Difference in differences
Difference in differences (DID[1] or DD[2]) is a statistical technique used in econometrics and quantitative research in the social sciences that attempts to mimic an experimental research design using observational study data, by studying the differential effect of a treatment on a 'treatment group' versus a 'control group' in a natural experiment.[3] It calculates the effect of a treatment (i.e., an explanatory variable or an independent variable) on an outcome (i.e., a response variable or dependent variable) by comparing the average change over time in the outcome variable for the treatment group, compared to the average change over time for the control group. Although it is intended to mitigate the effects of extraneous factors and selection bias, depending on how the treatment group is chosen, this method may still be subject to certain biases (e.g., mean regression, reverse causality and omitted variable bias).
In contrast to a time-series estimate of the treatment effect on subjects (which analyzes differences over time) or a cross-section estimate of the treatment effect (which measures the difference between treatment and control groups), difference in differences uses panel data to measure the differences, between the treatment and control group, of the changes in the outcome variable that occur over time.
General definition
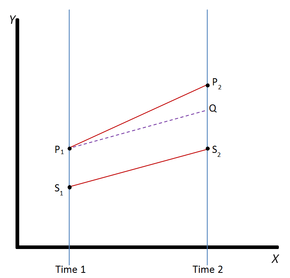
Difference in differences requires data measured from a treatment group and a control group at two or more different time periods, specifically at least one time period before "treatment" and at least one time period after "treatment." In the example pictured, the outcome in the treatment group is represented by the line P and the outcome in the control group is represented by the line S. The outcome (dependent) variable in both groups is measured at time 1, before either group has received the treatment (i.e., the independent or explanatory variable), represented by the points P1 and S1. The treatment group then receives or experiences the treatment and both groups are again measured at time 2. Not all of the difference between the treatment and control groups at time 2 (that is, the difference between P2 and S2) can be explained as being an effect of the treatment, because the treatment group and control group did not start out at the same point at time 1. DID therefore calculates the "normal" difference in the outcome variable between the two groups (the difference that would still exist if neither group experienced the treatment), represented by the dotted line Q. (Notice that the slope from P1 to Q is the same as the slope from S1 to S2.) The treatment effect is the difference between the observed outcome and the "normal" outcome (the difference between P2 and Q).
Formal definition
Consider the model

where is the dependent variable for individual and , is the group to which belongs (i.e. the treatment or the control group), and is short-hand for the dummy variable equal to 1 when the event described in is true, and 0 otherwise. In the plot of time versus by group, is the vertical intercept for the graph for , and is the time trend shared by both groups according to the parallel trend assumption (see Assumptions below). is the treatment effect, and is the residual term.












Consider the average of the dependent variable and dummy indicators by group and time:

and suppose for simplicity that and . Note that is not random; it just encodes how the groups and the periods are labeled. Then




The strict exogeneity assumption then implies that

Without loss of generality, assume that is the treatment group, and is the after period, then and , giving the DID estimator





which can be interpreted as the treatment effect of the treatment indicated by . Below it is shown how this estimator can be read as a coefficient in an ordinary least squares regression. The model described in this section is over-parametrized; to remedy that, one of the coefficients for the dummy variables can be set to 0, for example, we may set .

Assumptions
All the assumptions of the OLS model apply equally to DID. In addition, DID requires a parallel trend assumption. The parallel trend assumption says that are the same in both and . Given that the formal definition above accurately represents reality, this assumption automatically holds. However, a model with may well be more realistic. In order to increase the likelihood of the parallel trend assumption holding, a difference-in-difference approach is often combined with matching. This involves 'Matching' known 'treatment' units with simulated counterfactual 'control' units: characteristically equivalent units which did not receive treatment. By defining the Outcome Variable as a temporal difference (change in observed outcome between pre- and posttreatment periods), and Matching multiple units in a large sample on the basis of similar pre-treatment histories, the resulting ATE (i.e. the ATT: Average Treatment Effect for the Treated) provides a robust difference-in-difference estimate of treatment effects. This serves two statistical purposes: firstly, conditional on pre-treatment covariates, the parallel trends assumption is likely to hold; and secondly, this approach reduces dependence on associated ignorability assumptions necessary for valid inference.



