Burst error-correcting code
In coding theory, burst error-correcting codes employ methods of correcting burst errors, which are errors that occur in many consecutive bits rather than occurring in bits independently of each other.
Many codes have been designed to correct random errors. Sometimes, however, channels may introduce errors which are localized in a short interval. Such errors occur in a burst (called burst errors) because they occur in many consecutive bits. Examples of burst errors can be found extensively in storage mediums. These errors may be due to physical damage such as scratch on a disc or a stroke of lightning in case of wireless channels. They are not independent; they tend to be spatially concentrated. If one bit has an error, it is likely that the adjacent bits could also be corrupted. The methods used to correct random errors are inefficient to correct burst errors.
Definitions
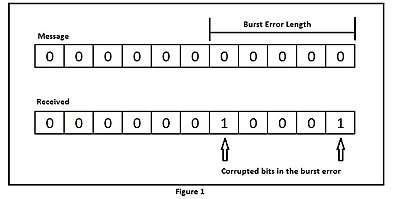
A burst of length [1]

Say a codeword is transmitted, and it is received as Then, the error vector is called a burst of length if the nonzero components of are confined to consecutive components. For example, is a burst of length





Although this definition is sufficient to describe what a burst error is, the majority of the tools developed for burst error correction rely on cyclic codes. This motivates our next definition.
A cyclic burst of length [1]
An error vector is called a cyclic burst error of length if its nonzero components are confined to cyclically consecutive components. For example, the previously considered error vector , is a cyclic burst of length , since we consider the error starting at position and ending at position . Notice the indices are -based, that is, the first element is at position .





For the remainder of this article, we will use the term burst to refer to a cyclic burst, unless noted otherwise.
Burst description
It is often useful to have a compact definition of a burst error, that encompasses not only its length, but also the pattern, and location of such error. We define a burst description to be a tuple where is the pattern of the error (that is the string of symbols beginning with the first nonzero entry in the error pattern, and ending with the last nonzero symbol), and is the location, on the codeword, where the burst can be found.[1]



For example, the burst description of the error pattern is . Notice that such description is not unique, because describes the same burst error. In general, if the number of nonzero components in is , then will have different burst descriptions each starting at a different nonzero entry of . To remedy the issues that arise by the ambiguity of burst descriptions with the theorem below, however before doing so we need a definition first.



Definition. The number of symbols in a given error pattern is denoted by


- Theorem (Uniqueness of burst descriptions). Suppose is an error vector of length with two burst descriptions and . If then the two descriptions are identical that is, their components are equivalent.[2]




- Proof. Let be the hamming weight (or the number of nonzero entries) of . Then has exactly error descriptions. For there is nothing to prove. So we assume that and that the descriptions are not identical. We notice that each nonzero entry of will appear in the pattern, and so, the components of not included in the pattern will form a cyclic run of zeros, beginning after the last nonzero entry, and continuing just before the first nonzero entry of the pattern. We call the set of indices corresponding to this run as the zero run. We immediately observe that each burst description has a zero run associated with it and that each zero run is disjoint. Since we have zero runs, and each is disjoint, we have a total of distinct elements in all the zero runs. On the other hand we have:
- This contradicts Thus, the burst error descriptions are identical.





A corollary of the above theorem is that we cannot have two distinct burst descriptions for bursts of length

Cyclic codes for burst error correction
Cyclic codes are defined as follows: think of the symbols as elements in . Now, we can think of words as polynomials over where the individual symbols of a word correspond to the different coefficients of the polynomial. To define a cyclic code, we pick a fixed polynomial, called generator polynomial. The codewords of this cyclic code are all the polynomials that are divisible by this generator polynomial.



Codewords are polynomials of degree . Suppose that the generator polynomial has degree . Polynomials of degree that are divisible by result from multiplying by polynomials of degree . We have such polynomials. Each one of them corresponds to a codeword. Therefore, for cyclic codes.






Cyclic codes can detect all bursts of length up to . We will see later that the burst error detection ability of any code is bounded from above by . Cyclic codes are considered optimal for burst error detection since they meet this upper bound:



- Theorem (Cyclic burst correction capability). Every cyclic code with generator polynomial of degree can detect all bursts of length

- Proof. We need to prove that if you add a burst of length to a codeword (i.e. to a polynomial that is divisible by ), then the result is not going to be a codeword (i.e. the corresponding polynomial is not divisible by ). It suffices to show that no burst of length is divisible by . Such a burst has the form , where Therefore, is not divisible by (because the latter has degree ). is not divisible by (Otherwise, all codewords would start with ). Therefore, is not divisible by as well.






The above proof suggests a simple algorithm for burst error detection/correction in cyclic codes: given a transmitted word (i.e. a polynomial of degree ), compute the remainder of this word when divided by . If the remainder is zero (i.e. if the word is divisible by ), then it is a valid codeword. Otherwise, report an error. To correct this error, subtract this remainder from the transmitted word. The subtraction result is going to be divisible by (i.e. it is going to be a valid codeword).
By the upper bound on burst error detection (), we know that a cyclic code can not detect all bursts of length . However cyclic codes can indeed detect most bursts of length . The reason is that detection fails only when the burst is divisible by . Over binary alphabets, there exist bursts of length . Out of those, only are divisible by . Therefore, the detection failure probability is very small () assuming a uniform distribution over all bursts of length .






