Orthogonality principle
In statistics and signal processing, the orthogonality principle is a necessary and sufficient condition for the optimality of a Bayesian estimator. Loosely stated, the orthogonality principle says that the error vector of the optimal estimator (in a mean square error sense) is orthogonal to any possible estimator. The orthogonality principle is most commonly stated for linear estimators, but more general formulations are possible. Since the principle is a necessary and sufficient condition for optimality, it can be used to find the minimum mean square error estimator.
Orthogonality principle for linear estimators
The orthogonality principle is most commonly used in the setting of linear estimation.[1] In this context, let x be an unknown random vector which is to be estimated based on the observation vector y. One wishes to construct a linear estimator for some matrix H and vector c. Then, the orthogonality principle states that an estimator achieves minimum mean square error if and only if


- and


If x and y have zero mean, then it suffices to require the first condition.
Example
Suppose x is a Gaussian random variable with mean m and variance Also suppose we observe a value where w is Gaussian noise which is independent of x and has mean 0 and variance We wish to find a linear estimator minimizing the MSE. Substituting the expression into the two requirements of the orthogonality principle, we obtain







and



Solving these two linear equations for h and c results in

so that the linear minimum mean square error estimator is given by

This estimator can be interpreted as a weighted average between the noisy measurements y and the prior expected value m. If the noise variance is low compared with the variance of the prior (corresponding to a high SNR), then most of the weight is given to the measurements y, which are deemed more reliable than the prior information. Conversely, if the noise variance is relatively higher, then the estimate will be close to m, as the measurements are not reliable enough to outweigh the prior information.


Finally, note that because the variables x and y are jointly Gaussian, the minimum MSE estimator is linear.[2] Therefore, in this case, the estimator above minimizes the MSE among all estimators, not only linear estimators.
General formulation
Let be a Hilbert space of random variables with an inner product defined by . Suppose is a closed subspace of , representing the space of all possible estimators. One wishes to find a vector which will approximate a vector . More accurately, one would like to minimize the mean squared error (MSE) between and .







In the special case of linear estimators described above, the space is the set of all functions of and , while is the set of linear estimators, i.e., linear functions of only. Other settings which can be formulated in this way include the subspace of causal linear filters and the subspace of all (possibly nonlinear) estimators.

Geometrically, we can see this problem by the following simple case where is a one-dimensional subspace:
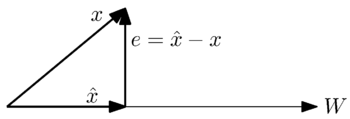
We want to find the closest approximation to the vector by a vector in the space . From the geometric interpretation, it is intuitive that the best approximation, or smallest error, occurs when the error vector, , is orthogonal to vectors in the space .

More accurately, the general orthogonality principle states the following: Given a closed subspace of estimators within a Hilbert space and an element in , an element achieves minimum MSE among all elements in if and only if for all


Stated in such a manner, this principle is simply a statement of the Hilbert projection theorem. Nevertheless, the extensive use of this result in signal processing has resulted in the name "orthogonality principle."
A solution to error minimization problems
The following is one way to find the minimum mean square error estimator by using the orthogonality principle.
We want to be able to approximate a vector by

where

is the approximation of as a linear combination of vectors in the subspace spanned by Therefore, we want to be able to solve for the coefficients, , so that we may write our approximation in known terms.


By the orthogonality theorem, the square norm of the error vector, , is minimized when, for all j,


Developing this equation, we obtain

If there is a finite number of vectors , one can write this equation in matrix form as



Assuming the are linearly independent, the Gramian matrix can be inverted to obtain

thus providing an expression for the coefficients of the minimum mean square error estimator.
Notes
- Kay, p.386
- See the article minimum mean square error.
References
- Kay, S. M. (1993). Fundamentals of Statistical Signal Processing: Estimation Theory. Prentice Hall. ISBN 0-13-042268-1.
- Moon, Todd K. (2000). "Mathematical Methods and Algorithms for Signal Processing". Prentice-Hall. ISBN 0-201-36186-8. Cite journal requires
|journal=(help)