Rendezvous hashing
Rendezvous or highest random weight (HRW) hashing[1][2] is an algorithm that allows clients to achieve distributed agreement on a set of options out of a possible set of options. A typical application is when clients need to agree on which sites (or proxies) objects are assigned to.


Rendezvous hashing is more general than consistent hashing, which becomes a special case (for ) of rendezvous hashing.

History
Rendezvous hashing was invented by David Thaler and Chinya Ravishankar at the University of Michigan in 1996.[1] Consistent hashing appeared a year later in the literature. One of the first applications of rendezvous hashing was to enable multicast clients on the Internet (in contexts such as the MBONE) to identify multicast rendezvous points in a distributed fashion.[3][4] It was used in 1998 by Microsoft's Cache Array Routing Protocol (CARP) for distributed cache coordination and routing.[5][6] Some Protocol Independent Multicast routing protocols use rendezvous hashing to pick a rendezvous point.[1]
Given its simplicity and generality, rendezvous hashing has been applied in a wide variety of applications, including mobile caching,[7] router design,[8] secure key establishment,[9] and sharding and distributed databases.[10]
Overview
Algorithm
Rendezvous hashing solves the distributed hash table problem: How can a set of clients, given an object , agree on where in a set of sites (servers, say) to place ? Each client is to select a site independently, but all clients must end up picking the same site. This is non-trivial if we add a minimal disruption constraint, and require that only objects mapping to a removed site may be reassigned to other sites.

The basic idea is to give each site a score (a weight) for each object , and assign the object to the highest scoring site. All clients first agree on a hash function . For object , the site is defined to have weight . HRW assigns to the site whose weight is the largest. Since is agreed upon, each client can independently compute the weights and pick the largest. If the goal is distributed -agreement, the clients can independently pick the sites with the largest hash values.







If a site is added or removed, only the objects mapping to are remapped to different sites, satisfying the minimal disruption constraint above. The HRW assignment can be computed independently by any client, since it depends only on the identifiers for the set of sites and the object being assigned.


HRW easily accommodates different capacities among sites. If site has twice the capacity of the other sites, we simply represent twice in the list, say, as . Clearly, twice as many objects will now map to as to the other sites.


Properties
It might first appear sufficient to treat the n sites as buckets in a hash table and hash the object name O into this table. However, if any of the sites fails or is unreachable, the hash table size changes, requiring all objects to be remapped. This massive disruption makes such direct hashing unworkable. Under rendezvous hashing, however, clients handle site failures by picking the site that yields the next largest weight. Remapping is required only for objects currently mapped to the failed site, and disruption is minimal.[1][2]
Rendezvous hashing has the following properties:
- Low overhead: The hash function used is efficient, so overhead at the clients is very low.
- Load balancing: Since the hash function is randomizing, each of the n sites is equally likely to receive the object O. Loads are uniform across the sites.
- Site capacity: Sites with different capacities can be represented in the site list with multiplicity in proportion to capacity. A site with twice the capacity of the other sites will be represented twice in the list, while every other site is represented once.
- High hit rate: Since all clients agree on placing an object O into the same site SO , each fetch or placement of O into SO yields the maximum utility in terms of hit rate. The object O will always be found unless it is evicted by some replacement algorithm at SO.
- Minimal disruption: When a site fails, only the objects mapped to that site need to be remapped. Disruption is at the minimal possible level, as proved in.[1][2]
- Distributed k-agreement: Clients can reach distributed agreement on k sites simply by selecting the top k sites in the ordering.[9]
Comparison with consistent hashing
Consistent hashing operates by mapping sites uniformly and randomly to points on a unit circle called tokens. Objects are also mapped to the unit circle and placed in the site whose token is the first encountered traveling clockwise from the object's location. When a site is removed, the objects it owns are transferred to the site owning the next token encountered moving clockwise. Provided each site is mapped to a large number (100–200, say) of tokens this will reassign objects in a relatively uniform fashion among the remaining sites.
If sites are mapped to points on the circle randomly by hashing 200 variants of the site ID, say, the assignment of any object requires storing or recalculating 200 hash values for each site. However, the tokens associated with a given site can be precomputed and stored in a sorted list, requiring only a single application of the hash function to the object, and a binary search to compute the assignment. Even with many tokens per site, however, the basic version of consistent hashing may not balance objects uniformly over sites, since when a site is removed each object assigned to it is distributed only over as many other sites as the site has tokens (say 100–200).
Variants of consistent hashing (such as Amazon's Dynamo) that use more complex logic to distribute tokens on the unit circle offer better load balancing than basic consistent hashing, reduce the overhead of adding new sites, and reduce metadata overhead and offer other benefits.[11]
In contrast, rendezvous hashing (HRW) is much simpler conceptually and in practice. It also distributes objects uniformly over all sites, given a uniform hash function. Unlike consistent hashing, HRW requires no precomputing or storage of tokens. An object is placed into one of sites by computing the hash values and picking the site that yields the highest hash value. If a new site is added, new object placements or requests will compute hash values, and pick the largest of these. If an object already in the system at maps to this new site , it will be fetched afresh and cached at . All clients will henceforth obtain it from this site, and the old cached copy at will ultimately be replaced by the local cache management algorithm. If is taken offline, its objects will be remapped uniformly to the remaining sites.




