Gated recurrent unit
Gated recurrent units (GRUs) are a gating mechanism in recurrent neural networks, introduced in 2014 by Kyunghyun Cho et al.[1] The GRU is like a long short-term memory (LSTM) with a forget gate[2] but has fewer parameters than LSTM, as it lacks an output gate.[3] GRU's performance on certain tasks of polyphonic music modeling, speech signal modeling and natural language processing was found to be similar to that of LSTM [4] [5] GRUs have been shown to exhibit even better performance on certain smaller and less frequent datasets. [6][7]
However, as shown by Gail Weiss, Yoav Goldberg and Eran Yahav, the LSTM is "strictly stronger" than the GRU as it can easily perform unbounded counting, while the GRU cannot. That's why the GRU fails to learn simple languages that are learnable by the LSTM.[8]
Similarly, as shown by Denny Britz, Anna Goldie, Minh-Thang Luong and Quoc Le of Google Brain, LSTM cells consistently outperform GRU cells in "the first large-scale analysis of architecture variations for Neural Machine Translation."[9]
Architecture
There are several variations on the full gated unit, with gating done using the previous hidden state and the bias in various combinations, and a simplified form called minimal gated unit. [10]
The operator denotes the Hadamard product in the following.

Fully gated unit
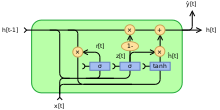
Initially, for , the output vector is .



Variables
- : input vector
- : output vector
- : candidate activation vector
- : update gate vector
- : reset gate vector
- , and : parameter matrices and vector








- : The original is a sigmoid function.
- : The original is a hyperbolic tangent.


Alternative activation functions are possible, provided that .


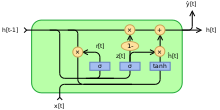

Alternate forms can be created by changing and [11]
- Type 1, each gate depends only on the previous hidden state and the bias.
- Type 2, each gate depends only on the previous hidden state.
- Type 3, each gate is computed using only the bias.



Minimal gated unit
The minimal gated unit is similar to the fully gated unit, except the update and reset gate vector is merged into a forget gate. This also implies that the equation for the output vector must be changed [12]

Variables
- : input vector
- : output vector
- : candidate activation vector
- : forget vector
- , and : parameter matrices and vector

References
- Cho, Kyunghyun; van Merrienboer, Bart; Gulcehre, Caglar; Bahdanau, Dzmitry; Bougares, Fethi; Schwenk, Holger; Bengio, Yoshua (2014). "Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation". arXiv:1406.1078 [cs.CL].
- Felix Gers; Jürgen Schmidhuber; Fred Cummins (1999). "Learning to Forget: Continual Prediction with LSTM". Proc. ICANN'99, IEE, London. 1999: 850–855. doi:10.1049/cp:19991218. ISBN 0-85296-721-7.
- "Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano – WildML". Wildml.com. 2015-10-27. Retrieved May 18, 2016.
- Ravanelli, Mirco; Brakel, Philemon; Omologo, Maurizio; Bengio, Yoshua (2018). "Light Gated Recurrent Units for Speech Recognition". arXiv:1803.10225.
- Su, Yuahang; Kuo, Jay (2019). "On Extended Long Short-term Memory and Dependent Bidirectional Recurrent Neural Network". arXiv:1803.01686.
- Su, Yuanhang; Kuo, Jay (2014). "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling". arXiv:1412.3555 [cs.NE].
- Gruber, N.; Jockisch, A. (2020), "Are GRU cells more specific and LSTM cells more sensitive in motive classification of text?", Frontiers in Artificial Intelligence, doi:10.3389/frai.2020.00040
- Weiss, Gail; Goldberg, Yoav; Yahav, Eran (2018). "On the Practical Computational Power of Finite Precision RNNs for Language Recognition". arXiv:1805.04908 [cs.NE].
- Britz, Denny; Goldie, Anna; Luong, Minh-Thang; Le, Quoc (2018). "Massive Exploration of Neural Machine Translation Architectures". arXiv:1703.03906 [cs.NE].
- Chung, Junyoung; Gulcehre, Caglar; Cho, KyungHyun; Bengio, Yoshua (2014). "Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling". arXiv:1412.3555 [cs.NE].
- Dey, Rahul; Salem, Fathi M. (2017-01-20). "Gate-Variants of Gated Recurrent Unit (GRU) Neural Networks". arXiv:1701.05923 [cs.NE].
- Heck, Joel; Salem, Fathi M. (2017-01-12). "Simplified Minimal Gated Unit Variations for Recurrent Neural Networks". arXiv:1701.03452 [cs.NE].