Residual neural network
A residual neural network (ResNet) is an artificial neural network (ANN) of a kind that builds on constructs known from pyramidal cells in the cerebral cortex. Residual neural networks do this by utilizing skip connections, or shortcuts to jump over some layers. Typical ResNet models are implemented with double- or triple- layer skips that contain nonlinearities (ReLU) and batch normalization in between.[1][2] An additional weight matrix may be used to learn the skip weights; these models are known as HighwayNets.[3] Models with several parallel skips are referred to as DenseNets.[4][5] In the context of residual neural networks, a non-residual network may be described as a plain network.
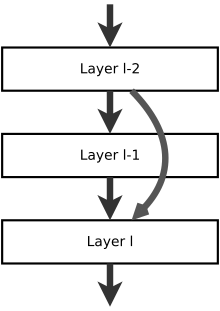
One motivation for skipping over layers is to avoid the problem of vanishing gradients, by reusing activations from a previous layer until the adjacent layer learns its weights. During training, the weights adapt to mute the upstream layer, and amplify the previously-skipped layer. In the simplest case, only the weights for the adjacent layer's connection are adapted, with no explicit weights for the upstream layer. This works best when a single nonlinear layer is stepped over, or when the intermediate layers are all linear. If not, then an explicit weight matrix should be learned for the skipped connection (a HighwayNet should be used).
Skipping effectively simplifies the network, using fewer layers in the initial training stages. This speeds learning by reducing the impact of vanishing gradients, as there are fewer layers to propagate through. The network then gradually restores the skipped layers as it learns the feature space. Towards the end of training, when all layers are expanded, it stays closer to the manifold and thus learns faster. A neural network without residual parts explores more of the feature space. This makes it more vulnerable to perturbations that cause it to leave the manifold, and necessitates extra training data to recover.
Biological analogue
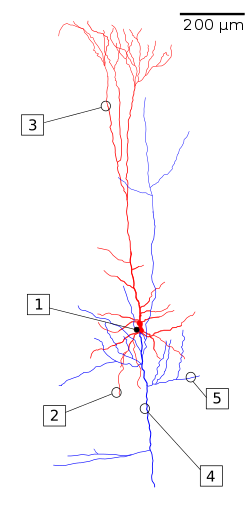
The brain has structures similar to residual nets, as cortical layer VI neurons get input from layer I, skipping intermediary layers.[6] In the figure this compares to signals from the apical dendrite (3) skipping over layers, while the basal dendrite (2) collects signals from the previous and/or same layer.[note 1][7] Similar structures exists for other layers.[8] How many layers in the cerebral cortex compare to layers in an artificial neural network is not clear, nor whether every area in the cerebral cortex exhibits the same structure, but over large areas they appear similar.
Forward propagation
For single skips, the layers may be indexed either as to or as to . (Script used for clarity, usually it is written as a simple l.) The two indexing systems are convenient when describing skips as going backward or forward. As signal flows forward through the network it is easier to describe the skip as from a given layer, but as a learning rule (back propagation) it is easier to describe which activation layer you reuse as , where is the skip number.






Given a weight matrix for connection weights from layer to , and a weight matrix for connection weights from layer to , then the forward propagation through the activation function would be (aka HighwayNets)




where
- the activations (outputs) of neurons in layer ,
- the activation function for layer ,
- the weight matrix for neurons between layer and , and



Absent an explicit matrix (aka ResNets), forward propagation through the activation function simplifies to

Another way to formulate this is to substitute an identity matrix for , but that is only valid when the dimensions match. This is somewhat confusingly called an identity block, which means that the activations from layer are passed to layer without weighting.
In the cerebral cortex such forward skips are done for several layers. Usually all forward skips start from the same layer, and successively connect to later layers. In the general case this will be expressed as (aka DenseNets)
- .

Backward propagation
During backpropagation learning for the normal path

and for the skip paths (nearly identical)
- .

In both cases
- a learning rate (,
- the error signal of neurons at layer , and
- the activation of neurons at layer .




If the skip path has fixed weights (e.g. the identity matrix, as above), then they are not updated. If they can be updated, the rule is an ordinary backpropagation update rule.
In the general case there can be skip path weight matrices, thus


As the learning rules are similar, the weight matrices can be merged and learned in the same step.
Notes
- Some research indicates that there are additional structures here, so this explanation is somewhat simplified.
References
- He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2015-12-10). "Deep Residual Learning for Image Recognition". arXiv:1512.03385 [cs.CV].
- He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2016). "Deep Residual Learning for Image Recognition" (PDF). Proc. Computer Vision and Pattern Recognition (CVPR), IEEE. Retrieved 2020-04-23.
- Srivastava, Rupesh Kumar; Greff, Klaus; Schmidhuber, Jürgen (2015-05-02). "Highway Networks". arXiv:1505.00387 [cs.LG].
- Huang, Gao; Liu, Zhuang; Weinberger, Kilian Q.; van der Maaten, Laurens (2016-08-24). "Densely Connected Convolutional Networks". arXiv:1608.06993 [cs.CV].
- Huang, Gao; Liu, Zhuang; Weinberger, Kilian Q.; van der Maaten, Laurens (2017). "Densely Connected Convolutional Networks" (PDF). Proc. Computer Vision and Pattern Recognition (CVPR), IEEE. Retrieved 2020-04-23.
- Thomson, AM (2010). "Neocortical layer 6, a review". Frontiers in Neuroanatomy. 4: 13. doi:10.3389/fnana.2010.00013. PMC 2885865. PMID 20556241.
- Winterer, Jochen; Maier, Nikolaus; Wozny, Christian; Beed, Prateep; Breustedt, Jörg; Evangelista, Roberta; Peng, Yangfan; D’Albis, Tiziano; Kempter, Richard (2017). "Excitatory Microcircuits within Superficial Layers of the Medial Entorhinal Cortex". Cell Reports. 19 (6): 1110–1116. doi:10.1016/j.celrep.2017.04.041. PMID 28494861.
- Fitzpatrick, David (1996-05-01). "The Functional Organization of Local Circuits in Visual Cortex: Insights from the Study of Tree Shrew Striate Cortex". Cerebral Cortex. 6 (3): 329–341. doi:10.1093/cercor/6.3.329. ISSN 1047-3211. PMID 8670661.