Pipeline (Unix)
In Unix-like computer operating systems, a pipeline is a mechanism for inter-process communication using message passing. A pipeline is a set of processes chained together by their standard streams, so that the output text of each process (stdout) is passed directly as input (stdin) to the next one. The second process is started as the first process is still executing, and they are executed concurrently. The concept of pipelines was championed by Douglas McIlroy at Unix's ancestral home of Bell Labs, during the development of Unix, shaping its toolbox philosophy.[1][2] It is named by analogy to a physical pipeline. A key feature of these pipelines is their "hiding of internals" (Ritchie & Thompson, 1974). This in turn allows for more clarity and simplicity in the system.
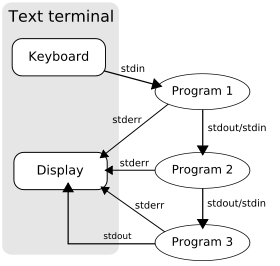
This article is about anonymous pipes, where data written by one process is buffered by the operating system until it is read by the next process, and this uni-directional channel disappears when the processes are completed. This differs from named pipes, where messages are passed to or from a pipe that is named by making it a file, and remains after the processes are completed. The standard shell syntax for anonymous pipes is to list multiple commands, separated by vertical bars ("pipes" in common Unix verbiage):
process1 | process2 | process3
For example, to list files in the current directory (ls), retain only the lines of ls output containing the string "key" (grep), and view the result in a scrolling page (less), a user types the following into the command line of a terminal:
ls -l | grep key | less
"ls -l" produces a process, the output (stdout) of which is piped to the input (stdin) of the process for "grep key"; and likewise for the process for "less". Each process takes input from the previous process and produces output for the next process via standard streams. Each " | " tells the shell to connect the standard output of the command on the left to the standard input of the command on the right by an inter-process communication mechanism called an (anonymous) pipe, implemented in the operating system. Pipes are unidirectional; data flows through the pipeline from left to right.
Pipelines in command line interfaces
All widely used Unix shells have a special syntax construct for the creation of pipelines. In all usage one writes the commands in sequence, separated by the ASCII vertical bar character "|" (which, for this reason, is often called "pipe character"). The shell starts the processes and arranges for the necessary connections between their standard streams (including some amount of buffer storage).
Error stream
By default, the standard error streams ("stderr") of the processes in a pipeline are not passed on through the pipe; instead, they are merged and directed to the console. However, many shells have additional syntax for changing this behavior. In the csh shell, for instance, using "|&" instead of "|" signifies that the standard error stream should also be merged with the standard output and fed to the next process. The Bourne Shell can also merge standard error with |& since bash 4.0[3] or using 2>&1, as well as redirect it to a different file.
Pipemill
In the most commonly used simple pipelines the shell connects a series of sub-processes via pipes, and executes external commands within each sub-process. Thus the shell itself is doing no direct processing of the data flowing through the pipeline.
However, it's possible for the shell to perform processing directly, using a so-called mill or pipemill (since a while command is used to "mill" over the results from the initial command). This construct generally looks something like:
command | while read -r var1 var2 ...; do
# process each line, using variables as parsed into var1, var2, etc
# (note that this may be a subshell: var1, var2 etc will not be available
# after the while loop terminates; some shells, such as zsh and newer
# versions of Korn shell, process the commands to the left of the pipe
# operator in a subshell)
done
Such pipemill may not perform as intended if the body of the loop includes commands, such as cat and ssh, that read from stdin:[4] on the loop's first iteration, such a program (let's call it the drain) will read the remaining output from command, and the loop will then terminate (with results depending on the specifics of the drain). There are a couple of possible ways to avoid this behavior. First, some drains support an option to disable reading from stdin (e.g. ssh -n). Alternatively, if the drain does not need to read any input from stdin to do something useful, it can be given < /dev/null as input.
As all components of a pipe is ran in parallel, a shell typically forks a subprocess (a subshell) to handle its contents, making it impossible to propagate variable changes to the outside shell environment. To remedy this issue, the "pipemill" can instead be fed from a here document containing a command substitution, which waits for the pipeline to finish running before milling through the contents. Alternatively, a named pipe or a process substitution can be used for parallel execution. GNU bash also has a lastpipe option to disable forking for the last pipe component.[5]
Creating pipelines programmatically
Pipelines can be created under program control. The Unix pipe() system call asks the operating system to construct a new anonymous pipe object. This results in two new, opened file descriptors in the process: the read-only end of the pipe, and the write-only end. The pipe ends appear to be normal, anonymous file descriptors, except that they have no ability to seek.
To avoid deadlock and exploit parallelism, the Unix process with one or more new pipes will then, generally, call fork() to create new processes. Each process will then close the end(s) of the pipe that it will not be using before producing or consuming any data. Alternatively, a process might create a new thread and use the pipe to communicate between them.
