Multi-focus image fusion
Overview
In recent years, image fusion has been used in many varieties of applications such as remote sensing, surveillance, medical diagnosis, and photography applications. The two major application examples of image fusion in the photography applications are fusion of multi-focus images and multi-exposure images[1][2]. The main idea of image fusion is gathering important and the essential information from the input images into one image which that single image has ideally all of this information of the input images[1][3][4][5]. The research’s history of image fusion is over 30 years with many scientific papers[2][6]. The study of image fusion generally contains two aspects: image fusion methods and objective evaluation metrics [6].

Multi-focus image fusion is a multiple image compression technique using input images with different focus depths to make an output image that preserves information. In visual sensor network (VSN), sensors are cameras which record images and video sequences. In many applications of VSN, a camera can't give a perfect illustration including all details of the scene. This is because of the limited depth of focus exists in the optical lens of cameras Therefore, just the object located in the focal length of camera is focused and cleared and the other parts of image are blurred. VSN has an ability to capture images with different depth of focuses in the scene using several cameras. Due to the large amount of data generated by camera compared to other sensors such as pressure and temperature sensors and some limitation such as limited band width, energy consumption and processing time, it is essential to process the local input images to decrease the amount of transmission data. The aforementioned reasons emphasize the necessary of multi-focus images fusion. Multi-focus image fusion is a process which combines the input multi-focus images into a single image including all important information of the input images and it's more accurate explanation of the scene than every single input image[5].
Vast researches for multi-focus image fusion have been done in the recent years and can be classified into two categories of transform and spatial domains. Common used transforms for image fusion are Discrete Cosine Transform (DCT) and Multi-Scale Transform (MST) [2] [7]. Recently, Deep Learning (DL) has been thriving in several image processing and computer vision applications. That is why DL based methods have been an attractive scientific discussion in image fusion researches[1][3][8].
Multi-Focus image fusion in Spatial domain
Huang and Jing have reviewed and applied several focus measurements in the spatial domain for the multi-focus image fusion process, which are suitable for real-time applications. They mentioned some focus measurements including variance, energy of image gradient (EOG), Tenenbaum‟s algorithm (Tenengrad), energy of Laplacian of the image (EOL), sum-modified-Laplacian (SML), and spatial frequency (SF). Their conducted experiments showed that EOL of the image gave results with a better performance than the other methods like variance and spatial frequency [9][5].
Multi-Focus image fusion in Multi-Scale Transform and DCT domain
Image fusion based on the multi-scale transform is the most commonly used and very promising technique. Laplacian pyramid transform, gradient pyramid-based transform, morphological pyramid transform and the premier ones, discrete wavelet transform, shift-invariant wavelet transform (SIDWT), and discrete cosine harmonic wavelet transform (DCHWT) are some examples of the image fusion methods based on the multi-scale transform [2] [5] [7]. These methods are complex and have some limitations e.g. processing time and energy consumption. For example, the multi-focus image fusion methods based on DWT require a lot of convolution operations, so it takes more time and energy for processing. Therefore, most of methods used in the multi-scale transform are not suitable for performing in real-time applications [7][5]. Moreover, these methods are not very successful in edge places due to missing the edges of the image in the wavelet transform process. However, they create ringing artefacts in the output image and reduce its quality. Due to the aforementioned problems in the multi-scale transform methods, researchers are interested in multi-focus image fusion in the discrete cosine transform (DCT) domain. The DCT-based methods are more efficient in terms of transmission and archiving images coded in Joint Photographic Experts Group (JPEG) standard to the upper node in the VSN agent. A JPEG system consists of a pair of encoder and decoder. In the encoder, images are divided into non-overlapping 8×8 blocks, and the DCT coefficients are calculated for each one of them. Since the quantization of DCT coefficients is a lossy process, many of the small-valued DCT coefficients are quantized to zero, which correspond to high frequencies. The DCT-based image fusion algorithms work more properly when the multi-focus image fusion methods are applied in the compressed domain[7][5]. In addition, in the spatial-based methods, the input images must be decoded and then transferred to the spatial domain. After implementation of the image fusion operations, the output fused images must again be encoded. Therefore, the DCT domain-based methods do not require complex and time-consuming consecutive decoding and encoding operations. Therefore, the image fusion methods based on DCT domain operate with an extremely less energy and processing time[7][5]. Recently, a lot of research works have been carried out in the DCT domain. DCT+Variance, DCT+Corr_Eng, DCT+EOL, and DCT+VOL are some prominent example in DCT based methods [5][7].
