational prediction methods and public text collections. It is freely accessible and it is regularly updated. The resource also serves to highlight functional enrichments in user-provided lists of proteins, using a number of functional classification systems such as GO, Pfam and KEGG. The latest version 10.5 contains information on about 9.6 million proteins from more than 2000 organisms. STRING has been developed by a consortium of academic institutions including CPR, EMBL, KU, SIB, TUD and UZH.
Usage
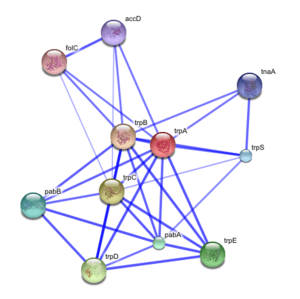
Protein–protein interaction networks are an important ingredient for the system-level understanding of cellular processes. Such networks can be used for filtering and assessing functional genomics data and for providing an intuitive platform for annotating structural, functional and evolutionary properties of proteins. Exploring the predicted interaction networks can suggest new directions for future experimental research and provide cross-species predictions for efficient interaction mapping.[7]
Features
The data is weighted and integrated and a confidence score is calculated for all protein interactions. Results of the various computational predictions can be inspected from different designated views. There are two modes of STRING: Protein-mode and COG-mode. Predicted interactions are propagated to proteins in other organisms for which interaction has been described by inference of orthology. A web interface is available to access the data and to give a fast overview of the proteins and their interactions. A plug-in for cytoscape to use STRING data is available. Another possibility to access data STRING is to use the application programming interface (API) by constructing a URL that contain the request.
Data sources
Like many other databases that store protein association knowledge, STRING imports data from experimentally derived protein–protein interactions through literature curation. Furthermore, STRING also store computationally predicted interactions from: (i) text mining of scientific texts, (ii) interactions computed from genomic features, and (iii) interactions transferred from model organisms based on orthology. [8]
All predicted or imported interactions are benchmarked against a common reference of functional partnership as annotated by KEGG (Kyoto Encyclopedia of Genes and Genomes).
Imported data
STRING imports protein association knowledge from databases of physical interaction and databases of curated biological pathway knowledge (MINT, HPRD, BIND, DIP, BioGRID, KEGG, Reactome, IntAct, EcoCyc, NCI-Nature Pathway Interaction Database, GO). Links are supplied to the originating data of the respective experimental repositories and database resources.
Text mining
A large body of scientific texts (SGD, OMIM, FlyBase, PubMed) are parsed to search for statistically relevant co-occurrences of gene names.
Predicted data
- Neighborhood: Similar genomic context in different species suggest a similar function of the proteins.
- Fusion-fission events: Proteins that are fused in some genomes are very likely to be functionally linked (as in other genomes where the genes are not fused).
- Occurrence: Proteins that have a similar function or an occurrence in the same metabolic pathway, must be expressed together and have similar phylogenetic profile.
- Coexpression: Predicted association between genes based on observed patterns of simultaneous expression of genes.
References
- Szklarczyk, Damian; Gable, Annika L.; Lyon, David; Junge, Alexander; Wyder, Stefan; Huerta-Cepas, Jaime; Simonovic, Milan; Doncheva, Nadezhda T.; Morris, John H.; Bork, Peer; Jensen, Lars J. (8 January 2019). "STRING v11: protein-protein association networks with increased coverage, supporting functional discovery in genome-wide experimental datasets". Nucleic Acids Research. 47 (D1): D607–D613. doi:10.1093/nar/gky1131. ISSN 1362-4962. PMC 6323986. PMID 30476243.
- Szklarczyk, Damian; Morris, John H.; Cook, Helen; Kuhn, Michael; Wyder, Stefan; Simonovic, Milan; Santos, Alberto; Doncheva, Nadezhda T.; Roth, Alexander; Bork, Peer; Jensen, Lars J. (4 January 2017). "The STRING database in 2017: quality-controlled protein-protein association networks, made broadly accessible". Nucleic Acids Research. 45 (D1): D362–D368. doi:10.1093/nar/gkw937. ISSN 1362-4962. PMC 5210637. PMID 27924014.
- Szklarczyk D, Franceschini A, Wyder S, Forslund K, Heller D, Huerta-Cepas J, Simonovic M, Roth A, Santos A, Tsafou KP, Kuhn M, Bork P, Jensen LJ, von Mering C (2015). "STRING v10: protein-protein interaction networks, integrated over the tree of life". Nucleic Acids Res. 43 (Database issue): D447–52. doi:10.1093/nar/gku1003. PMC 4383874. PMID 25352553.
- Franceschini A, Szklarczyk D, Frankild S, Kuhn M, Simonovic M, Roth A, Lin J, Minguez P, Bork P, von Mering C, Jensen LJ (2013). "STRING v9.1: protein-protein interaction networks, with increased coverage and integration". Nucleic Acids Res. 41 (Database issue): D808–15. doi:10.1093/nar/gks1094. PMC 3531103. PMID 23203871.
- Szklarczyk D, Franceschini A, Kuhn M, Simonovic M, Roth A, Minguez P, Doerks T, Stark M, Muller J, Bork P, Jensen LJ, von Mering C (2011). "The STRING database in 2011: functional interaction networks of proteins, globally integrated and scored". Nucleic Acids Res. 39 (Database issue): D561–8. doi:10.1093/nar/gkq973. PMC 3013807. PMID 21045058.
- Snel, B; Lehmann, G; Bork, P & Huynen, MA (2000). "STRING: a web-server to retrieve and display the repeatedly occurring neighbourhood of a gene". Nucleic Acids Res. 28 (18): 3442–4. doi:10.1093/nar/28.18.3442. PMC 110752. PMID 10982861.
- Schwartz, AS; Yu, J; Gardenour, KR; Finley Jr; RL & Ideker, T (2008). "Cost-effective strategies for completing the interactome". Nature Methods. 6 (1): 55–61. doi:10.1038/nmeth.1283. PMC 2613168. PMID 19079254.
- Wodak, SJ; Pu, S; Vlasblom, J & Séraphin, B (2009). "Challenges and rewards of interaction proteomics". Mol Cell Proteomics. 8 (1): 3–18. doi:10.1074/mcp.R800014-MCP200. PMID 18799807.
External links
- STRING site
- STITCH website, related database on interactions of proteins with small molecules