Variants of the HRW algorithm, such as the use of a skeleton (see below), can reduce the time for object location to , at the cost of less global uniformity of placement. When is not too large, however, the placement cost of basic HRW is not likely to be a problem. HRW completely avoids all the overhead and complexity associated with correctly handling multiple tokens for each site and associated metadata.


Rendezvous hashing also has the great advantage that it provides simple solutions to other important problems, such as distributed -agreement.
Consistent hashing is a special case of Rendezvous hashing
Rendezvous hashing is both simpler and more general than consistent hashing. Consistent hashing can be shown to be a special case of HRW by an appropriate choice of a two-place hash function. From the site identifier the simplest version of consistent hashing computes a list of token positions, e.g., where hashes values to locations on the unit circle. Define the two place hash function to be where denotes the distance along the unit circle from to (since has some minimal non-zero value there is no problem translating this value to a unique integer in some bounded range). This will duplicate exactly the assignment produced by consistent hashing.







It is not possible, however, to reduce HRW to consistent hashing (assuming the number of tokens per site is bounded), since HRW potentially reassigns the objects from a removed site to an unbounded number of other sites.
Weighted variations
In the standard implementation of rendezvous hashing, every node receives a statically equal proportion of the keys. This behavior, however, is undesirable when the nodes have different capacities for processing or holding their assigned keys. For example, if one of the nodes had twice the storage capacity as the others, it would be beneficial if the algorithm could take this into account such that this more powerful node would receive twice the number of keys as each of the others.
A straightforward mechanism to handle this case is to assign two virtual locations to this node, so that if either of that larger node's virtual locations has the highest hash, that node receives the key. But this strategy does not work when the relative weights are not integer multiples. For example, if one node had 42% more storage capacity, it would require adding many virtual nodes in different proportions, leading to greatly reduced performance. Several modifications to rendezvous hashing have been proposed to overcome this limitation.
Cache Array Routing Protocol
The Cache Array Routing Protocol (CARP) is a 1998 IETF draft that describes a method for computing load factors which can be multiplied by each node's hash score to yield an arbitrary level of precision for weighting nodes differently.[5] However, one disadvantage of this approach is that when any node's weight is changed, or when any node is added or removed, all the load factors must be re-computed and relatively scaled. When the load factors change relative to one another, it triggers movement of keys between nodes whose weight was not changed, but whose load factor did change relative to other nodes in the system. This results in excess movement of keys.[12]
Controlled replication
Controlled replication under scalable hashing or CRUSH[13] is an extension to RUSH[14] that improves upon rendezvous hashing by constructing a tree where a pseudo-random function (hash) is used to navigate down the tree to find which node is ultimately responsible for a given key. It permits perfect stability for adding nodes however it is not perfectly stable when removing or re-weighting nodes, with the excess movement of keys being proportional to the height of the tree.
The CRUSH algorithm is used by the ceph data storage system to map data objects to the nodes responsible for storing them.[15]
Skeleton-based variant
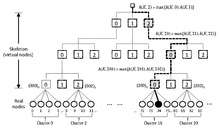
When is extremely large, a skeleton-based variant can improve running time.[16][17][18] This approach creates a virtual hierarchical structure (called a "skeleton"), and achieves running time by applying HRW at each level while descending the hierarchy. The idea is to first choose some constant and organize the sites into clusters Next, build a virtual hierarchy by choosing a constant and imagining these clusters placed at the leaves of a tree of virtual nodes, each with fanout .






