Hopcroft–Karp algorithm
In computer science, the Hopcroft–Karp algorithm (sometimes more accurately called the Hopcroft–Karp–Karzanov algorithm)[1] is an algorithm that takes as input a bipartite graph and produces as output a maximum cardinality matching – a set of as many edges as possible with the property that no two edges share an endpoint. It runs in time in the worst case, where is set of edges in the graph, is set of vertices of the graph, and it is assumed that . In the case of dense graphs the time bound becomes , and for sparse random graphs it runs in near-linear (in |E|) time.





| Class | Graph algorithm |
|---|---|
| Data structure | Graph |
| Worst-case performance | |
| Worst-case space complexity |


The algorithm was found by John Hopcroft and Richard Karp (1973) and independently by Alexander Karzanov (1973).[2] As in previous methods for matching such as the Hungarian algorithm and the work of Edmonds (1965), the Hopcroft–Karp algorithm repeatedly increases the size of a partial matching by finding augmenting paths. These paths are sequences of edges of the graph, which alternate between edges in the matching and edges out of the partial matching, and where the initial and final edge are not in the partial matching. Finding an augmenting path allows us to increment the size of the partial matching, by simply toggling the edges of the augmenting path (putting in the partial matching those that were not, and vice versa). Simpler algorithms for bipartite matching, such as the Ford–Fulkerson algorithm‚ find one augmenting path per iteration: the Hopkroft-Karp algorithm instead finds a maximal set of shortest augmenting paths, so as to ensure that only iterations are needed instead of iterations. The same performance of can be achieved to find maximum cardinality matchings in arbitrary graphs, with the more complicated algorithm of Micali and Vazirani[3].

The Hopcroft–Karp algorithm can be seen as a special case of Dinic's algorithm for the maximum flow problem.[4]
Augmenting paths
A vertex that is not the endpoint of an edge in some partial matching is called a free vertex. The basic concept that the algorithm relies on is that of an augmenting path, a path that starts at a free vertex, ends at a free vertex, and alternates between unmatched and matched edges within the path. It follows from this definition that, except for the endpoints, all other vertices (if any) in augmenting path must be non-free vertices. An augmenting path could consist of only two vertices (both free) and single unmatched edge between them.

If is a matching, and is an augmenting path relative to , then the symmetric difference of the two sets of edges, , would form a matching with size . Thus, by finding augmenting paths, an algorithm may increase the size of the matching.



Conversely, suppose that a matching is not optimal, and let be the symmetric difference where is an optimal matching. Because and are both matchings, every vertex has degree at most 2 in . So must form a collection of disjoint cycles, of paths with an equal number of matched and unmatched edges in , of augmenting paths for , and of augmenting paths for ; but the latter is impossible because is optimal. Now, the cycles and the paths with equal numbers of matched and unmatched vertices do not contribute to the difference in size between and , so this difference is equal to the number of augmenting paths for in . Thus, whenever there exists a matching larger than the current matching , there must also exist an augmenting path. If no augmenting path can be found, an algorithm may safely terminate, since in this case must be optimal.


An augmenting path in a matching problem is closely related to the augmenting paths arising in maximum flow problems, paths along which one may increase the amount of flow between the terminals of the flow. It is possible to transform the bipartite matching problem into a maximum flow instance, such that the alternating paths of the matching problem become augmenting paths of the flow problem.[5] In fact, a generalization of the technique used in Hopcroft–Karp algorithm to arbitrary flow networks is known as Dinic's algorithm.
Algorithm
The algorithm may be expressed in the following pseudocode.
- Input: Bipartite graph
- Output: Matching
- repeat
- maximal set of vertex-disjoint shortest augmenting paths
- until






In more detail, let and be the two sets in the bipartition of , and let the matching from to at any time be represented as the set . The algorithm is run in phases. Each phase consists of the following steps.


