Preference regression
Preference regression is a statistical technique used by marketers to determine consumers’ preferred core benefits. It usually supplements product positioning techniques like multi dimensional scaling or factor analysis and is used to create ideal vectors on perceptual maps.
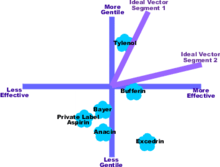
Application
Starting with raw data from surveys, researchers apply positioning techniques to determine important dimensions and plot the position of competing products on these dimensions. Next they regress the survey data against the dimensions. The independent variables are the data collected in the survey. The dependent variable is the preference datum. Like all regression methods, the computer fits weights to best predict data. The resultant regression line is referred to as an ideal vector because the slope of the vector is the ratio of the preferences for the two dimensions.
If all the data is used in the regression, the program will derive a single equation and hence a single ideal vector. This tends to be a blunt instrument so researchers refine the process with cluster analysis. This creates clusters that reflect market segments. Separate preference regressions are then done on the data within each segment. This provides an ideal vector for each segment.
Alternative methods
Self-stated importance method is an alternative method in which direct survey data is used to determine the weightings rather than statistical imputations. A third method is conjoint analysis in which an additive method is used.
See also
References
- Park, S. T.; Chu, W. (2009). "Pairwise preference regression for cold-start recommendation". Proceedings of the third ACM conference on Recommender systems - RecSys '09. p. 21. doi:10.1145/1639714.1639720. ISBN 9781605584355.
- Jarboe, G.R.; McDaniel, C.D.; Gates, R.H. (1992). "Preference regression modeling of multiple option healthcare delivery systems". Journal of Ambulatory Care Marketing, 5(1), p.71-82.