Fuzzy extractor
Fuzzy extractors are a method that allows biometric data to be used as inputs to standard cryptographic techniques for security. "Fuzzy", in this context, refers to the fact that the fixed values required for cryptography will be extracted from values close to but not identical to the original key, without compromising the security required. One application is to encrypt and authenticate users records, using the biometric inputs of the user as a key.
Fuzzy extractors are a biometric tool that allows for user authentication, using a biometric template constructed from the user's biometric data as the key. They extract a uniform and random string from an input with a tolerance for noise. If the input changes to but is still close to , the same string will be re-constructed. To achieve this, during the initial computation of the process also outputs a helper string which will be stored to recover later and can be made public without compromising the security of . The security of the process is ensured also when an adversary modifies . Once the fixed string has been calculated, it can be used for example for key agreement between a user and a server based only on a biometric input.




Historically, the first biometric system of this kind was designed by Juels and Wattenberg and was called "Fuzzy commitment", where the cryptographic key is decommitted using biometric data. Later, Juels and Sudan came up with Fuzzy vault schemes which are order invariant for the fuzzy commitment scheme but uses a Reed–Solomon code. Codeword is evaluated by polynomial and the secret message is inserted as the coefficients of the polynomial. The polynomial is evaluated for different values of a set of features of the biometric data. So Fuzzy commitment and Fuzzy Vault were precursors to Fuzzy extractors.
This description is based on the papers "Fuzzy Extractors: A Brief Survey of Results from 2004 to 2006" and "Fuzzy Extractors: How to Generate Strong Keys from Biometrics and Other Noisy Data"[1] by Yevgeniy Dodis, Rafail Ostrovsky, Leonid Reyzin and Adam Smith
Motivation
In order for fuzzy extractors to generate strong keys from biometric and other noisy data, cryptography paradigms will be applied to this biometric data. This means they must be allowed to
(1) Limit the number of assumptions about the content of the biometric data (this data comes from a variety of sources, so in order to avoid exploitation by an adversary, it's best to assume the input is unpredictable)
(2) Apply usual cryptographic techniques to the input. (Fuzzy extractors convert biometric data into secret, uniformly random and reliably reproducible random strings).
These techniques can also have other broader applications for other type of noisy inputs such as approximative data from human memory, images used as passwords, keys from quantum channel.[1] According to the Differential Privacy paper by Cynthia Dwork (ICALP 2006), fuzzy extractors also have applications in the proof of impossibility of the strong notions of privacy for statistical databases.
Basic definitions
Predictability
Predictability indicates the probability that an adversary can guess a secret key. Mathematically speaking, the predictability of a random variable is .


For example, given a pair of random variable and , if the adversary knows of , then the predictability of will be . So, an adversary can predict with . We use the average over as it is not under adversary control, but since knowing makes the prediction of adversarial, we take the worst case over .




Min-entropy
Min-entropy indicates the worst-case entropy. Mathematically speaking, it is defined as .

A random variable with a min-entropy at least of is called a -source.

Statistical distance
Statistical distance is a measure of distinguishability. Mathematically speaking, it is expressed for two probability distributions and as = . In any system, if is replaced by , it will behave as the original system with a probability at least of .



Definition 1 (strong extractor)
Setting as a strong randomness extractor. The randomized function Ext: with randomness of length is a strong extractor if for all -sources on where is independent of .







The output of the extractor is a key generated from with the seed . It behaves independently of other parts of the system with the probability of . Strong extractors can extract at most bits from an arbitrary -source.




Secure sketch
Secure sketch makes it possible to reconstruct noisy input, so that if the input is and the sketch is , given and a value close to , can be recovered. But the sketch must not reveal information about , in order to keep it secure.

If is a metric space with the distance function dis, Secure sketch recovers the string from any close string without disclosing .



Definition 2 (secure sketch)
An secure sketch is a pair of efficient randomized procedures (the Sketch noted SS, the Recover noted Rec) such that :

(1) The sketching procedure SS applied on input returns a string .

The recovery procedure Rec uses as input two elements and .
(2) Correctness: If then .


(3) Security: For any -source over , the min-entropy of given is high:
for any , if , then .



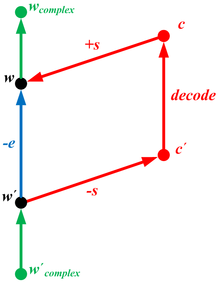
Fuzzy extractor
Fuzzy extractors do not recover the original input but generate a string (which is close to uniform) from and allow its subsequent reproduction (using helper string ) given any close to . Strong extractors are a special case of fuzzy extractors when = 0 and .


Definition 3 (fuzzy extractor)
An fuzzy extractor is a pair of efficient randomized procedures (Gen – Generate and Rep – Reproduce) such that:

(1) Gen, given , outputs an extracted string and a helper string .


