Cyclomatic complexity
Cyclomatic complexity is a software metric used to indicate the complexity of a program. It is a quantitative measure of the number of linearly independent paths through a program's source code. It was developed by Thomas J. McCabe, Sr. in 1976.
Cyclomatic complexity is computed using the control flow graph of the program: the nodes of the graph correspond to indivisible groups of commands of a program, and a directed edge connects two nodes if the second command might be executed immediately after the first command. Cyclomatic complexity may also be applied to individual functions, modules, methods or classes within a program.
One testing strategy, called basis path testing by McCabe who first proposed it, is to test each linearly independent path through the program; in this case, the number of test cases will equal the cyclomatic complexity of the program.[1]
Description
Definition
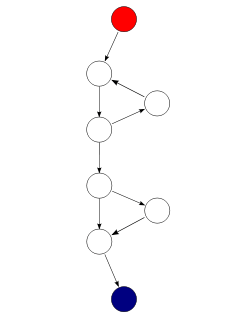
The cyclomatic complexity of a section of source code is the number of linearly independent paths within it—where "linearly independent" means that each path has at least one edge that is not in one of the other paths. For instance, if the source code contained no control flow statements (conditionals or decision points), the complexity would be 1, since there would be only a single path through the code. If the code had one single-condition IF statement, there would be two paths through the code: one where the IF statement evaluates to TRUE and another one where it evaluates to FALSE, so the complexity would be 2. Two nested single-condition IFs, or one IF with two conditions, would produce a complexity of 3.
Mathematically, the cyclomatic complexity of a structured program[lower-alpha 1] is defined with reference to the control flow graph of the program, a directed graph containing the basic blocks of the program, with an edge between two basic blocks if control may pass from the first to the second. The complexity M is then defined as[2]
- M = E − N + 2P,
where
- E = the number of edges of the graph.
- N = the number of nodes of the graph.
- P = the number of connected components.
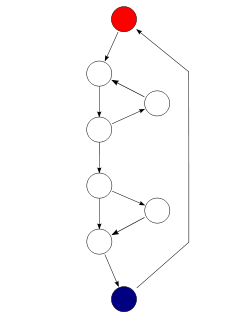
An alternative formulation is to use a graph in which each exit point is connected back to the entry point. In this case, the graph is strongly connected, and the cyclomatic complexity of the program is equal to the cyclomatic number of its graph (also known as the first Betti number), which is defined as[2]
- M = E − N + P.
This may be seen as calculating the number of linearly independent cycles that exist in the graph, i.e. those cycles that do not contain other cycles within themselves. Note that because each exit point loops back to the entry point, there is at least one such cycle for each exit point.
For a single program (or subroutine or method), P is always equal to 1. So a simpler formula for a single subroutine is
- M = E − N + 2.[3]
Cyclomatic complexity may, however, be applied to several such programs or subprograms at the same time (e.g., to all of the methods in a class), and in these cases P will be equal to the number of programs in question, as each subprogram will appear as a disconnected subset of the graph.
McCabe showed that the cyclomatic complexity of any structured program with only one entry point and one exit point is equal to the number of decision points (i.e., "if" statements or conditional loops) contained in that program plus one. However, this is true only for decision points counted at the lowest, machine-level instructions.[4] Decisions involving compound predicates like those found in high-level languages like IF cond1 AND cond2 THEN ... should be counted in terms of predicate variables involved, i.e. in this example one should count two decision points, because at machine level it is equivalent to IF cond1 THEN IF cond2 THEN ....[2][5]
Cyclomatic complexity may be extended to a program with multiple exit points; in this case it is equal to
- π − s + 2,
where π is the number of decision points in the program, and s is the number of exit points.[5][6]
Explanation in terms of algebraic topology
An even subgraph of a graph (also known as an Eulerian subgraph) is one where every vertex is incident with an even number of edges; such subgraphs are unions of cycles and isolated vertices. In the following, even subgraphs will be identified with their edge sets, which is equivalent to only considering those even subgraphs which contain all vertices of the full graph.