- A breadth-first search partitions the vertices of the graph into layers. The free vertices in are used as the starting vertices of this search and form the first layer of the partitioning. At the first level of the search, there are only unmatched edges, since the free vertices in are by definition not adjacent to any matched edges. At subsequent levels of the search, the traversed edges are required to alternate between matched and unmatched. That is, when searching for successors from a vertex in , only unmatched edges may be traversed, while from a vertex in only matched edges may be traversed. The search terminates at the first layer where one or more free vertices in are reached.
- All free vertices in at layer are collected into a set . That is, a vertex is put into if and only if it ends a shortest augmenting path.
- The algorithm finds a maximal set of vertex disjoint augmenting paths of length . (Maximal means that no more such paths can be added. This is different from finding the maximum number of such paths, which would be harder to do. Fortunately, it is sufficient here to find a maximal set of paths.) This set may be computed by depth first search (DFS) from to the free vertices in , using the breadth first layering to guide the search: the DFS is only allowed to follow edges that lead to an unused vertex in the previous layer, and paths in the DFS tree must alternate between matched and unmatched edges. Once an augmenting path is found that involves one of the vertices in , the DFS is continued from the next starting vertex. Any vertex encountered during the DFS can immediately be marked as used, since if there is no path from it to at the current point in the DFS, then that vertex can't be used to reach at any other point in the DFS. This ensures running time for the DFS. It is also possible to work in the other direction, from free vertices in to those in , which is the variant used in the pseudocode.
- Every one of the paths found in this way is used to enlarge .




The algorithm terminates when no more augmenting paths are found in the breadth first search part of one of the phases.
Analysis
Each phase consists of a single breadth first search and a single depth first search. Thus, a single phase may be implemented in time. Therefore, the first phases, in a graph with vertices and edges, take time .



Each phase increases the length of the shortest augmenting path by at least one: the phase finds a maximal set of augmenting paths of the given length, so any remaining augmenting path must be longer. Therefore, once the initial phases of the algorithm are complete, the shortest remaining augmenting path has at least edges in it. However, the symmetric difference of the eventual optimal matching and of the partial matching M found by the initial phases forms a collection of vertex-disjoint augmenting paths and alternating cycles. If each of the paths in this collection has length at least , there can be at most paths in the collection, and the size of the optimal matching can differ from the size of by at most edges. Since each phase of the algorithm increases the size of the matching by at least one, there can be at most additional phases before the algorithm terminates.
Since the algorithm performs a total of at most phases, it takes a total time of in the worst case.

In many instances, however, the time taken by the algorithm may be even faster than this worst case analysis indicates. For instance, in the average case for sparse bipartite random graphs, Bast et al. (2006) (improving a previous result of Motwani 1994) showed that with high probability all non-optimal matchings have augmenting paths of logarithmic length. As a consequence, for these graphs, the Hopcroft–Karp algorithm takes phases and total time.


Comparison with other bipartite matching algorithms
For sparse graphs, the Hopcroft–Karp algorithm continues to have the best known worst-case performance, but for dense graphs () a more recent algorithm by Alt et al. (1991) achieves a slightly better time bound, . Their algorithm is based on using a push-relabel maximum flow algorithm and then, when the matching created by this algorithm becomes close to optimum, switching to the Hopcroft–Karp method.