(2) Correctness: If and , then .


(3) Security: For all m-sources over , the string is nearly uniform even given , So , then .

So Fuzzy extractors output almost uniform random sequences of bits which are a prerequisite for using cryptographic applications (as secret keys). Since the output bits are slightly non-uniform, there's a risk of a decreased security, but the distance from a uniform distribution is no more than and as long as this distance is sufficiently small, the security will remain adequate.

Secure sketches and fuzzy extractors
Secure sketches can be used to construct fuzzy extractors. Like applying SS to to obtain and strong extractor Ext with randomness to to get . can be stored as helper string . can be reproduced by and . can recover and can reproduce . The following lemma formalizes this.





Lemma 1 (fuzzy extractors from sketches)
Assume (SS,Rec) is an secure sketch and let Ext be an average-case strong extractor. Then the following (Gen, Rep) is an fuzzy extractor: (1) Gen : set and output . (2) Rep : recover and output .









Proof: From the definition of secure sketch (Definition 2), . And since Ext is an average-case -strong extractor.



Corollary 1
If (SS,Rec) is an secure sketch and Ext is an strong extractor, then the above construction (Gen,Rep) is a fuzzy extractor.


The reference paper includes many generic combinatorial bounds on secure sketches and fuzzy extractors.[1]
Basic constructions
Due to their error tolerant properties, a secure sketches can be treated, analyzed, and constructed like a general error correcting code or for linear codes, where is the length of codewords, is the length of the message to be codded, is the distance between codewords, and is the alphabet. If is the universe of possible words then it may be possible to find an error correcting code that has a unique codeword for every and have a Hamming distance of . The first step for constructing a secure sketch is determining the type of errors that will likely occur and then choosing a distance to measure.











Hamming distance constructions
When there is no risk of data being deleted and only of it being corrupted then the best measurement to use for error correction is the Hamming distance. There are two common constructions for correcting Hamming errors depending on whether the code is linear or not. Both constructions start with an error correcting code that has a distance of where is the number of tolerated errors.


Code-offset construction
When using a general code, assign a uniformly random codeword to each , then let which is the shift needed to change into . To fix errors in subtract from then correct the errors in the resulting incorrect codeword to get and finally add to to get . This means . This construction can achieve the best possible tradeoff between error tolerance and entropy loss when and a Reed–Solomon code is used resulting in an entropy loss of . The only way to improve upon would be to find a code better than Reed–Solomon.






Syndrome construction
When using a linear code let the be the syndrome of . To correct find a vector such that , then .





Set difference constructions
When working with a very large alphabet or very long strings resulting in a very large universe , it may be more efficient to treat and as sets and look at set differences to correct errors. To work with a large set it is useful to look at its characteristic vector , which is a binary vector of length that has a value of 1 when an element and , or 0 when . The best way to decrease the size of a secure sketch when is large is make large since the size is determined by . A good code to base this construction on is a BCH code where and so , it is also useful that BCH codes can be decode in sub-linear time.










Pin sketch construction
Let . To correct first find , then find a set v where , finally compute the symmetric difference to get . While this is not the only construction than can be used to set the difference, it is the easiest one.




Edit distance constructions
When data can be corrupted or deleted, the best measurement to use is edit distance. To make a construction based on edit distance, the easiest is to start with a construction for set difference or hamming distance as an intermediate correction step and then build the edit distance construction around that.
Other distance measure constructions
There are many other types of errors and distances that can be used to model other situations. Most of these other possible constructions are built upon simpler constructions, like edit distance constructions.
Improving error-tolerance via relaxed notions of correctness
It can be shown that the error-tolerance of a secure sketch can be improved by applying a probabilistic method to error correction and only requesting errors to be correctable with a high probability. This allows to exceed the Plotkin bound which limits to correcting errors, and to approach Shannon’s bound allowing for nearly corrections. To achieve this enhanced error correction, a less restrictive error distribution model must be used.


Random errors
For this most restrictive model use a BSC to create a that a probability at each position in that the bit received is wrong. This model can show that entropy loss is limited to , where is the binary entropy function, and if min-entropy then errors can be tolerated, for some constant .







Input-dependent errors
For this model errors do not have a known distribution and can be from an adversary, the only constraints are and that a corrupted word depends only on the input and not on the secure sketch. It can be shown for this error model that there will never be more than errors since this model can account for all complex noise processes, meaning that Shannon’s bound can be reached, to do this a random permutation is prepended to the secure sketch that will reduce entropy loss.