In the accompanying diagram, the cluster size is , and the skeleton fanout is . Assuming 108 sites (real nodes) for convenience, we get a three-tier virtual hierarchy. Since , each virtual node has a natural numbering in octal. Thus, the 27 virtual nodes at the lowest tier would be numbered in octal (we can, of course, vary the fanout at each level - in that case, each node will be identified with the corresponding mixed-radix number).



Instead of applying HRW to all 108 real nodes, we can first apply HRW to the 27 lowest-tier virtual nodes, selecting one. We then apply HRW to the four real nodes in its cluster, and choose the winning site. We only need hashes, rather than 108. If we apply this method starting one level higher in the hierarchy, we would need hashes to get to the winning site. The figure shows how, if we proceed starting from the root of the skeleton, we may successively choose the virtual nodes , , and , and finally end up with site 74.





We can start at any level in the virtual hierarchy, not just at the root. Starting lower in the hierarchy requires more hashes, but may improve load distribution in the case of failures. Also, the virtual hierarchy need not be stored, but can be created on demand, since the virtual nodes names are simply prefixes of base- (or mixed-radix) representations. We can easily create appropriately sorted strings from the digits, as required. In the example, we would be working with the strings (at tier 1), (at tier 2), and (at tier 3). Clearly, has height , since and are both constants. The work done at each level is , since is a constant.





For any given object, it is clear that the method chooses each cluster, and hence each of the sites, with equal probability. If the site finally selected is unavailable, we can select a different site within the same cluster, in the usual manner. Alternatively, we could go up one or more tiers in the skeleton and select an alternate from among the sibling virtual nodes at that tier, and once again descend the hierarchy to the real nodes, as above.
The value of can be chosen based on factors like the anticipated failure rate and the degree of desired load balancing. A higher value of leads to less load skew in the event of failure at the cost of higher search overhead.
The choice is equivalent to non-hierarchical rendezvous hashing. In practice, the hash function is very cheap, so can work quite well unless is very high.