Multi-Focus image fusion using Deep Learning
Nowadays, the deep learning is utilized in image fusion applications such as multi-focus image fusion. Liu et al. were the first researchers that used CNN for multi-focus image fusion. They used the Siamese architecture for comparing the focused and unfocused patches[4]. C. Du et al. submitted MSCNN method that obtains the initial segmented decision map with image segmentation between the focused and unfocused patches through the multi-scale convolution neural network[10]. H. Tang et al. introduced the pixel-wise convolution neural network (p-CNN) for classification of the focused and unfocused patches [11]. All of these CNN based multi-focus image fusion methods have enhanced the decision map. Nevertheless, their initial segmented decision maps have a lot of weakness and errors. Therefore, satisfaction of their final fusion decision map depends to use vast post-processing algorithms such as Consistency Verification (CV), morphological operations, watershed, guiding filters, and small region removal on the initial segmented decision map. Along with the CNN based multi-focus image fusion methods, fully convolutional network (FCN) is also utilized in multi-focus image fusion[8][12].
ECNN: Ensemble of CNN for Multi-Focus Image Fusion[1]

The Convolutional Neural Networks (CNNs) based multi-focus image fusion methods have recently attracted enormous attention. They greatly enhanced the constructed decision map compared with the previous state of the art methods that have been done in the spatial and transform domains. Nevertheless, these methods have not reached to the satisfactory initial decision map, and they need to undergo vast post-processing algorithms to achieve a satisfactory decision map. In the method of ECNN, a novel CNNs based method with the help of the ensemble learning is proposed. It is very reasonable to use various models and datasets rather than just one. The ensemble learning based methods intend to pursue increasing diversity among the models and datasets in order to decrease the problem of the overfitting on the training dataset. It is obvious that the results of an ensemble of CNNs are better than just one single CNNs. Also, the proposed method introduces a new simple type of multi-focus images dataset. It simply changes the arranging of the patches of the multi-focus datasets, which is very useful for obtaining the better accuracy. With this new type arrangement of datasets, the three different datasets including the original and the Gradient in directions of vertical and horizontal patches are generated from the COCO dataset. Therefore, the proposed method introduces a new network that three CNNs models which have been trained on three different created datasets to construct the initial segmented decision map. These ideas greatly improve the initial segmented decision map of the proposed method which is similar, or even better than, the other final decision map of CNNs based methods obtained after applying many post-processing algorithms. Many real multi-focus test images are used in our experiments, and the results are compared with quantitative and qualitative criteria. The obtained experimental results indicate that the proposed CNNs based network is more accurate and have the better decision map without post-processing algorithms than the other existing state of the art multi-focus fusion methods which used many post-processing algorithms.
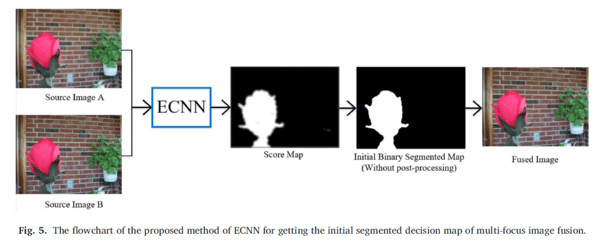
This method introduces a new network for achieving the cleaner initial segmented decision map compared with the others. The pro- posed method introduces a new architecture which uses an ensemble of three Convolutional Neural Networks (CNNs) trained on three different datasets. Also, the proposed method prepares a new simple type of multi- focus image datasets for achieving the better fusion performance than the other popular multi-focus image datasets. This idea is very helpful to achieve the better initial segmented decision map, which is the same or even better than the others initial segmented decision map by using vast post-processing algorithms. The source code of ECNN is available in http://amin-naji.com/publications/ and https://github.com/mostafaaminnaji/ECNN

References
- Amin-Naji, Mostafa; Aghagolzadeh, Ali; Ezoji, Mehdi (2019). "Ensemble of CNN for multi-focus image fusion". Information Fusion. 51: 201–214. doi:10.1016/j.inffus.2019.02.003. ISSN 1566-2535.