The set of all even subgraphs of a graph is closed under symmetric difference, and may thus be viewed as a vector space over GF(2); this vector space is called the cycle space of the graph. The cyclomatic number of the graph is defined as the dimension of this space. Since GF(2) has two elements and the cycle space is necessarily finite, the cyclomatic number is also equal to the 2-logarithm of the number of elements in the cycle space.
A basis for the cycle space is easily constructed by first fixing a spanning forest of the graph, and then considering the cycles formed by one edge not in the forest and the path in the forest connecting the endpoints of that edge; these cycles constitute a basis for the cycle space. Hence, the cyclomatic number also equals the number of edges not in a maximal spanning forest of a graph. Since the number of edges in a maximal spanning forest of a graph is equal to the number of vertices minus the number of components, the formula above for the cyclomatic number follows.[7]

For the more topologically inclined, cyclomatic complexity can alternatively be defined as a relative Betti number, the size of a relative homology group:

which is read as "the rank of the first homology group of the graph G, relative to the terminal nodes t". This is a technical way of saying "the number of linearly independent paths through the flow graph from an entry to an exit", where:
- "linearly independent" corresponds to homology, and means one does not double-count backtracking;
- "paths" corresponds to first homology: a path is a 1-dimensional object;
- "relative" means the path must begin and end at an entry or exit point.
This corresponds to the intuitive notion of cyclomatic complexity, and can be calculated as above.
Alternatively, one can compute this via absolute Betti number (absolute homology – not relative) by identifying (gluing together) all the terminal nodes on a given component (or equivalently, draw paths connecting the exits to the entrance), in which case (calling the new, augmented graph , which is ), one obtains


It can also be computed via homotopy. If one considers the control flow graph as a 1-dimensional CW complex called , then the fundamental group of will be . The value of is the cyclomatic complexity. The fundamental group counts how many loops there are through the graph, up to homotopy, and hence aligns with what we would intuitively expect.



This corresponds to the characterization of cyclomatic complexity as "number of loops plus number of components".
Applications
Limiting complexity during development
One of McCabe's original applications was to limit the complexity of routines during program development; he recommended that programmers should count the complexity of the modules they are developing, and split them into smaller modules whenever the cyclomatic complexity of the module exceeded 10.[2] This practice was adopted by the NIST Structured Testing methodology, with an observation that since McCabe's original publication, the figure of 10 had received substantial corroborating evidence, but that in some circumstances it may be appropriate to relax the restriction and permit modules with a complexity as high as 15. As the methodology acknowledged that there were occasional reasons for going beyond the agreed-upon limit, it phrased its recommendation as "For each module, either limit cyclomatic complexity to [the agreed-upon limit] or provide a written explanation of why the limit was exceeded."[8]
Measuring the "structuredness" of a program
Section VI of McCabe's 1976 paper is concerned with determining what the control flow graphs (CFGs) of non-structured programs look like in terms of their subgraphs, which McCabe identifies. (For details on that part see structured program theorem.) McCabe concludes that section by proposing a numerical measure of how close to the structured programming ideal a given program is, i.e. its "structuredness" using McCabe's neologism. McCabe called the measure he devised for this purpose essential complexity.[2]
In order to calculate this measure, the original CFG is iteratively reduced by identifying subgraphs that have a single-entry and a single-exit point, which are then replaced by a single node. This reduction corresponds to what a human would do if they extracted a subroutine from the larger piece of code. (Nowadays such a process would fall under the umbrella term of refactoring.) McCabe's reduction method was later called condensation in some textbooks, because it was seen as a generalization of the condensation to components used in graph theory.[9] If a program is structured, then McCabe's reduction/condensation process reduces it to a single CFG node. In contrast, if the program is not structured, the iterative process will identify the irreducible part. The essential complexity measure defined by McCabe is simply the cyclomatic complexity of this irreducible graph, so it will be precisely 1 for all structured programs, but greater than one for non-structured programs.[8]:80
Implications for software testing
Another application of cyclomatic complexity is in determining the number of test cases that are necessary to achieve thorough test coverage of a particular module.
