Multifidelity simulation
Multifidelity methods leverage both low- and high-fidelity data in order to maximize the accuracy of model estimates, while minimizing the cost associated with parametrization. They have been successfully used in wing-design optimization[2], robotic learning [3], and have more recently been extended to human-in-the-loop systems, such as aerospace [4] and transportation. [5] They include both model-based methods, where a generative model is available or can be learned, in addition to model-free methods, that include regression-based approaches, such as stacked-regression. [4] The approach used depends on the domain and properties of the data available, and is similar to the concept of metasynthesis, proposed by Judea Pearl. [6]
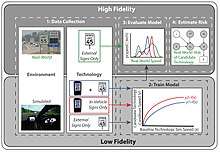 Multifidelity Simulation Methods for Transportation[1] | |
| Class | |
|---|---|
| Data structure | Low- and high-fidelity data |
| Worst-case performance | Not defined |
| Worst-case space complexity | Not defined |
Data fidelity spectrum

The fidelity of data can vary along a spectrum between low- and high-fidelity. The next sections provide examples of data across the fidelity spectrum, while defining the benefits and limitations of each type of data.
Low fidelity data (LoFi)
Low-fidelity data (LoFi) includes any data that was produced by a person or Stochastic Process that deviates from the real-world system of interest. For example, LoFi data can be produced by models of a physical system that use approximations to simulate the system, rather than modeling the system in an exhaustive manner.[2]
Moreover, in human-in-the-loop (HITL) situations the goal may be to predict the impact of technology on expert behavior within the real-world operational context. Machine learning can be used to train statistical models that predict expert behavior, provided that an adequate amount of high-fidelity (i.e., real-world) data are available or can be produced.[4]
LoFi benefits and limitations
In situations when there is not an adequate amount of high-fidelity data available to train the model, low-fidelity data can sometimes be used. For example, low-fidelity data can be acquired by using a distributed simulation platform, such as X-Plane, and requiring novice participants to operate in scenarios that are approximations of the real-world context. The benefit of using low-fidelity data is that they are relatively inexpensive to acquire, so it is possible to elicit larger amounts of data. However, the limitation is that the low-fidelity data may not be useful for predicting real-world expert (i.e., high-fidelity) performance due to differences between the low-fidelity simulation platform and the real-world context, or between novice and expert performance (e.g., due to training).[4][5]
High-fidelity data (HiFi)
High-fidelity data (HiFi) includes data that was produced by a person or Stochastic Process that closely matches the operational context of interest. For example, in wing design optimization, high-fidelity data uses physical models in simulation that produce results that closely match the wing in a similar real-world setting.[2] In HITL situations, HiFi data would be produced from an operational expert acting in the technological and situational context of interest.[5]
HiFi benefits and limitations
An obvious benefit of utilizing high-fidelity data is that the estimates produced by the model should generalize well to the real-world context. However, these data are expensive in terms of both time and money, which limits the amount of data that can be obtained. The limited amount of data available can significantly impair the ability of the model to produce valid estimates.[4]
Multifidelity methods (MfM)
Multifidelity methods attempt to leverage the strengths of each data source, while overcoming the limitations. Although small to medium differences between low- and high-fidelity data are sometimes able to be overcome by multifidelity models, large differences (e.g., in KL divergence between novice and expert action distributions) can be problematic leading to decreased predictive performance when compared to models that exclusively relied on high-fidelity data.[4]
Multifidelity models enable low-fidelity data to be collected on different technology concepts to evaluate the risk associated with each concept before actually deploying the system.[7]
References
- Erik J. Schlicht (2017). "SAMSI Summer Program on Transportation Statistics: Erik Schlicht, Aug 15, 2017". Using Multifidelity Methods to Estimate the Risk Associated with Transportation Systems.
- Robinson, T.D.; et, al (2006). "Multifidelity Optimization for Variable-Complexity Design". 11th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference: 1–18.
- Cutler, M.; et, al (2015). "Real-world reinforcement learning via multifidelity simulators". IEEE Transactions on Robotics: 655–671.
- Schlicht, Erik (2014). "Predicting the behavior of interacting humans by fusing data from multiple sources". arXiv:1408.2053 [cs.AI].
- Schlicht, Erik J; Morris, Nichole L (2017). "Estimating the risk associated with transportation technology using multifidelity simulation". arXiv:1701.08588 [stat.AP].
- Judea Pearl (2012). "The Do-Calculus Revisited". Proceedings of the Twenty-Eighth Conference on Uncertainty in Artificial Intelligence (PDF). Corvallis, OR: AUAI Press. pp. 4–11.
- Reshama Shaikh and Erik J. Schlicht (2017). "The Machine Learning Conference Interview with Dr. Schlicht". Interview Regarding the use of Multifidelity Simulation Methods.