STARR-seq
STARR-seq (short for self-transcribing active regulatory region sequencing) is a method to assay enhancer activity for millions of candidates from arbitrary sources of DNA. It is used to identify the sequences that act as transcriptional enhancers in a direct, quantitative, and genome-wide manner.[1]
Introduction
In eukaryotes, transcription is regulated by sequence-specific DNA-binding proteins (transcription factors) associated with a gene’s promoter and also by distant control sequences including enhancers. Enhancers are non-coding DNA sequences, containing several binding sites for a variety of transcription factors.[2] They typically recruit transcriptional factors that modulate chromatin structure and directly interact with the transcription machinery placed at the promoter of gene. Enhancers are able to regulate transcription of target genes in a cell type-specific manner,[1] independent of their location or distance from the promoter of genes. Occasionally, they can regulate transcription of genes located in a different chromosome.[3] However, the knowledge about enhancers so far has been limited to studies of a small number of enhancers, as they have been difficult to identify accurately at a genome-wide scale.[2] Moreover, many regulatory elements function only in certain cell types and specific conditions.[4]
Enhancer detection
Enhancer detection in Drosophila is an original methodology using random insertion of transposon-derived vector that encodes a reporter protein downstream of a minimal promoter. This approach allows to observe the expression of reporter in transgenic animals and provides information about nearby genes that are regulated by these sequences. The discovery and characterization of cell types along with genes involved in their determination have been significantly improved by the discovery of this technique.[5][6][7][8]
During the past few years, post-genomic technologies, have displayed specific features of poised and active enhancers that have improved enhancer discovery.[2] Development of new methods such as deep sequencing of DNase I hypersensitive sites (DNase-Seq), formaldehyde-assisted isolation of regulatory elements sequencing (FAIRE-Seq), and chromatin immunoprecipitation followed by deep sequencing (ChIP-sequencing) provide genome-wide enhancer predictions by enhancer-associated chromatin features.[1]
Application
DHS-sequencing and FAIRE-sequencing fail to provide a direct functional or quantitative readout of enhancer activity. To obtain this, reporter assays that deduce enhancer strength from the loads of reporter transcripts is needed. Moreover, such assays are not able to offer the millions of tests required for identification of enhancers in genome-wide manner.[1] Development of STARR-seq help to identify enhancers in a direct, quantitative and genome-wide manner. Taking advantage of the knowledge that enhancers can work independent of their relative locations, candidate sequences are placed downstream of a minimal promoter, allowing the active enhancers to transcribe themselves. The strength of each enhancer is then reflected by its richness among cellular RNAs. Such a direct coupling of candidate sequences to enhancer activity enables the parallel evaluation of millions of DNA fragments from arbitrary sources.[1]
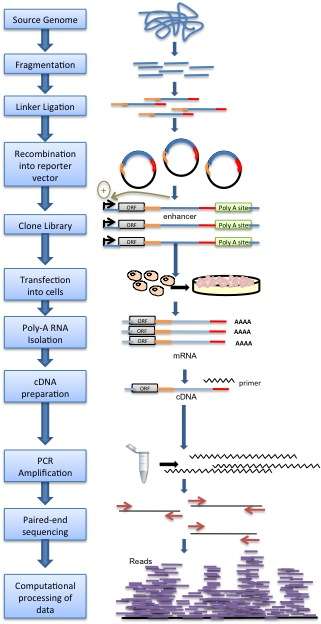
Methodology
Genomic DNA is randomly sheared and broken down to small fragments. Adaptors are ligated to size-selected DNA fragments. Next, adaptor linked fragments are amplified and the PCR products are purified followed by placing candidate sequences downstream of a minimal promoter of screening vectors, giving them an opportunity to transcribe themselves. Candidate cells are then transfected with reporter library and cultured. Thereafter, total RNAs are extracted and poly-A RNAs isolated. Using reverse transcription method, cDNAs are produced, amplified and then candidate fragments are used for high-throughput paired end sequencing. Sequence reads are mapped to the reference genome and computational processing of data is carried out.[1]
Enhancer discovery in Drosophila
Applying this technology to Drosophila genome, Arnold et al.[1] found 96% of the non-repetitive genome with at least 10-fold coverage. Authors discovered that most identified enhancers (55.6%) were placed within introns, particularly in the first intron and intergenic regions. 4.5% of enhancers were located at transcription start sites (TSS), suggesting that these enhancers can start transcription and also improve transcription from a distant TSS.[1] The strongest enhancers were near housekeeping genes such as enzymes or component of the cytoskeleton and developmental regulators such as the transcription factors. The strongest enhancer was located within the intron of the transcription factor zfh1. This transcription factor regulates neuropeptide expression and growth of larval neuromuscular junctions in Drosophila.[9] The ribosomal protein genes were the only class of genes with poor enhancers ranking. Moreover, authors demonstrated that many genes are regulated by several independent active enhancers even in a single cell type. Furthermore, gene expression levels on average were correlated with the sum of the enhancer strengths per gene, supporting direct link between gene expression and enhancer activity.[1]
Characterization of Regulatory Variant Alleles in Human Genetic Study Cohorts
Applying this technology to the characterization and discovery of regulatory variant alleles, Vockley et al.[10] characterized the effects of human genetic variation on non-coding regulatory element function, measuring the activity of 100 putative enhancers captured directly from the genomes of 95 members of a study cohort. This approach enables the functional fine-mapping of causal regulatory variants in regions of high linkage disequilibrium identified by eQTL analyses. This approach provides a general path forward to identify perturbations in gene regulatory elements that contribute to complex phenotypes.