It is useful because of two properties of the cyclomatic complexity, M, for a specific module:
- M is an upper bound for the number of test cases that are necessary to achieve a complete branch coverage.
- M is a lower bound for the number of paths through the control flow graph (CFG). Assuming each test case takes one path, the number of cases needed to achieve path coverage is equal to the number of paths that can actually be taken. But some paths may be impossible, so although the number of paths through the CFG is clearly an upper bound on the number of test cases needed for path coverage, this latter number (of possible paths) is sometimes less than M.
All three of the above numbers may be equal: branch coverage cyclomatic complexity number of paths.

For example, consider a program that consists of two sequential if-then-else statements.
if (c1())
f1();
else
f2();
if (c2())
f3();
else
f4();
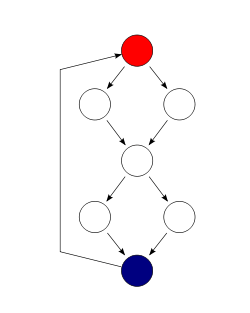
In this example, two test cases are sufficient to achieve a complete branch coverage, while four are necessary for complete path coverage. The cyclomatic complexity of the program is 3 (as the strongly connected graph for the program contains 9 edges, 7 nodes and 1 connected component) (9 − 7 + 1).
In general, in order to fully test a module, all execution paths through the module should be exercised. This implies a module with a high complexity number requires more testing effort than a module with a lower value since the higher complexity number indicates more pathways through the code. This also implies that a module with higher complexity is more difficult for a programmer to understand since the programmer must understand the different pathways and the results of those pathways.
Unfortunately, it is not always practical to test all possible paths through a program. Considering the example above, each time an additional if-then-else statement is added, the number of possible paths grows by a factor of 2. As the program grows in this fashion, it quickly reaches the point where testing all of the paths becomes impractical.
One common testing strategy, espoused for example by the NIST Structured Testing methodology, is to use the cyclomatic complexity of a module to determine the number of white-box tests that are required to obtain sufficient coverage of the module. In almost all cases, according to such a methodology, a module should have at least as many tests as its cyclomatic complexity; in most cases, this number of tests is adequate to exercise all the relevant paths of the function.[8]
As an example of a function that requires more than simply branch coverage to test accurately, consider again the above function, but assume that to avoid a bug occurring, any code that calls either f1() or f3() must also call the other.[lower-alpha 2] Assuming that the results of c1() and c2() are independent, that means that the function as presented above contains a bug. Branch coverage would allow us to test the method with just two tests, and one possible set of tests would be to test the following cases:
c1()returns true andc2()returns truec1()returns false andc2()returns false
Neither of these cases exposes the bug. If, however, we use cyclomatic complexity to indicate the number of tests we require, the number increases to 3. We must therefore test one of the following paths:
c1()returns true andc2()returns falsec1()returns false andc2()returns true
Either of these tests will expose the bug.
Correlation to number of defects
A number of studies have investigated the correlation between McCabe's cyclomatic complexity number with the frequency of defects occurring in a function or method.[10] Some studies[11] find a positive correlation between cyclomatic complexity and defects: functions and methods that have the highest complexity tend to also contain the most defects. However, the correlation between cyclomatic complexity and program size (typically measured in lines of code) has been demonstrated many times. Les Hatton has claimed[12] that complexity has the same predictive ability as lines of code. Studies that controlled for program size (i.e., comparing modules that have different complexities but similar size) are generally less conclusive, with many finding no significant correlation, while others do find correlation. Some researchers who have studied the area question the validity of the methods used by the studies finding no correlation.[13] Although this relation is probably true, it isn't easily utilizable.[14] Since program size is not a controllable feature of commercial software, the usefulness of McCabes's number has been called to question.[10] The essence of this observation is that larger programs tend to be more complex and to have more defects. Reducing the cyclomatic complexity of code is not proven to reduce the number of errors or bugs in that code. International safety standards like ISO 26262, however, mandate coding guidelines that enforce low code complexity.[15]
Artificial intelligence
Cyclomatic complexity may also be used for the evaluation of the semantic complexity of artificial intelligence programs.[16]
Ultrametric topology
Cyclomatic complexity has proven useful in geographical and landscape-ecological analysis, after it was shown that it can be implemented on graphs of ultrametric distances.[17]
See also
- Programming complexity
- Complexity trap
- Computer program
- Computer programming
- Control flow
- Decision-to-decision path
- Design predicates
- Essential complexity (numerical measure of "structuredness")
- Halstead complexity measures
- Software engineering
- Software testing
- Static program analysis
- Synchronization complexity
- Maintainability
Notes
- Here "structured" means in particular "with a single exit (return statement) per function".