Several authors have performed experimental comparisons of bipartite matching algorithms. Their results in general tend to show that the Hopcroft–Karp method is not as good in practice as it is in theory: it is outperformed both by simpler breadth-first and depth-first strategies for finding augmenting paths, and by push-relabel techniques.[6]
Non-bipartite graphs
The same idea of finding a maximal set of shortest augmenting paths works also for finding maximum cardinality matchings in non-bipartite graphs, and for the same reasons the algorithms based on this idea take phases. However, for non-bipartite graphs, the task of finding the augmenting paths within each phase is more difficult. Building on the work of several slower predecessors, Micali & Vazirani (1980) showed how to implement a phase in linear time, resulting in a non-bipartite matching algorithm with the same time bound as the Hopcroft–Karp algorithm for bipartite graphs. The Micali–Vazirani technique is complex, and its authors did not provide full proofs of their results; subsequently, a "clear exposition" was published by Peterson & Loui (1988) and alternative methods were described by other authors.[7] In 2012, Vazirani offered a new simplified proof of the Micali-Vazirani algorithm.[8]
Pseudocode
/*
G = U ∪ V ∪ {NIL}
where U and V are the left and right sides of the bipartite graph and NIL is a special null vertex
*/
function BFS() is
for each u in U do
if Pair_U[u] = NIL then
Dist[u] := 0
Enqueue(Q, u)
else
Dist[u] := ∞
Dist[NIL] := ∞
while Empty(Q) = false do
u := Dequeue(Q)
if Dist[u] < Dist[NIL] then
for each v in Adj[u] do
if Dist[Pair_V[v]] = ∞ then
Dist[Pair_V[v]] := Dist[u] + 1
Enqueue(Q, Pair_V[v])
return Dist[NIL] ≠ ∞
function DFS(u) is
if u ≠ NIL then
for each v in Adj[u] do
if Dist[Pair_V[v]] = Dist[u] + 1 then
if DFS(Pair_V[v]) = true then
Pair_V[v] := u
Pair_U[u] := v
return true
Dist[u] := ∞
return false
return true
function Hopcroft–Karp is
for each u in U do
Pair_U[u] := NIL
for each v in V do
Pair_V[v] := NIL
matching := 0
while BFS() = true do
for each u in U do
if Pair_U[u] = NIL then
if DFS(u) = true then
matching := matching + 1
return matching
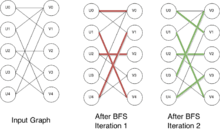
Explanation
Let the vertices of our graph be partitioned in U and V, and consider a partial matching, as indicated by the Pair_U and Pair_V tables that contain the one vertex to which each vertex of U and of V is matched, or NIL for unmatched vertices. The key idea is to add two dummy vertices on each side of the graph: uDummy connected to all unmatched vertices in U and vDummy connected to all unmatched vertices in V. Now, if we run a breadth-first search (BFS) from uDummy to vDummy then we can get the paths of minimal length that connect currently unmatched vertices in U to currently unmatched vertices in V. Note that, as the graph is bipartite, these paths always alternate between vertices in U and vertices in V, and we require in our BFS that when going from V to U, we always select a matched edge. If we reach an unmatched vertex of V, then we end at vDummy and the search for paths in the BFS terminate. To summarize, the BFS starts at unmatched vertices in U, goes to all their neighbors in V, if all are matched then it goes back to the vertices in U to which all these vertices are matched (and which were not visited before), then it goes to all the neighbors of these vertices, etc., until one of the vertices reached in V is unmatched.
Observe in particular that BFS marks the unmatched nodes of U with distance 0, then increments the distance every time it comes back to U. This guarantees that the paths considered in the BFS are of minimal length to connect unmatched vertices of U to unmatched vertices of V while always going back from V to U on edges that are currently part of the matching. In particular, the special NIL vertex, which corresponds to vDummy, then gets assigned a finite distance, so the BFS function returns true iff some path has been found. If no path has been found, then there are no augmenting paths left and the matching is maximal.
If BFS returns true, then we can go ahead and update the pairing for vertices on the minimal-length paths found from U to V: we do so using a depth-first search (DFS). Note that each vertex in V on such a path, except for the last one, is currently matched. So we can explore with the DFS, making sure that the paths that we follow correspond to the distances computed in the BFS. We update along every such path by removing from the matching all edges of the path that are currently in the matching, and adding to the matching all edges of the path that are currently not in the matching: as this is an augmenting path (the first and last edges of the path were not part of the matching, and the path alternated between matched and unmatched edges), then this increases the number of edges in the matching. This is same as replacing the current matching by the symmetric difference between the current matching and the entire path..
Note that the code ensures that all augmenting paths that we consider are vertex disjoint. Indeed, after doing the symmetric difference for a path, none of its vertices could be considered again in the DFS, just because the Dist[Pair_V[v]] will not be equal to Dist[u] + 1 (it would be exactly Dist[u]).
