Cohort model
The cohort model in psycholinguistics and neurolinguistics is a model of lexical retrieval first proposed by William Marslen-Wilson in the late 1970s.[1] It attempts to describe how visual or auditory input (i.e., hearing or reading a word) is mapped onto a word in a hearer's lexicon.[2] According to the model, when a person hears speech segments real-time, each speech segment "activates" every word in the lexicon that begins with that segment, and as more segments are added, more words are ruled out, until only one word is left that still matches the input.
Background information
The cohort model relies on a number of concepts in the theory of lexical retrieval. The lexicon is the store of words in a person's mind.;[3] it contains a person's vocabulary and is similar to a mental dictionary. A lexical entry is all the information about a word and the lexical storage is the way the items are stored for peak retrieval. Lexical access is the way that an individual accesses the information in the mental lexicon. A word's cohort is composed of all the lexical items that share an initial sequence of phonemes,[4] and is the set of words activated by the initial phonemes of the word.
Model
The cohort model is based on the concept that auditory or visual input to the brain stimulates neurons as it enters the brain, rather than at the end of a word.[5] This fact was demonstrated in the 1980s through experiments with speech shadowing, in which subjects listened to recordings and were instructed to repeat aloud exactly what they heard, as quickly as possible; Marslen-Wilson found that the subjects often started to repeat a word before it had actually finished playing, which suggested that the word in the hearer's lexicon was activated before the entire word had been heard.[6] Findings such as these led Marslen-Wilson to propose the cohort model in 1987.[7]
The cohort model consists of three stages: access, selection, and integration.[8] Under this model, auditory lexical retrieval begins with the first one or two speech segments, or phonemes, reach the hearer's ear, at which time the mental lexicon activates every possible word that begins with that speech segment.[9] This occurs during the "access stage" and all of the possible words are known as the cohort.[10] The words that are activated by the speech signal but are not the intended word are often called "competitors."[11] Identification of the target word is more difficult with more competitors.[12] As more speech segments enter the ear and stimulate more neurons, causing the competitors that no longer match the input to be "kicked out" or to decrease in activation.[9][13] The processes by which words are activated and competitors rejected in the cohort model are frequently called "activation and selection" or "recognition and competition". These processes continue until an instant, called the recognition point,[9] at which only one word remains activated and all competitors have been kicked out. The recognition point process is initiated within the first 200 to 250 milliseconds of the onset of the given word.[14] This is also known as the uniqueness point and it is the point where the most processing occurs.[10] Moreover, there is a difference in the way a word is processed before it reaches its recognition point and afterwards. One can look at the process prior to reaching the recognition point as bottom-up, where the phonemes are used to access the lexicon. The post recognition point process is top-down, because the information concerning the chosen word is tested against the word that is presented.[15] The selection stage occurs when only one word is left from the set.[10] Finally, in the integration stage, the semantic and syntactic properties of activated words are incorporated into the high-level utterance representation.[8]
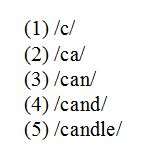
For example, in the auditory recognition of the word "candle", the following steps take place. When the hearer hears the first two phonemes /k/ and /æ/ ((1) and (2) in the image), he or she would activate the word "candle", along with competitors such as "candy", "can", "cattle", and numerous others. Once the phoneme /n/ is added ((3) in the image), "cattle" would be kicked out; with /d/, "can" would be kicked out; and this process would continue until the recognition point, the final /l/ of "candle", were reached ((5) in the image).[16] The recognition point need not always be the final phoneme of the word; the recognition point of "slander", for example, occurs at the /d/ (since no other English words begin "sland-");[6] all competitors for "spaghetti" are ruled out as early as /spəɡ/;[16] Jerome Packard has demonstrated that the recognition point of the Chinese word huŏchē ("train") occurs before huŏch-;[17] and a landmark study by Pienie Zwitserlood demonstrated that the recognition point of the Dutch word kapitein (captain) was at the vowel before the final /n/.[18]