Computationally bounded errors
This differs from the input dependent model by having errors that depend on both the input and the secure sketch, and an adversary is limited to polynomial time algorithms for introducing errors. Since algorithms that can run in better than polynomial time are not currently feasible in the real world, then a positive result using this error model would guarantee that any errors can be fixed. This is the least restrictive model the only known way to approach Shannon’s bound is to use list-decodable codes although this may not always be useful in practice since returning a list instead of a single codeword may not always be acceptable.
Privacy guarantees
In general a secure system attempts to leak as little information as possible to an adversary. In the case of biometrics if information about the biometric reading is leaked the adversary may be able to learn personal information about a user. For example an adversary notices that there is a certain pattern in the helper strings that implies the ethnicity of the user. We can consider this additional information a function . If an adversary were to learn a helper string, it must be ensured that, from this data he can not infer any data about the person from which the biometric reading was taken.

Correlation between helper string and biometric input
Ideally the helper string would reveal no information about the biometric input . This is only possible when every subsequent biometric reading is identical to the original . In this case there is actually no need for the helper string, so it is easy to generate a string that is in no way correlated to .
Since it is desirable to accept biometric input similar to the helper string must be somehow correlated. The more different and are allowed to be, the more correlation there will be between and , the more correlated they are the more information reveals about . We can consider this information to be a function . The best possible solution is to make sure the adversary can't learn anything useful from the helper string.
Gen(W) as a probabilistic map
A probabilistic map hides the results of functions with a small amount of leakage . The leakage is the difference in probability two adversaries have of guessing some function when one knows the probabilistic map and one does not. Formally:


If the function is a probabilistic map, then even if an adversary knows both the helper string and the secret string they are only negligibly more likely figure something out about the subject as if they knew nothing. The string is supposed to kept secret, so even if it is leaked (which should be very unlikely) the adversary can still figure out nothing useful about the subject, as long as is small. We can consider to be any correlation between the biometric input and some physical characteristic of the person. Setting in the above equation changes it to:



This means that if one adversary has and a second adversary knows nothing, their best guesses at are only apart.


Uniform fuzzy extractors
Uniform fuzzy extractors are a special case of fuzzy extractors, where the output of are negligibly different from strings picked from the uniform distribution, i.e.

Uniform secure sketches
Since secure sketches imply fuzzy extractors, constructing a uniform secure sketch allows for the easy construction of a uniform fuzzy extractor. In a uniform secure sketch the sketch procedure is a randomness extractor . Where is the biometric input and is the random seed. Since randomness extractors output a string that appears to be from a uniform distribution they hide all the information about their input.



Applications
Extractor sketches can be used to construct -fuzzy perfectly one-way hash functions. When used as a hash function the input is the object you want to hash. The that outputs is the hash value. If one wanted to verify that a within from the original , they would verify that . -fuzzy perfectly one-way hash functions are special hash functions where they accept any input with at most errors, compared to traditional hash functions which only accept when the input matches the original exactly. Traditional cryptographic hash functions attempt to guarantee that is it is computationally infeasible to find two different inputs that hash to the same value. Fuzzy perfectly one-way hash functions make an analogous claim. They make it computationally infeasible two find two inputs, that are more than Hamming distance apart and hash to the same value.



Protection against active attacks
An active attack could be one where the adversary can modify the helper string . If the adversary is able to change to another string that is also acceptable to the reproduce function , it causes to output an incorrect secret string . Robust fuzzy extractors solve this problem by allowing the reproduce function to fail, if a modified helper string is provided as input.


Robust fuzzy extractors
One method of constructing robust fuzzy extractors is to use hash functions. This construction requires two hash functions and . The functions produces the helper string by appending the output of a secure sketch to the hash of both the reading and secure sketch . It generates the secret string by applying the second hash function to and . Formally:




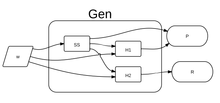
The reproduce function also makes use of the hash functions and . In addition to verifying the biometric input is similar enough to the one recovered using the function, it also verifies that hash in the second part of was actually derived from and . If both of those conditions are met it returns which is itself the second hash function applied to and . Formally:

Get and from If and then else








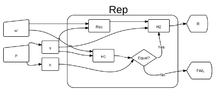
If has been tampered with it will be obvious because, will output fail with very high probability. To cause the algorithm accept a different an adversary would have to find a such that . Since hash function are believed to be one-way functions, it is computationally infeasible to find such a . Seeing would provide the adversary with no useful information. Since, again, hash function are one-way functions, it is computationally infeasible for the adversary to reverse the hash function and figure out . Part of is the secure sketch, but by definition the sketch reveals negligible information about its input. Similarly seeing (even though it should never see it) would provide the adversary with no useful information as the adversary wouldn't be able to reverse the hash function and see the biometric input.



References
- Yevgeniy Dodis, Rafail Ostrovsky, Leonid Reyzin, and Adam Smith. "Fuzzy Extractors: How to Generate Strong Keys from Biometrics and Other Noisy Data". 2008.