Also observe that the DFS does not visit the same vertex multiple times. This is thanks to the following lines:
Dist[u] = ∞ return false
When we were not able to find any shortest augmenting path from a vertex u, then the DFS marks vertex u by setting Dist[u] to infinity, so that these vertices are not visited again.
One last observation is that we actually don't need uDummy: its role is simply to put all unmatched vertices of U in the queue when we start the BFS. As for vDummy, it is denoted as NIL in the pseudocode above.
See also
- Maximum cardinality matching, the problem solved by the algorithm, and its generalization to non-bipartite graphs
- Assignment problem, a generalization of this problem on weighted graphs, solved e.g. by the Hungarian algorithm
- Edmonds–Karp algorithm for finding maximum flow, a generalization of the Hopcroft–Karp algorithm
Notes
- Gabow (2017); Annamalai (2018)
- Dinitz (2006).
- Peterson, Paul A.; Loui, Michael C. (1988-11-01). "The general maximum matching algorithm of micali and vazirani". Algorithmica. 3 (1): 511–533. doi:10.1007/BF01762129. ISSN 1432-0541.
- Tarjan, Robert Endre (1983-01-01). Data Structures and Network Algorithms. CBMS-NSF Regional Conference Series in Applied Mathematics. Society for Industrial and Applied Mathematics. doi:10.1137/1.9781611970265. ISBN 978-0-89871-187-5., p102
- Ahuja, Magnanti & Orlin (1993), section 12.3, bipartite cardinality matching problem, pp. 469–470.
- Chang & McCormick (1990); Darby-Dowman (1980); Setubal (1993); Setubal (1996).
- Gabow & Tarjan (1991).
- Vazirani (2012)
References
- Ahuja, Ravindra K.; Magnanti, Thomas L.; Orlin, James B. (1993), Network Flows: Theory, Algorithms and Applications, Prentice-Hall.
- Alt, H.; Blum, N.; Mehlhorn, K.; Paul, M. (1991), "Computing a maximum cardinality matching in a bipartite graph in time ", Information Processing Letters, 37 (4): 237–240, doi:10.1016/0020-0190(91)90195-N.
- Annamalai, Chidambaram (2018), "Finding perfect matchings in bipartite hypergraphs", Combinatorica, 38 (6): 1285–1307, arXiv:1509.07007, doi:10.1007/s00493-017-3567-2, MR 3910876
- Bast, Holger; Mehlhorn, Kurt; Schafer, Guido; Tamaki, Hisao (2006), "Matching algorithms are fast in sparse random graphs", Theory of Computing Systems, 39 (1): 3–14, doi:10.1007/s00224-005-1254-y.
- Chang, S. Frank; McCormick, S. Thomas (1990), A faster implementation of a bipartite cardinality matching algorithm, Tech. Rep. 90-MSC-005, Faculty of Commerce and Business Administration, Univ. of British Columbia. As cited by Setubal (1996).
- Darby-Dowman, Kenneth (1980), The exploitation of sparsity in large scale linear programming problems – Data structures and restructuring algorithms, Ph.D. thesis, Brunel University. As cited by Setubal (1996).
- Dinitz, Yefim (2006), "Dinitz' Algorithm: The Original Version and Even's Version", in Goldreich, Oded; Rosenberg, Arnold L.; Selman, Alan L. (eds.), Theoretical Computer Science: Essays in Memory of Shimon Even, Lecture Notes in Computer Science, 3895, Berlin and Heidelberg: Springer, pp. 218–240, doi:10.1007/11685654_10.
- Edmonds, Jack (1965), "Paths, Trees and Flowers", Canadian Journal of Mathematics, 17: 449–467, doi:10.4153/CJM-1965-045-4, MR 0177907.
- Gabow, Harold N. (2017), "The weighted matching approach to maximum cardinality matching", Fundamenta Informaticae, 154 (1–4): 109–130, arXiv:1703.03998, doi:10.3233/FI-2017-1555, MR 3690573
- Gabow, Harold N.; Tarjan, Robert E. (1991), "Faster scaling algorithms for general graph matching problems", Journal of the ACM, 38 (4): 815–853, doi:10.1145/115234.115366.
- Hopcroft, John E.; Karp, Richard M. (1973), "An n5/2 algorithm for maximum matchings in bipartite graphs", SIAM Journal on Computing, 2 (4): 225–231, doi:10.1137/0202019. Previously announced at the 12th Annual Symposium on Switching and Automata Theory, 1971.
- Karzanov, A. V. (1973), "An exact estimate of an algorithm for fnding a maximum flow, applied to the problem on representatives", Problems in Cybernetics, 5: 66–70. Previously announced at the Seminar on Combinatorial Mathematics (Moscow, 1971).
- Micali, S.; Vazirani, V. V. (1980), "An algorithm for finding maximum matching in general graphs", Proc. 21st IEEE Symp. Foundations of Computer Science, pp. 17–27, doi:10.1109/SFCS.1980.12.
- Peterson, Paul A.; Loui, Michael C. (1988), "The general maximum matching algorithm of Micali and Vazirani", Algorithmica, 3 (1–4): 511–533, CiteSeerX 10.1.1.228.9625, doi:10.1007/BF01762129.
- Motwani, Rajeev (1994), "Average-case analysis of algorithms for matchings and related problems", Journal of the ACM, 41 (6): 1329–1356, doi:10.1145/195613.195663.
- Setubal, João C. (1993), "New experimental results for bipartite matching", Proc. Netflow93, Dept. of Informatics, Univ. of Pisa, pp. 211–216. As cited by Setubal (1996).
- Setubal, João C. (1996), Sequential and parallel experimental results with bipartite matching algorithms, Tech. Rep. IC-96-09, Inst. of Computing, Univ. of Campinas, CiteSeerX 10.1.1.48.3539.
- Vazirani, Vijay (2012), An Improved Definition of Blossoms and a Simpler Proof of the MV Matching Algorithm, CoRR abs/1210.4594, arXiv:1210.4594, Bibcode:2012arXiv1210.4594V.