Named pipes may also be created using mkfifo() or mknod() and then presented as the input or output file to programs as they are invoked. They allow multi-path pipes to be created, and are especially effective when combined with standard error redirection, or with tee.
Implementation
In most Unix-like systems, all processes of a pipeline are started at the same time, with their streams appropriately connected, and managed by the scheduler together with all other processes running on the machine. An important aspect of this, setting Unix pipes apart from other pipe implementations, is the concept of buffering: for example a sending program may produce 5000 bytes per second, and a receiving program may only be able to accept 100 bytes per second, but no data is lost. Instead, the output of the sending program is held in the buffer. When the receiving program is ready to read data, then next program in the pipeline reads from the buffer. In Linux, the size of the buffer is 65,536 bytes (64KiB). An open source third-party filter called bfr is available to provide larger buffers if required.
History
The pipeline concept was invented by Douglas McIlroy[6] and first described in the man pages of Version 3 Unix.[7] McIlroy noticed that much of the time command shells passed the output file from one program as input to another.
His ideas were implemented in 1973 when ("in one feverish night", wrote McIlroy) Ken Thompson added the pipe() system call and pipes to the shell and several utilities in Version 3 Unix. "The next day", McIlroy continued, "saw an unforgettable orgy of one-liners as everybody joined in the excitement of plumbing." McIlroy also credits Thompson with the | notation, which greatly simplified the description of pipe syntax in Version 4.[8][7] The idea was eventually ported to other operating systems, such as DOS, OS/2, Microsoft Windows, and BeOS, often with the same notation.
Although developed independently, Unix pipes are related to, and were preceded by, the 'communication files' developed by Ken Lochner [9] in the 1960s for the Dartmouth Time Sharing System.[10]
In Tony Hoare's communicating sequential processes (CSP) McIlroy's pipes are further developed.[11]
The robot in the icon for Apple's Automator, which also uses a pipeline concept to chain repetitive commands together, holds a pipe in homage to the original Unix concept.
Other operating systems
This feature of Unix was borrowed by other operating systems, such as Taos and MS-DOS, and eventually became the pipes and filters design pattern of software engineering.
See also
- Everything is a file – describes one of the defining features of Unix; pipelines act on "files" in the Unix sense
- Anonymous pipe – a FIFO structure used for interprocess communication
- GStreamer – a pipeline-based multimedia framework
- CMS Pipelines
- Iteratee
- Named pipe – persistent pipes used for interprocess communication
- Process substitution — shell syntax for connecting multiple pipes to a process
- GNU parallel
- Pipeline (computing) – other computer-related pipelines
- Redirection (computing)
- Tee (command) – a general command for tapping data from a pipeline
- XML pipeline – for processing of XML files
- xargs
References
- Mahoney, Michael S. "The Unix Oral History Project: Release.0, The Beginning".
McIlroy: It was one of the only places where I very nearly exerted managerial control over Unix, was pushing for those things, yes.
- http://cm.bell-labs.com/cm/cs/who/dmr/mdmpipe.html%5B%5D
- "Bash release notes". tiswww.case.edu. Retrieved 2017-06-14.
- "Shell Loop Interaction with SSH". 6 March 2012. Archived from the original on 6 March 2012.
- John1024. "How can I store the "find" command results as an array in Bash". Stack Overflow.
- "The Creation of the UNIX Operating System". Bell Labs. Archived from the original on September 14, 2004.
- McIlroy, M. D. (1987). A Research Unix reader: annotated excerpts from the Programmer's Manual, 1971–1986 (PDF) (Technical report). CSTR. Bell Labs. 139.
- http://www.linfo.org/pipe.html Pipes: A Brief Introduction by The Linux Information Project (LINFO)
- http://www.cs.rit.edu/~swm/history/DTSS.doc
- http://cm.bell-labs.com/who/dmr/hist.html%5B%5D
- https://swtch.com/~rsc/thread/ Bell Labs and CSP Threads (Russ Cox)
- Sal Soghoian on MacBreak Episode 3 "Enter the Automatrix"
External links
- History of Unix pipe notation
- Doug McIlroy’s original 1964 memo, proposing the concept of a pipe for the first time
- : create an interprocess channel – System Interfaces Reference, The Single UNIX Specification, Issue 7 from The Open Group
- Pipes: A Brief Introduction by The Linux Information Project (LINFO)
- Unix Pipes – powerful and elegant programming paradigm (Softpanorama)
- Ad Hoc Data Analysis From The Unix Command Line at Wikibooks – Shows how to use pipelines composed of simple filters to do complex data analysis.
- Use And Abuse Of Pipes With Audio Data – Gives an introduction to using and abusing pipes with netcat, nettee and fifos to play audio across a network.
- stackoverflow.com – A Q&A about bash pipeline handling.