Information dimension
In information theory, information dimension is an information measure for random vectors in Euclidean space, based on the normalized entropy of finely quantized versions of the random vectors. This concept was first introduced by Alfréd Rényi in 1959.[1]
Simply speaking, it is a measure of the fractal dimension of a probability distribution. It characterizes the growth rate of the Shannon entropy given by successively finer discretizations of the space.
In 2010, Wu and Verdú gave an operational characterization of Rényi information dimension as the fundamental limit of almost lossless data compression for analog sources under various regularity constraints of the encoder/decoder.
Definition and Properties
The entropy of a discrete random variable is


where is the probability measure of when , and the denotes a set .




Let be an arbitrary real-valued random variable. Given a positive integer , we create a new discrete random variable



where the is the floor operator which converts a real number to the greatest integer less than it. Then


and

are called lower and upper information dimensions of respectively. When , we call this value information dimension of ,


Some important properties of information dimension :

- If the mild condition is fulfilled, we have .
- For an -dimensional random vector , the first property can be generalized to .
- It is sufficient to calculate the upper and lower information dimensions when restricting to the exponential subsequence .
- and are kept unchanged if rounding or ceiling functions are used in quantization.








-Dimensional Entropy

If the information dimension exists, one can define the -dimensional entropy of this distribution by

provided the limit exists. If , the zero-dimensional entropy equals the standard Shannon entropy . For integer dimension , the -dimensional entropy is the -fold integral defining the respective differential entropy.



Discrete-Continuous Mixture Distributions
According to Lebesgue decomposition theorem,[2] a probability distribution can be uniquely represented by the mixture

where and ; is a purely atomic probability measure (discrete part), is the absolutely continuous probability measure, and is a probability measure singular with respect to Lebesgue measure but with no atoms (singular part). Let be a random variable such that . Assume the distribution of can be represented as






where is a discrete measure and is the absolutely continuous probability measure with . Then


Moreover, given and differential entropy , the -Dimensional Entropy is simply given by



where is the Shannon entropy of a discrete random variable with and and given by




Example
Consider a signal which has a Gaussian probability distribution.
We pass the signal through a half-wave rectifier which converts all negative value to 0, and maintains all other values. The half-wave rectifier can be characterized by the function

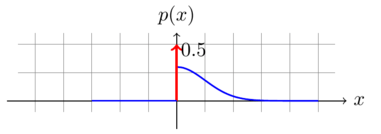
Then, at the output of the rectifier, the signal has a rectified Gaussian distribution. It is characterized by an atomic mass of weight 0.5 and has a Gaussian PDF for all .

With this mixture distribution, we apply the formula above and get the information dimension of the distribution and calculate the -dimensional entropy.

The normalized right part of the zero-mean Gaussian distribution has entropy , hence


Connection to Differential Entropy
It is shown [3] that information dimension and differential entropy are tightly connected.
Let be a positive random variable with density .

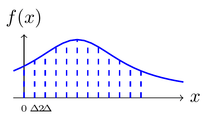
Suppose we divide the range of into bins of length . By the mean value theorem, there exists a value within each bin such that



Consider the discretized random variable if .


_which_has_already_been_quantized_to_several_dirac_function.png)
The probability of each support point is

The entropy of this variable is

If we set and then we are doing exactly the same quantization as the definition of information dimension. Since relabeling the events of a discrete random variable does not change its entropy, we have



This yields

and when is sufficient large,

which is the differential entropy of the continuous random variable. In particular, if is Riemann integrable, then


Comparing this with the -dimensional entropy shows that the differential entropy is exactly the one-dimensional entropy

In fact, this can be generalized to higher dimensions. Rényi shows that, if is a random vector in a -dimensional Euclidean space with an absolutely continuous distribution with a probability density function and finite entropy of the integer part (), we have




and

if the integral exist.
Lossless data compression
The information dimension of a distribution gives a theoretical upper bound on the compression rate, if one wants to compress a variable coming from this distribution. In the context of lossless data compression, we try to compress real number with less real number which both have infinite precision.
The main objective of the lossless data compression is to find efficient representations for source realizations by . A code for is a pair of mappings:




- encoder: which converts information from a source into symbols for communication or storage;
- decoder: is the reverse process, converting code symbols back into a form that the recipient understands.


The block error probability is .

Define to be the infimum of such that there exists a sequence of codes such that for all sufficiently large .




So basically gives the ratio between the code length and the source length, it shows how good a specific encoder decoder pair is. The fundamental limits in lossless source coding are as follows.[4]
Consider a continuous encoder function with its continuous decoder function . If we impose no regularity on and , due to the rich structure of , we have the minimum -achievable rate for all . It means that one can build an encoder-decoder pair with infinity compression rate.







In order to get some nontrivial and meaningful conclusions, let the minimum achievable rate for linear encoder and Borel decoder. If random variable has a distribution which is a mixture of discrete and continuous part. Then for all Suppose we restrict the decoder to be a Lipschitz continuous function and holds, then the minimum achievable rate for all .





Notes
- See Rényi 1959.
- See Çınlar 2011.
- See Cover & Thomas 2012.
- See Wu & Verdu 2010.
References
- Çınlar, Erhan (2011). Probability and Stochastics. Graduate Texts in Mathematics. 261. Springer. doi:10.1007/978-0-387-87859-1. ISBN 978-0-387-87858-4.CS1 maint: ref=harv (link)
- Cover, Thomas M.; Thomas, Joy A. (2012). Elements of Information Theory (2nd ed.). Wiley. ISBN 9781118585771.CS1 maint: ref=harv (link)
- Rényi, A. (March 1959). "On the dimension and entropy of probability distributions". Acta Mathematica Academiae Scientiarum Hungaricae. 10 (1–2): 193–215. doi:10.1007/BF02063299. ISSN 0001-5954.CS1 maint: ref=harv (link)
- Wu, Yihong; Verdu, S. (August 2010). "Rényi Information Dimension: Fundamental Limits of Almost Lossless Analog Compression". IEEE Transactions on Information Theory. 56 (8): 3721–3748. doi:10.1109/TIT.2010.2050803. ISSN 0018-9448.CS1 maint: ref=harv (link)