Since its original proposal, the model has been adjusted to allow for the role that context plays in helping the hearer rule out competitors,[9] and the fact that activation is "tolerant" to minor acoustic mismatches that arise because of coarticulation (a property by which language sounds are slightly changed by the sounds preceding and following them).[19]
Experimental evidence
Much evidence in favor of the cohort model has come from priming studies, in which a "priming word" is presented to a subject and then closely followed by a "target word" and the subject asked to identify if the target word is a real word or not; the theory behind the priming paradigm is that if a word is activated in the subject's mental lexicon, the subject will be able to respond more quickly to the target word.[20] If the subject does respond more quickly, the target word is said to be "primed" by the priming word. Several priming studies have found that when a stimulus that does not reach recognition point is presented, numerous words targets were all primed, whereas if a stimulus past recognition point is presented, only one word is primed. For example, in Pienie Zwitserlood's study of Dutch compared the words kapitein ("captain") and kapitaal ("capital" or "money"); in the study, the stem kapit- primed both boot ("boat", semantically related to kapitein) and geld ("money", semantically related to kapitaal), suggesting that both lexical entries were activated; the full word kapitein, on the other hand, primed only boot and not geld.[18] Furthermore, experiments have shown that in tasks where subjects must differentiate between words and non-words, reaction times were faster for longer words with phonemic points of discrimination earlier in the word. For example, discriminating between Crocodile and Dial, the point of recognition to discriminate between the two words comes at the /d/ in crocodile which is much earlier than the /l/ sound in Dial.[21]
Later experiments refined the model. For example, some studies showed that "shadowers" (subjects who listen to auditory stimuli and repeat it as quickly as possible) could not shadow as quickly when words were jumbled up so they didn't mean anything; those results suggested that sentence structure and speech context also contribute to the process of activation and selection.[6]
Research in bilinguals has found that word recognition is influenced by the number of neighbors in both languages.[22]
References
- William D. Marslen-Wilson and Alan Welsh (1978) Processing Interactions and Lexical Access during Word Recognition in Continuous Speech. Cognitive Psychology,10,29–63
- Kennison, Shelia (2019). Psychology of language: Theories and applications. Red Globe Press. ISBN 978-1137545268.
- , The Free Dictionary
- ^ Fernandez, E.M. & Smith Cairns, H. (2011). Fundamentals of Psycholinguistics (Malden, MZ: Wiley-Blackwell). ISBN 978-1-4051-9147-0 (
- Altmann, 71.
- Altmann, 70.
- Marslen-Wilson, W. (1987). "Functional parallelism in spoken word recognition." Cognition, 25, 71-102.
- Gaskell, M. Gareth; William D. Marslen-Wilson (1997). "Integrating Form and Meaning: A Distributed Model of Speech Perception". Language and Cognitive Processes. 12 (5/6): 613–656. doi:10.1080/016909697386646. Retrieved 11 April 2013.
- Packard, 288.
- HARLEY, T. A. (2009). Psychology of language, from data to theory. New York: Psychology Pr.
- Ibrahim, Raphiq (2008). "Does Visual and Auditory Word Perception have a Language-Selective Input? Evidence from Word Processing in Semitic languages". The Linguistics Journal. 3 (2). Archived from the original on 5 December 2008. Retrieved 21 November 2008.
- http://www.inf.ed.ac.uk/teaching/courses/cm/lectures/cm19_wordrec-2x2.pdf, Goldwater, Sharon (2010).
- Altmann, 74.
- Fernandez, E.M. & Smith Cairns, H. (2011). Fundamentals of Psycholinguistics (Malden, MZ: Wiley-Blackwell). ISBN 978-1-4051-9147-0 (
- Taft, M., & Hambly, G. (1986). Exploring the cohort model of spoken word recognition. Cognition, 22(3), 259-282.
- Brysbaert, Marc, and Ton Dijkstra (2006). "Changing views on word recognition in bilinguals." in Bilingualism and second language acquisition, eds. Morais, J. & d’Ydewalle, G. Brussels: KVAB.
- Packard, 289.
- Altmann, 72.
- Altmann, 75.
- Packard, 295.
- Taft, 264.
- Van Heuven, W.J.B., Dijkstra, T., & Grainger, J. (1998). "Orthographic Neighborhood Effects in Bilingual Word Recognition." Journal of Memory and Language. pp. 458-483.
- Altmann, Gerry T.M. (1997). "Words, and how we (eventually) find them." The Ascent of Babel: An Exploration of Language, Mind, and Understanding. Oxford: Oxford University Press. pp. 65–83.
- Packard, Jerome L (2000). "Chinese words and the lexicon." The Morphology of Chinese: A Linguistic and Cognitive Approach. Cambridge: Cambridge University Press. pp. 284–309.
- Taft, Marcus, and Gail Hambly(1986). "Exploring the Cohort Model of spoken word recognition." Netherlands: Elsevier Sequoia. 259-264.