Coalesced hashing
Coalesced hashing, also called coalesced chaining, is a strategy of collision resolution in a hash table that forms a hybrid of separate chaining and open addressing.
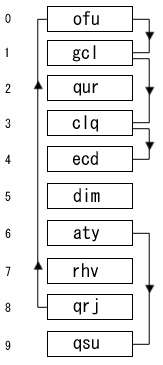
Separate chaining hash table
In a separate chaining hash table, items that hash to the same address are placed on a list (or "chain") at that address. This technique can result in a great deal of wasted memory because the table itself must be large enough to maintain a load factor that performs well (typically twice the expected number of items), and extra memory must be used for all but the first item in a chain (unless list headers are used, in which case extra memory must be used for all items in a chain).
Example
Given a sequence "qrj," "aty," "qur," "dim," "ofu," "gcl," "rhv," "clq," "ecd," "qsu" of randomly generated three character long strings, the following table would be generated (using Bob Jenkins' One-at-a-Time hash algorithm) with a table of size 10:
| (null) | |||
| "clq" | |||
| "qur" | |||
| (null) | |||
| (null) | |||
| "dim" | |||
| "aty" | "qsu" | ||
| "rhv" | |||
| "qrj" | "ofu" | "gcl" | "ecd" |
| (null) |
This strategy is effective, efficient, and very easy to implement. However, sometimes the extra memory use might be prohibitive, and the most common alternative, open addressing, has uncomfortable disadvantages that decrease performance. The primary disadvantage of open addressing is primary and secondary clustering, in which searches may access long sequences of used buckets that contain items with different hash addresses; items with one hash address can thus lengthen searches for items with other hash addresses.
One solution to these issues is coalesced hashing. Coalesced hashing uses a similar technique as separate chaining, but instead of allocating new nodes for the linked list, buckets in the actual table are used. The first empty bucket in the table at the time of a collision is considered the collision bucket. When a collision occurs anywhere in the table, the item is placed in the collision bucket and a link is made between the chain and the collision bucket. It is possible for a newly inserted item to collide with items with a different hash address, such as the case in the example in the image when item "clq" is inserted. The chain for "clq" is said to "coalesce" with the chain of "qrj," hence the name of the algorithm. However, the extent of coalescing is minor compared with the clustering exhibited by open addressing. For example, when coalescing occurs, the length of the chain grows by only 1, whereas in open addressing, search sequences of arbitrary length may combine.
The cellar
An important optimization, to reduce the effect of coalescing, is to restrict the address space of the hash function to only a subset of the table. For example, if the table has size M with buckets numbered from 0 to M − 1, we can restrict the address space so that the hash function only assigns addresses to the first N locations in the table. The remaining M − N buckets, called the cellar, are used exclusively for storing items that collide during insertion. No coalescing can occur until the cellar is exhausted.
The optimal choice of N relative to M depends upon the load factor (or fullness) of the table. A careful analysis shows that the value N = 0.86 × M yields near-optimum performance for most load factors.[1][2]
Variants
Other variants for insertion are also possible that have improved search time. Deletion algorithms have been developed that preserve randomness, and thus the average search time analysis still holds after deletions.[1]
Implementation
Insertion in C:
/* htab is the hash table,
N is the size of the address space of the hash function, and
M is the size of the entire table including the cellar.
Collision buckets are allocated in decreasing order, starting with bucket M-1. */
int insert ( char key[] )
{
unsigned h = hash ( key, strlen ( key ) ) % N;
if ( htab[h] == NULL ) {
/* Make a new chain */
htab[h] = make_node ( key, NULL );
} else {
struct node *it;
int cursor = M-1;
/* Find the first empty bucket */
while ( cursor >= 0 && htab[cursor] != NULL )
--cursor;
/* The table is full, terminate unsuccessfully */
if ( cursor == -1 )
return -1;
htab[cursor] = make_node ( key, NULL );
/* Find the last node in the chain and point to it */
it = htab[h];
while ( it->next != NULL )
it = it->next;
it->next = htab[cursor];
}
return 0;
}
One benefit of this strategy is that the search algorithm for separate chaining can be used without change in a coalesced hash table.
Lookup in C:
char *find ( char key[] )
{
unsigned h = hash ( key, strlen ( key ) ) % N;
if ( htab[h] != NULL ) {
struct node *it;
/* Search the chain at index h */
for ( it = htab[h]; it != NULL; it = it->next ) {
if ( strcmp ( key, it->data ) == 0 )
return it->data;
}
}
return NULL;
}
Performance
Coalesced chaining avoids the effects of primary and secondary clustering, and as a result can take advantage of the efficient search algorithm for separate chaining. If the chains are short, this strategy is very efficient and can be highly condensed, memory-wise. As in open addressing, deletion from a coalesced hash table is awkward and potentially expensive, and resizing the table is terribly expensive and should be done rarely, if ever.
References
- J. S. Vitter and W.-C. Chen, Design and Analysis of Coalesced Hashing, Oxford University Press, New York, NY, 1987, ISBN 0-19-504182-8
- Jiří Vyskočil, Marko Genyk-Berezovskyj. "Coalesced hashing". 2010.
- Paul E. Black. "coalesced chaining". Dictionary of Algorithms and Data Structures [online]. Vreda Pieterse and Paul E. Black, eds. 16 November 2009. (accessed 2016-07-29). Available from: https://xlinux.nist.gov/dads/HTML/coalescedChaining.html
- Grant Weddell. "Hashing". p. 10-11.