Other variants
In 2005, Christian Schindelhauer and Gunnar Schomaker described a logarithmic method for re-weighting hash scores in a way that does not require relative scaling of load factors when a node's weight changes or when nodes are added or removed.[19] This enabled the dual benefits of perfect precision when weighting nodes, along with perfect stability, as only a minimum number of keys needed to be remapped to new nodes.
A similar logarithm-based hashing strategy is used to assign data to storage nodes in Cleversafe's data storage system, now IBM Cloud Object Storage.[12]
Implementation
Implementation is straightforward once a hash function is chosen (the original work on the HRW method makes a hash function recommendation).[1][2] Each client only needs to compute a hash value for each of the sites, and then pick the largest. This algorithm runs in time. If the hash function is efficient, the running time is not a problem unless is very large.
Weighted rendezvous hash
Python code implementing a weighted rendezvous hash:[12]
#!/usr/bin/env python3
import mmh3
import math
def int_to_float(value: int) -> float:
"""Converts a uniformly random [[64-bit computing|64-bit]] integer to uniformly random floating point number on interval <math>[0, 1)</math>."""
fifty_three_ones = 0xFFFFFFFFFFFFFFFF >> (64 - 53)
fifty_three_zeros = float(1 << 53)
return (value & fifty_three_ones) / fifty_three_zeros
class Node(object):
"""Class representing a node that is assigned keys as part of a weighted rendezvous hash."""
def __init__(self, name: str, seed, weight) -> None:
self.name, self.seed, self.weight = name, seed, weight
def __str__(self):
return "[" + self.name + " (" + str(self.seed) + ", " + str(self.weight) + ")]"
def compute_weighted_score(self, key):
hash_1, hash_2 = mmh3.hash64(str(key), 0xFFFFFFFF & self.seed)
hash_f = int_to_float(hash_2)
score = 1.0 / -math.log(hash_f)
return self.weight * score
def determine_responsible_node(nodes, key):
"""Determines which node, of a set of nodes of various weights, is responsible for the provided key."""
highest_score, champion = -1, None
for node in nodes:
score = node.compute_weighted_score(key)
if score > highest_score:
champion, highest_score = node, score
return champion
Example outputs of WRH:
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.39)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import wrh
>>> node1 = wrh.Node("node1", 123, 100)
>>> node2 = wrh.Node("node2", 567, 200)
>>> node3 = wrh.Node("node3", 789, 300)
>>> str(wrh.determine_responsible_node([node1, node2, node3], 'foo'))
'[node3 (789, 300)]'
>>> str(wrh.determine_responsible_node([node1, node2, node3], 'bar'))
'[node3 (789, 300)]'
>>> str(wrh.determine_responsible_node([node1, node2, node3], 'hello'))
'[node2 (567, 200)]'
References
- Thaler, David; Chinya Ravishankar. "A Name-Based Mapping Scheme for Rendezvous" (PDF). University of Michigan Technical Report CSE-TR-316-96. Retrieved 2013-09-15.
- Thaler, David; Chinya Ravishankar (February 1998). "Using Name-Based Mapping Schemes to Increase Hit Rates". IEEE/ACM Transactions on Networking. 6 (1): 1–14. CiteSeerX 10.1.1.416.8943. doi:10.1109/90.663936.
- Blazevic, Ljubica. "Distributed Core Multicast (DCM): a routing protocol for many small groups with application to mobile IP telephony". IETF Draft. IETF. Retrieved September 17, 2013.
- Fenner, B. "Protocol Independent Multicast - Sparse Mode (PIM-SM): Protocol Specification (Revised)". IETF RFC. IETF. Retrieved September 17, 2013.
- Valloppillil, Vinod; Kenneth Ross. "Cache Array Routing Protocol v1.0". Internet Draft. Retrieved September 15, 2013.
- "Cache Array Routing Protocol and Microsoft Proxy Server 2.0" (PDF). Microsoft. Archived from the original (PDF) on September 18, 2014. Retrieved September 15, 2013.
- Mayank, Anup; Ravishankar, Chinya (2006). "Supporting mobile device communications in the presence of broadcast servers" (PDF). International Journal of Sensor Networks. 2 (1/2): 9–16. doi:10.1504/IJSNET.2007.012977.
- Guo, Danhua; Bhuyan, Laxmi; Liu, Bin (October 2012). "An efficient parallelized L7-filter design for multicore servers". IEEE/ACM Transactions on Networking. 20 (5): 1426–1439. doi:10.1109/TNET.2011.2177858.
- Wang, Peng; Ravishankar, Chinya (2015). "Key Foisting and Key Stealing Attacks in Sensor Networks'" (PDF). International Journal of Sensor Networks.
- Mukherjee, Niloy; et al. (August 2015). "Distributed Architecture of Oracle Database In-memory". Proceedings of the VLDB Endowment. 8 (12): 1630–1641. doi:10.14778/2824032.2824061.
- DeCandia, G.; Hastorun, D.; Jampani, M.; Kakulapati, G.; Lakshman, A.; Pilchin, A.; Sivasubramanian, S.; Vosshall, P.; Vogels, W. (2007). "Dynamo: Amazon's Highly Available Key-Value Store" (PDF). Proceedings of the 21st ACM Symposium on Operating Systems Principles. doi:10.1145/1323293.1294281. Retrieved 2018-06-07.
- Jason Resch. "New Hashing Algorithms for Data Storage" (PDF).
- Sage A. Weil; et al. "CRUSH: Controlled, Scalable, Decentralized Placement of Replicated Data" (PDF).
- R. J. Honicky, Ethan L. Miller. "Replication Under Scalable Hashing: A Family of Algorithms for Scalable Decentralized Data Distribution" (PDF).
- Ceph. "Crush Maps".
- Yao, Zizhen; Ravishankar, Chinya; Tripathi, Satish (May 13, 2001). Hash-Based Virtual Hierarchies for Caching in Hybrid Content-Delivery Networks (PDF). Riverside, CA: CSE Department, University of California, Riverside. Retrieved 15 November 2015.
- Wang, Wei; Chinya Ravishankar (January 2009). "Hash-Based Virtual Hierarchies for Scalable Location Service in Mobile Ad-hoc Networks". Mobile Networks and Applications. 14 (5): 625–637. doi:10.1007/s11036-008-0144-3.
- Mayank, Anup; Phatak, Trivikram; Ravishankar, Chinya (2006), Decentralized Hash-Based Coordination of Distributed Multimedia Caches (PDF), Proc. 5th IEEE International Conference on Networking (ICN'06), Mauritius: IEEE
- Christian Schindelhauer, Gunnar Schomaker (2005). "Weighted Distributed Hash Tables": 218. CiteSeerX 10.1.1.414.9353. Cite journal requires
|journal=(help)