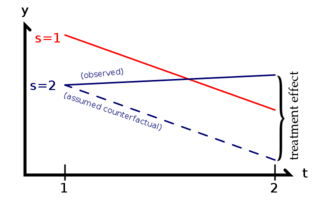
As illustrated to the right, the treatment effect is the difference between the observed value of y and what the value of y would have been with parallel trends, had there been no treatment. The Achilles' heel of DID is when something other than the treatment changes in one group but not the other at the same time as the treatment, implying a violation of the parallel trend assumption.
To guarantee the accuracy of the DID estimate, the composition of individuals of the two groups is assumed to remain unchanged over time. When using a DID model, various issues that may compromise the results, such as autocorrelation[4] and Ashenfelter dips, must be considered and dealt with.
Implementation
The DID method can be implemented according to the table below, where the lower right cell is the DID estimator.
| Difference | |||
|---|---|---|---|
| Change |











Running a regression analysis gives the same result. Consider the OLS model

where is a dummy variable for the period, equal to when , and is a dummy variable for group membership, equal to when . The composite variable is a dummy variable indicating when . Although it is not shown rigorously here, this is a proper parametrization of the model formal definition, furthermore, it turns out that the group and period averages in that section relate to the model parameter estimates as follows






where stands for conditional averages computed on the sample, for example, is the indicator for the after period, is an indicator for the control group. To see the relation between this notation and the previous section, consider as above only one observation per time period for each group, then




and so on for other values of and , which is equivalent to

But this is the expression for the treatment effect that was given in the formal definition and in the above table.
Card and Krueger (1994) example
Consider one of the most famous DID studies, the Card and Krueger article on minimum wage in New Jersey, published in 1994.[5] Card and Krueger compared employment in the fast food sector in New Jersey and in Pennsylvania, in February 1992 and in November 1992, after New Jersey's minimum wage rose from $4.25 to $5.05 in April 1992. Observing a change in employment in New Jersey only, before and after the treatment, would fail to control for omitted variables such as weather and macroeconomic conditions of the region. By including Pennsylvania as a control in a difference-in-differences model, any bias caused by variables common to New Jersey and Pennsylvania is implicitly controlled for, even when these variables are unobserved. Assuming that New Jersey and Pennsylvania have parallel trends over time, Pennsylvania's change in employment can be interpreted as the change New Jersey would have experienced, had they not increased the minimum wage, and vice versa. The evidence suggested that the increased minimum wage did not induce a decrease in employment in New Jersey, contrary to what simplistic economic theory would suggest. The table below shows Card & Krueger's estimates of the treatment effect on employment, measured as FTEs (or full-time equivalents). Card and Krueger estimate that the $0.80 minimum wage increase in New Jersey led to a 2.75 FTE increase in employment.
| New Jersey | Pennsylvania | Difference | |
|---|---|---|---|
| February | 20.44 | 23.33 | −2.89 |
| November | 21.03 | 21.17 | −0.14 |
| Change | 0.59 | −2.16 | 2.75 |
References
- Abadie, A. (2005). "Semiparametric difference-in-differences estimators". Review of Economic Studies. 72 (1): 1–19. CiteSeerX 10.1.1.470.1475. doi:10.1111/0034-6527.00321.
- Bertrand, M.; Duflo, E.; Mullainathan, S. (2004). "How Much Should We Trust Differences-in-Differences Estimates?" (PDF). Quarterly Journal of Economics. 119 (1): 249–275. doi:10.1162/003355304772839588.
- Angrist, J. D.; Pischke, J. S. (2008). Mostly Harmless Econometrics: An Empiricist's Companion. Princeton University Press. pp. 227–243. ISBN 978-0-691-12034-8.
- Bertrand, Marianne; Duflo, Esther; Mullainathan, Sendhil (2004). "How Much Should We Trust Differences-In-Differences Estimates?". Quarterly Journal of Economics. 119 (1): 249–275. doi:10.1162/003355304772839588.
- Card, David; Krueger, Alan B. (1994). "Minimum Wages and Employment: A Case Study of the Fast-Food Industry in New Jersey and Pennsylvania". American Economic Review. 84 (4): 772–793. JSTOR 2118030.
Further reading
- Angrist, J. D.; Pischke, J. S. (2008). Mostly Harmless Econometrics: An Empiricist's Companion. Princeton University Press. pp. 227–243. ISBN 978-0-691-12034-8.
- Cameron, Arthur C.; Trivedi, Pravin K. (2005). Microeconometrics: Methods and Applications. Cambridge university press. pp. 768–772. doi:10.1017/CBO9780511811241. ISBN 9780521848053.
- Imbens, Guido W.; Wooldridge, Jeffrey M. (2009). "Recent Developments in the Econometrics of Program Evaluation". Journal of Economic Literature. 47 (1): 5–86. doi:10.1257/jel.47.1.5.
- Bakija, Jon; Heim, Bradley (August 2008). "How Does Charitable Giving Respond to Incentives and Income? Dynamic Panel Estimates Accounting for Predictable Changes in Taxation". NBER Working Paper No. 14237. doi:10.3386/w14237.
- Conley, T.; Taber, C. (July 2005). "Inference with 'Difference in Differences' with a Small Number of Policy Changes". NBER Technical Working Paper No. 312. doi:10.3386/t0312.
External links
- Difference in Difference Estimation, Healthcare Economist website