- This is a fairly common type of condition; consider the possibility that f1 allocates some resource which f3 releases.
References
- A J Sobey. "Basis Path Testing".
- McCabe (December 1976). "A Complexity Measure". IEEE Transactions on Software Engineering (4): 308–320. doi:10.1109/tse.1976.233837.
- Philip A. Laplante (25 April 2007). What Every Engineer Should Know about Software Engineering. CRC Press. p. 176. ISBN 978-1-4200-0674-2.
- Fricker, Sébastien (April 2018). "What exactly is cyclomatic complexity?". froglogic GmbH. Retrieved October 27, 2018.
To compute a graph representation of code, we can simply disassemble its assembly code and create a graph following the rules: ...
- Belzer, Kent, Holzman and Williams (1992). Encyclopedia of Computer Science and Technology. CRC Press. pp. 367–368.CS1 maint: multiple names: authors list (link)
- Harrison (October 1984). "Applying Mccabe's complexity measure to multiple-exit programs". Software: Practice and Experience. 14 (10): 1004–1007. doi:10.1002/spe.4380141009.
- Diestel, Reinhard (2000). Graph theory. Graduate texts in mathematics 173 (2 ed.). New York: Springer. ISBN 978-0-387-98976-1.
- Arthur H. Watson; Thomas J. McCabe (1996). "Structured Testing: A Testing Methodology Using the Cyclomatic Complexity Metric" (PDF). NIST Special Publication 500-235.
- Paul C. Jorgensen (2002). Software Testing: A Craftsman's Approach, Second Edition (2nd ed.). CRC Press. pp. 150–153. ISBN 978-0-8493-0809-3.
- Norman E Fenton; Martin Neil (1999). "A Critique of Software Defect Prediction Models" (PDF). IEEE Transactions on Software Engineering. 25 (3): 675–689. CiteSeerX 10.1.1.548.2998. doi:10.1109/32.815326.
- Schroeder, Mark (1999). "A Practical guide to object-oriented metrics". IT Professional. 1 (6): 30–36. doi:10.1109/6294.806902. S2CID 14945518.
- Les Hatton (2008). "The role of empiricism in improving the reliability of future software". version 1.1.
- Kan (2003). Metrics and Models in Software Quality Engineering. Addison-Wesley. pp. 316–317. ISBN 978-0-201-72915-3.
- G.S. Cherf (1992). "An Investigation of the Maintenance and Support Characteristics of Commercial Software". Journal of Software Quality. 1 (3): 147–158. doi:10.1007/bf01720922. ISSN 1573-1367.
- ISO 26262-3:2011(en) Road vehicles — Functional safety — Part 3: Concept phase. International Standardization Organization.
- Papadimitriou, Fivos (2012). "Artificial Intelligence in modelling the complexity of Mediterranean landscape transformations". Computers and Electronics in Agriculture. 81: 87–96. doi:10.1016/j.compag.2011.11.009.
- Papadimitriou, Fivos (2013). "Mathematical modelling of land use and landscape complexity with ultrametric topology". Journal of Land Use Science. 8 (2): 234–254. doi:10.1080/1747423X.2011.637136.