Kolyuchin Bay
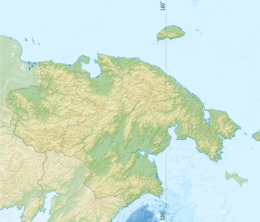
Kolyuchin Bay (Russian: Колючинская губа; Kolyuchinskaya guba) is a large bay in the Chukchi Sea on the northern shore of the Chukotka Peninsula, Russia.
| Kolyuchin Bay | |
|---|---|
 Kolyuchin Bay Location of Kolyuchin Bay in the Chukotka Autonomous Okrug | |
 | |
| Location | Far North |
| Coordinates | 66.83333°N 174.4°W |
| Native name | Колючинская губа (Russian) |
| River sources | Ioniveyem and Ulyuveyem |
| Ocean/sea sources | Chukchi Sea |
| Basin countries | Russia |
| Max. length | 100 km (62 mi) |
| Max. width | 37 km (23 mi) |
| Average depth | 14 m (46 ft) |
Administratively this bay belongs to the Chukotka Autonomous Okrug of the Russian Federation.
Geography
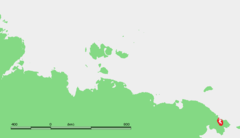
To the west is Cape Vankarem and to the east Neskynpil'gyn Lagoon and Cape Serdtse-Kamen. The length of the bay is 100 km. Its mouth is only 2.8 km because of the Serykh Gusey Islands and the Belyaka Spit (Kosa Belyaka), separate it from the Arctic Ocean. The width increases to 37 km as it goes southwards and inland.
The depth of Kolyuchinskaya Bay is 7 to 14 m. The bay is covered with ice most of the year.
This bay has an inlet in its southern end known as the Kuetkuyyim Inlet (Kuetkuyyim Zaliv). The Ioniveyem and the Ulyuveyem River flow into it from the south.
History
In 1793, the bay was named Count Bezborodko Bay in honor of Russian statesman Alexander Bezborodko.[1] The locals could not get accustomed to this name and the bay was later renamed Kolyuchinskaya after nearby Kolyuchin Island.
References
- Леонтьев В. В., Новикова К. А. Топонимический словарь северо-востока СССР. — Магадан: Магаданское книжное издательство, 1989. — С. 199.