External memory graph traversal
External memory graph traversal is a type of graph traversal optimized for accessing externally stored memory.
Background
Graph traversal is a subroutine in most graph algorithms. The goal of a graph traversal algorithm is to visit (and / or process) every node of a graph. Graph traversal algorithms, like breadth-first search and depth-first search, are analyzed using the von Neumann model, which assumes uniform memory access cost. This view neglects the fact, that for huge instances part of the graph resides on disk rather than internal memory. Since accessing the disk is magnitudes slower than accessing internal memory, the need for efficient traversal of external memory exists.
External memory model
For external memory algorithms the external memory model by Aggarwal and Vitter[1] is used for analysis. A machine is specified by three parameters: M, B and D. M is the size of the internal memory, B is the block size of a disk and D is the number of parallel disks. The measure of performance for an external memory algorithm is the number of I/Os it performs.
External memory breadth-first search
The breadth-first search algorithm starts at a root node and traverses every node with depth one. If there are no more unvisited nodes at the current depth, nodes at a higher depth are traversed. Eventually, every node of the graph has been visited.
Munagala and Ranade
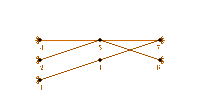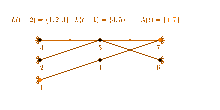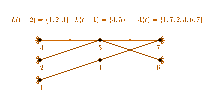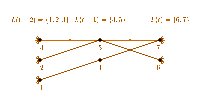
For an undirected graph , Munagala and Ranade[2] proposed the following external memory algorithm:

Let denote the nodes in breadth-first search level t and let be the multi-set of neighbors of level t-1. For every t, can be constructed from by transforming it into a set and excluding previously visited nodes from it.



- Create by accessing the adjacency list of every vertex in . This step requires I/Os.
- Next is created from by removing duplicates. This can be achieved via sorting of , followed by a scan and compaction phase needing I/Os.
- is calculated by a parallel scan over and and requires I/Os.







The overall number of I/Os of this algorithm follows with consideration that and and is .



A visualization of the three described steps necessary to compute L(t) is depicted in the figure on the right.
Mehlhorn and Meyer
Mehlhorn and Meyer[3] proposed an algorithm that is based on the algorithm of Munagala and Ranade (MR) and improves their result.
It consists of two phases. In the first phase the graph is preprocessed, the second phase performs a breadth-first search using the information gathered in phase one.
During the preprocessing phase the graph is partitioned into disjointed subgraphs with small diameter. It further partitions the adjacency lists accordingly, by constructing an external file , where contains the adjacency list for all nodes in .




The breadth-first search phase is similar to the MR algorithm. In addition the algorithm maintains a sorted external file . This file is initialized with . Further, the nodes of any created breadth-first search level carry identifiers for the files of their respective subgraphs . Instead of using random accesses to construct the file is used.


- Perform a parallel scan of sorted list and . Extract the adjacency lists for nodes , that can be found in .
- The adjacency lists for the remaining nodes that could not be found in need to be fetched. A scan over yields the partition identifiers. After sorting and deletion of duplicates, the respective files can be concatenated into a temporary file .
- The missing adjacency lists can be extracted from with a scan. Next, the remaining adjacency lists are merged into with a single pass.
- is created by a simple scan. The partition information is attached to each node in .
- The algorithm proceeds like the MR algorithm.


Edges might be scanned more often in , but unstructured I/Os in order to fetch adjacency lists are reduced.
The overall number of I/Os for this algorithm is

External memory depth-first search
The depth-first search algorithm explores a graph along each branch as deep as possible, before backtracing.
For directed graphs Buchsbaum, Goldwasser, Venkatasubramanian and Westbrook[4] proposed an algorithm with I/Os.

This algorithm is based on a data structure called buffered repository tree (BRT). It stores a multi-set of items from an ordered universe. Items are identified by key. A BTR offers two operations:
- insert(T,x), which adds item x to T and needs amortized I/Os. N is the number of items added to the BTR.
- extract(T,k), which reports and deletes from T all items with key k. It requires I/Os, where S is the size of the set returned by extract.


The algorithm simulates an internal depth-first search algorithm. A stack S of nodes is hold. During an iteration for the node v on top of S push an unvisited neighbor onto S and iterate. If there are no unvisited neighbors pop v.
The difficulty is to determine whether a node is unvisited without doing I/Os per edge. To do this for a node v incoming edges (x,v) are put into a BRT D, when v is first discovered. Further, outgoing edges (v,x) are put into a priority queue P(v), keyed by the rank in the adjacency list.

For vertex u on top of S all edges (u,x) are extracted from D. Such edges only exist if x has been discovered since the last time u was on top of S (or since the start of the algorithm if u is the first time on top of S). For every edge (u,x) a delete(x) operation is performed on P(u). Finally a delete-min operation on P(u) yields the next unvisited node. If P(u) is empty, u is popped from S.
Pseudocode for this algorithm is given below.
1 procedure BGVW-depth-first-search(G,v): 2 let S be a stack, P[] a priority queue for each node and D a BRT 3 S.push(v) 4 while S is not empty 5 v = S.top() 6 if v is not marked: 7 mark(v) 8 extract all edges (v,x) from D, x: P[v].delete(x) 9 if u=P[v].delete-min() not null 10 S.push(u) 11 else 12 S.pop() 13 procedure mark(v) 14 put all edges (x,v) into D 15 (v,x): put x into P[v]

References
- Aggarwal, Alok; Vitter, Jeffrey (1988). "The input/output complexity of sorting and related problems". Communications of the ACM. 31 (9): 1116–1127. doi:10.1145/48529.48535.
- Munagala, Kameshwar; Ranade, Abhiram (1999). "I/O-complexity of Graph Algorithms". Proceedings of the Tenth Annual ACM-SIAM Symposium on Discrete Algorithms. SODA '99. Baltimore, Maryland, USA: Society for Industrial and Applied Mathematics. pp. 687–694.
- Mehlhorn, Kurt; Meyer, Ulrich (2002). "External-Memory Breadth-First Search with Sublinear I/O". Algorithms -- ESA 2002. ESA 2002. Rome, Italy: Springer Berlin Heidelberg. pp. 723–735.
- Buchsbaum, Adam L.; Goldwasser, Michael; Venkatasubramanian, Michael; Westbrook, Suresh (2000). "On External Memory Graph Traversal". Proceedings of the Eleventh Annual ACM-SIAM Symposium on Discrete Algorithms. SODA '00. San Francisco, California, USA: Society for Industrial and Applied Mathematics. pp. 859–860.