Hopscotch hashing
Hopscotch hashing is a scheme in computer programming for resolving hash collisions of values of hash functions in a table using open addressing. It is also well suited for implementing a concurrent hash table. Hopscotch hashing was introduced by Maurice Herlihy, Nir Shavit and Moran Tzafrir in 2008.[1] The name is derived from the sequence of hops that characterize the table's insertion algorithm.
The algorithm uses a single array of n buckets. For each bucket, its neighborhood is a small collection of H consecutive buckets (i.e. ones with indices close to the original hashed bucket). The desired property of the neighborhood is that the cost of finding an item in the buckets of the neighborhood is close to the cost of finding it in the bucket itself (for example, by having buckets in the neighborhood fall within the same cache line). The size of the neighborhood must be sufficient to accommodate a logarithmic number of items in the worst case (i.e. it must accommodate log(n) items), but only a constant number on average. If some bucket's neighborhood is filled, the table is resized.
In hopscotch hashing, as in cuckoo hashing, and unlike in linear probing, a given item will always be inserted-into and found-in the neighborhood of its hashed bucket. In other words, it will always be found either in its original hashed array entry, or in one of the next H−1 neighboring entries. H could, for example, be 32, a common machine word size. The neighborhood is thus a "virtual" bucket that has fixed size and overlaps with the following H−1 buckets. To speed the search, each bucket (array entry) includes a "hop-information" word, an H-bit bitmap that indicates which of the next H−1 entries contain items that hashed to the current entry's virtual bucket. In this way, an item can be found quickly by looking at the word to see which entries belong to the bucket, and then scanning through the constant number of entries (most modern processors support special bit manipulation operations that make the lookup in the "hop-information" bitmap very fast).
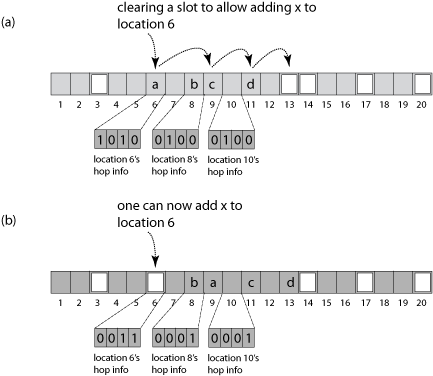
Here is how to add item x which was hashed to bucket i:
- If the hop-information word for bucket i shows there are already H items in this bucket, the table is full; expand the hash table and try again.
- Starting at entry i, use a linear probe to find an empty entry at index j. (If no empty slot exists, the table is full.)
- While (j−i) mod n ≥ H, move the empty slot toward i as follows:
- Search the H−1 slots preceding j for an item y whose hash value k is within H−1 of j, i.e. (j−k) mod n < H. (This can be done using the hop-information words.)
- If no such item y exists within the range, the table is full.
- Move y to j, creating a new empty slot closer to i.
- Set j to the empty slot vacated by y and repeat.
- Store x in slot j and return.
The idea is that hopscotch hashing "moves the empty slot towards the desired bucket". This distinguishes it from linear probing which leaves the empty slot where it was found, possibly far away from the original bucket, or from cuckoo hashing which, in order to create a free bucket, moves an item out of one of the desired buckets in the target arrays, and only then tries to find the displaced item a new place.
To remove an item from the table, one simply removes it from the table entry. If the neighborhood buckets are cache aligned, then one could apply a reorganization operation in which items are moved into the now vacant location in order to improve alignment.
One advantage of hopscotch hashing is that it provides good performance at very high table load factors, even ones exceeding 0.9. Part of this efficiency is due to using a linear probe only to find an empty slot during insertion, not for every lookup as in the original linear probing hash table algorithm. Another advantage is that one can use any hash function, in particular simple ones that are close to universal.
See also
- Cuckoo hashing
- Hash collision
- Hash function
- Linear probing
- Open addressing
- Perfect hashing
- Quadratic probing
References
- Herlihy, Maurice; Shavit, Nir; Tzafrir, Moran (2008). "Hopscotch Hashing" (PDF). DISC '08: Proceedings of the 22nd international symposium on Distributed Computing. Arcachon, France: Springer-Verlag. pp. 350–364.
External links
- libhhash - a C hopscotch hashing implementation
- hopscotch-map - a C++ implementation of a hash map using hopscotch hashing
- Goossaert, Emmanuel (11 August 2013). "Hopscotch hashing". Retrieved 16 October 2019. A detailed description and example implementation.