- Li, Shutao; Kang, Xudong; Fang, Leyuan; Hu, Jianwen; Yin, Haitao (2017-01-01). "Pixel-level image fusion: A survey of the state of the art". Information Fusion. 33: 100–112. doi:10.1016/j.inffus.2016.05.004. ISSN 1566-2535.
- Amin-Naji, Mostafa; Aghagolzadeh, Ali; Ezoji, Mehdi (2019). "CNNs hard voting for multi-focus image fusion". Journal of Ambient Intelligence and Humanized Computing. 11 (4): 1749–1769. doi:10.1007/s12652-019-01199-0. ISSN 1868-5145.
- Liu, Yu; Chen, Xun; Peng, Hu; Wang, Zengfu (2017-07-01). "Multi-focus image fusion with a deep convolutional neural network". Information Fusion. 36: 191–207. doi:10.1016/j.inffus.2016.12.001. ISSN 1566-2535.
- Amin-Naji, Mostafa; Aghagolzadeh, Ali (2018). "Multi-Focus Image Fusion in DCT Domain using Variance and Energy of Laplacian and Correlation Coefficient for Visual Sensor Networks". Journal of AI and Data Mining. 6 (2): 233–250. doi:10.22044/jadm.2017.5169.1624. ISSN 2322-5211.
- Liu, Yu; Chen, Xun; Wang, Zengfu; Wang, Z. Jane; Ward, Rabab K.; Wang, Xuesong (2018-07-01). "Deep learning for pixel-level image fusion: Recent advances and future prospects". Information Fusion. 42: 158–173. doi:10.1016/j.inffus.2017.10.007. ISSN 1566-2535.
- Haghighat, Mohammad Bagher Akbari; Aghagolzadeh, Ali; Seyedarabi, Hadi (2011-09-01). "Multi-focus image fusion for visual sensor networks in DCT domain". Computers & Electrical Engineering. Special Issue on Image Processing. 37 (5): 789–797. doi:10.1016/j.compeleceng.2011.04.016. ISSN 0045-7906.
- Amin-Naji, Mostafa; Aghagolzadeh, Ali; Ezoji, Mehdi (2018). "Fully Convolutional Networks for Multi-Focus Image Fusion". 2018 9th International Symposium on Telecommunications (IST): 553–558. doi:10.1109/ISTEL.2018.8660989. ISBN 978-1-5386-8274-6.
- Huang, Wei; Jing, Zhongliang (2007-03-01). "Evaluation of focus measures in multi-focus image fusion". Pattern Recognition Letters. 28 (4): 493–500. doi:10.1016/j.patrec.2006.09.005. ISSN 0167-8655.
- Du, C.; Gao, S. (2017). "Image Segmentation-Based Multi-Focus Image Fusion Through Multi-Scale Convolutional Neural Network". IEEE Access. 5: 15750–15761. doi:10.1109/ACCESS.2017.2735019.
- Tang, Han; Xiao, Bin; Li, Weisheng; Wang, Guoyin (2018-04-01). "Pixel convolutional neural network for multi-focus image fusion". Information Sciences. 433-434: 125–141. doi:10.1016/j.ins.2017.12.043. ISSN 0020-0255.
- Guo, Xiaopeng; Nie, Rencan; Cao, Jinde; Zhou, Dongming; Qian, Wenhua (2018-06-12). "Fully Convolutional Network-Based Multifocus Image Fusion". Neural Computation. 30 (7): 1775–1800. doi:10.1162/neco_a_01098. ISSN 0899-7667. PMID 29894654.