Cross-industry standard process for data mining
Cross-industry standard process for data mining, known as CRISP-DM,[1] is an open standard process model that describes common approaches used by data mining experts. It is the most widely-used analytics model.[2]
In 2015, IBM released a new methodology called Analytics Solutions Unified Method for Data Mining/Predictive Analytics[3] [4] (also known as ASUM-DM) which refines and extends CRISP-DM.
History
CRISP-DM was conceived in 1996 and became a European Union project under the ESPRIT funding initiative in 1997. The project was led by five companies: Integral Solutions Ltd (ISL), Teradata, Daimler AG, NCR Corporation and OHRA, an insurance company.
This core consortium brought different experiences to the project: ISL, later acquired and merged into SPSS. The computer giant NCR Corporation produced the Teradata data warehouse and its own data mining software. Daimler-Benz had a significant data mining team. OHRA was just starting to explore the potential use of data mining.
The first version of the methodology was presented at the 4th CRISP-DM SIG Workshop in Brussels in March 1999,[5] and published as a step-by-step data mining guide later that year.[6]
Between 2006 and 2008 a CRISP-DM 2.0 SIG was formed and there were discussions about updating the CRISP-DM process model.[7] The current status of these efforts is not known. However, the original crisp-dm.org website cited in the reviews,[8][9] and the CRISP-DM 2.0 SIG website[7] are both no longer active.
While many non-IBM data mining practitioners use CRISP-DM,[10][11][12] IBM is the primary corporation that currently uses the CRISP-DM process model. It makes some of the old CRISP-DM documents available for download[6] and it has incorporated it into its SPSS Modeler product.
Based on current research CRISP-DM is the most widely used form of data-mining model because of its various advantages which solved the existing problems in the data mining industries. Some of the drawbacks of this model is that it does not perform project management activities. The fact behind the success of CRISP-DM is that it is industry, tool, and application neutral.[13]
Major phases
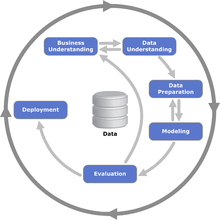
CRISP-DM breaks the process of data mining into six major phases[14]:
- Business Understanding
- Data Understanding
- Data Preparation
- Modeling
- Evaluation
- Deployment
The sequence of the phases is not strict and moving back and forth between different phases as it is always required. The arrows in the process diagram indicate the most important and frequent dependencies between phases. The outer circle in the diagram symbolizes the cyclic nature of data mining itself. A data mining process continues after a solution has been deployed. The lessons learned during the process can trigger new, often more focused business questions, and subsequent data mining processes will benefit from the experiences of previous ones.
Polls
Polls conducted at the same website (KDNuggets) in 2002, 2004, 2007 and 2014 show that it was the leading methodology used by industry data miners who decided to respond to the survey.[10][11][12][15] The only other data mining approach named in these polls was SEMMA. However, SAS Institute clearly states that SEMMA is not a data mining methodology, but rather a "logical organization of the functional toolset of SAS Enterprise Miner." A review and critique of data mining process models in 2009 called the CRISP-DM the "de facto standard for developing data mining and knowledge discovery projects." Other reviews of CRISP-DM and data mining process models include Kurgan and Musilek's 2006 review,[8] and Azevedo and Santos' 2008 comparison of CRISP-DM and SEMMA.[9] Efforts to update the methodology started in 2006, but have As of 30 June 2015 not led to a new version, and the "Special Interest Group" (SIG) responsible along with the website has long disappeared (see History of CRISP-DM).
References
- Shearer C., The CRISP-DM model: the new blueprint for data mining, J Data Warehousing (2000); 5:13—22.
- What IT Needs To Know About The Data Mining Process Published by Forbes, 29 July 2015, retrieved June 24, 2018
- Have you seen ASUM-DM?, By Jason Haffar, 16 October 2015, SPSS Predictive Analytics, IBM Archived 8 March 2016 at the Wayback Machine
- Analytics Solutions Unified Method - Implementations with Agile principles Published by IBM, 1 March 2016, retrieved October 5, 2018
- Pete Chapman (1999); The CRISP-DM User Guide.
- Pete Chapman, Julian Clinton, Randy Kerber, Thomas Khabaza, Thomas Reinartz, Colin Shearer, and Rüdiger Wirth (2000); CRISP-DM 1.0 Step-by-step data mining guides.
- Colin Shearer (2006); First CRISP-DM 2.0 Workshop Held
- Lukasz Kurgan and Petr Musilek (2006); A survey of Knowledge Discovery and Data Mining process models. The Knowledge Engineering Review. Volume 21 Issue 1, March 2006, pp 1–24, Cambridge University Press, New York, NY, USA doi: 10.1017/S0269888906000737.
- Azevedo, A. and Santos, M. F. (2008); KDD, SEMMA and CRISP-DM: a parallel overview. In Proceedings of the IADIS European Conference on Data Mining 2008, pp 182–185.
- Gregory Piatetsky-Shapiro (2002); KDnuggets Methodology Poll
- Gregory Piatetsky-Shapiro (2004); KDnuggets Methodology Poll
- Gregory Piatetsky-Shapiro (2007); KDnuggets Methodology Poll
- Mariscal,G.,Marban,O.,Fernandez,C. "A Survey of Data Mining and knowledge discovery process Models and methodologies". The Knowledge Engineering Review. doi:10.1017/S0269888910000032.CS1 maint: multiple names: authors list (link)
- Harper, Gavin; Stephen D. Pickett (August 2006). "Methods for mining HTS data". Drug Discovery Today. 11 (15–16): 694–699. doi:10.1016/j.drudis.2006.06.006. PMID 16846796.
- Gregory Piatetsky-Shapiro (2014); KDnuggets Methodology Poll