Quantifying the enhancer activity of ChIP enriched DNA fragments
STARR-seq has been used to measure the regulatory activity of DNA fragments that have been enriched for sites occupied by specific transcription factors. Cloning ChIP DNA libraries generated from chromatin immunoprecipitation of the glucocorticoid receptor into STARR-seq enabled genome-scale quantification of glucocorticoid-induced enhancer activity.[11] This approach is useful for measuring the differences in enhancer activity between sites that are bound by the same transcription factor.
Advantages
- A quantitative genome-wide assay for enhancer detection.[1]
- Applicable technique for screening arbitrary sources of DNA in any cell type or tissue that allows adequate introduction of reporter constructs.[1]
- A method with high detection rate (>99%) by employing pair-end sequencing, even for sequences that contain transcript-destabilizing elements.
- Technique to evaluate the strength of enhancers quantitatively, and identify endogenously silenced enhancers by integrating them into a chromosomal context.[1]
Future Directions
STARR-seq by combining traditional approach with high-throughput sequencing technology and highly specialized bio-computing methods is able to detect enhancers in a quantitative and genome-wide manner. The study of gene regulation and their responsible pathways in the genome during normal development and also in disease can be very demanding. Therefore, applying STARR-seq to many cell types across organisms supports identifying cell type-specific gene regulatory elements and practically assesses non-coding mutations causing disease. Recently, a related approach coupling capture of regions of interest to STARR-seq technique have been developed and extensively validated in mammalian cell lines.[12]
References
- Arnold, Cosmas; Daniel Gerlach; Christoph Stelzer; Łukasz M. Boryń; Martina Rath; Alexander Stark (January 2013). "Genome-Wide Quantitative Enhancer Activity Maps Identified by STARR-seq". Science. 339 (6123): 1074–7. doi:10.1126/science.1232542. PMID 23328393.
- Xu, Jian; Stephen T. Smale (November 2012). "Designing an Enhancer Landscape". Cell. 151 (5): 929–931. doi:10.1016/j.cell.2012.11.007. PMC 3732118. PMID 23178114.
- Ong, Chin-Tong; Victor G. Corces (April 2011). "Enhancer function: new insights into the regulation of tissue-specific gene expression". Nature Reviews Genetics. 12 (4): 283–293. doi:10.1038/nrg2957. PMC 3175006. PMID 21358745.
- Baker, Monya (28 April 2011). "Highlighting enhancers". Nature Methods. 8 (5): 373. doi:10.1038/nmeth0511-373. PMID 21678620.
- Bellen, Hugo J (December 1999). "Ten Years of Enhancer Detection: Lessons from the Fly". The Plant Cell. 11 (12): 2271–2281. doi:10.2307/3870954. JSTOR 3870954. PMC 144146. PMID 10590157.
- Bier, E; Vaessin H; Shepherd S; Lee K; McCall K; Barbel S; Ackerman L; Carretto R; Uemura T; Grell E (September 1989). "Searching for pattern and mutation in the Drosophila genome with a P-lacZ vector". Genes & Development. 3 (9): 1273–1287. doi:10.1101/gad.3.9.1273. PMID 2558049.
- Wilson, C; Pearson RK; Bellen HJ; O’Kane CJ; Grossniklaus U; Gehring WJ (September 1989). "P-element mediated enhancer detection: an efficient method for isolating and characterizing developmentally regulated genes in Drosophila". Genes & Development. 3 (9): 1301–1313. doi:10.1101/gad.3.9.1301. PMID 2558051.
- O'Kane, CJ; Gehring WJ (December 1987). "Detection in situ of genomic regulatory elements in Drosophila". Proc Natl Acad Sci U S A. 84 (24): 9123–9127. doi:10.1073/pnas.84.24.9123. PMC 299704. PMID 2827169.
- Volger, G; Urban J (July 2008). "The transcription factor Zfh1 is involved in the regulation of neuropeptide expression and growth of larval neuromuscular junctions in Drosophila melanogaster". Developmental Biology. 319 (1): 78–85. doi:10.1016/j.ydbio.2008.04.008. PMID 18499094.
- Vockley, Christopher M.; Guo, Cong; Majoros, William H.; Nodzenski, Michael; Scholtens, Denise M.; Hayes, M. Geoffrey; Lowe, William L.; Reddy, Timothy E. (2015-08-01). "Massively parallel quantification of the regulatory effects of noncoding genetic variation in a human cohort". Genome Research. 25 (8): 1206–1214. doi:10.1101/gr.190090.115. ISSN 1549-5469. PMC 4510004. PMID 26084464.
- Vockley, Christopher M.; D’Ippolito, Anthony M.; McDowell, Ian C.; Majoros, William H.; Safi, Alexias; Song, Lingyun; Crawford, Gregory E.; Reddy, Timothy E. (2015-08-25). "Direct GR Binding Sites Potentiate Clusters of TF Binding across the Human Genome". Cell. 166 (5): 1269–1281. doi:10.1016/j.cell.2016.07.049. ISSN 0092-8674. PMC 5046229. PMID 27565349.
- Vanhille L., A. Griffon, M.A. Maqbool, J. Zacarias, L.T.M. Dao, N. Fernandez, B. Ballester, J.C. Andrau, S. Spicuglia (2015). CapStarr-seq: a high-throughput method for quantitative assessment of enhancer activity in mammals. Nat. Commun. 6:6905.