We now consider a fundamental theorem about cyclic codes that will aid in designing efficient burst-error correcting codes, by categorizing bursts into different cosets.
- Theorem (Distinct Cosets). A linear code is an -burst-error-correcting code if all the burst errors of length lie in distinct cosets of .

- Proof. Let be distinct burst errors of length which lie in same coset of code . Then is a codeword. Hence, if we receive we can decode it either to or . In contrast, if all the burst errors and do not lie in same coset, then each burst error is determined by its syndrome. The error can then be corrected through its syndrome. Thus, a linear code is an -burst-error-correcting code if and only if all the burst errors of length lie in distinct cosets of .







- Theorem (Burst error codeword classification). Let be a linear -burst-error-correcting code. Then no nonzero burst of length can be a codeword.

- Proof. Let be a codeword with a burst of length . Thus it has the pattern , where and are words of length Hence, the words and are two bursts of length . For binary linear codes, they belong to the same coset. This contradicts the Distinct Cosets Theorem, therefore no nonzero burst of length can be a codeword.







Burst error correction bounds
Upper bounds on burst error detection and correction
By upper bound, we mean a limit on our error detection ability that we can never go beyond. Suppose that we want to design an code that can detect all burst errors of length A natural question to ask is: given and , what is the maximum that we can never achieve beyond? In other words, what is the upper bound on the length of bursts that we can detect using any code? The following theorem provides an answer to this question.


- Theorem (Burst error detection ability). The burst error detection ability of any code is

- Proof. First we observe that a code can detect all bursts of length if and only if no two codewords differ by a burst of length . Suppose that we have two code words and that differ by a burst of length . Upon receiving , we can not tell whether the transmitted word is indeed with no transmission errors, or whether it is with a burst error that occurred during transmission. Now, suppose that every two codewords differ by more than a burst of length Even if the transmitted codeword is hit by a burst of length , it is not going to change into another valid codeword. Upon receiving it, we can tell that this is with a burst By the above observation, we know that no two codewords can share the first symbols. The reason is that even if they differ in all the other symbols, they are still going to be different by a burst of length Therefore, the number of codewords satisfies Applying to both sides and rearranging, we can see that .









Now, we repeat the same question but for error correction: given and , what is the upper bound on the length of bursts that we can correct using any code? The following theorem provides a preliminary answer to this question:
- Theorem (Burst error correction ability). The burst error correction ability of any code satisfies

- Proof. First we observe that a code can correct all bursts of length if and only if no two codewords differ by the sum of two bursts of length Suppose that two codewords and differ by bursts and of length each. Upon receiving hit by a burst , we could interpret that as if it was hit by a burst . We can not tell whether the transmitted word is or . Now, suppose that every two codewords differ by more than two bursts of length . Even if the transmitted codeword is hit by a burst of length , it is not going to look like another codeword that has been hit by another burst. For each codeword let denote the set of all words that differ from by a burst of length Notice that includes itself. By the above observation, we know that for two different codewords and and are disjoint. We have codewords. Therefore, we can say that . Moreover, we have . By plugging the latter inequality into the former, then taking the base logarithm and rearranging, we get the above theorem.










A stronger result is given by the Rieger bound:
- Theorem (Rieger bound). If is the burst error correcting ability of an linear block code, then .

- Proof. Any linear code that can correct any burst pattern of length cannot have a burst of length as a codeword. If it had a burst of length as a codeword, then a burst of length could change the codeword to a burst pattern of length , which also could be obtained by making a burst error of length in all zero codeword. If vectors are non-zero in first symbols, then the vectors should be from different subsets of an array so that their difference is not a codeword of bursts of length . Ensuring this condition, the number of such subsets is at least equal to number of vectors. Thus, the number of subsets would be at least . Hence, we have at least distinct symbols, otherwise, the difference of two such polynomials would be a codeword that is a sum of two bursts of length Thus, this proves the Rieger Bound.


Definition. A linear burst-error-correcting code achieving the above Rieger bound is called an optimal burst-error-correcting code.
Further bounds on burst error correction
There is more than one upper bound on the achievable code rate of linear block codes for multiple phased-burst correction (MPBC). One such bound is constrained to a maximum correctable cyclic burst length within every subblock, or equivalently a constraint on the minimum error free length or gap within every phased-burst. This bound, when reduced to the special case of a bound for single burst correction, is the Abramson bound (a corollary of the Hamming bound for burst-error correction) when the cyclic burst length is less than half the block length.[3]
- Theorem (number of bursts). For over a binary alphabet, there are vectors of length which are bursts of length .[1]


- Proof. Since the burst length is there is a unique burst description associated with the burst. The burst can begin at any of the positions of the pattern. Each pattern begins with and contain a length of . We can think of it as the set of all strings that begin with and have length . Thus, there are a total of possible such patterns, and a total of bursts of length If we include the all-zero burst, we have vectors representing bursts of length



- Theorem (Bound on the number of codewords). If a binary -burst error correcting code has at most codewords.

- Proof. Since , we know that there are bursts of length . Say the code has codewords, then there are codewords that differ from a codeword by a burst of length . Each of the words must be distinct, otherwise the code would have distance . Therefore, implies






- Theorem (Abramson's bounds). If is a binary linear -burst error correcting code, its block-length must satisfy:



- Proof: For a linear code, there are codewords. By our previous result, we know that
- Isolating , we get . Since and must be an integer, we have .





Remark. is called the redundancy of the code and in an alternative formulation for the Abramson's bounds is


Fire codes[3][4][5]
While cyclic codes in general are powerful tools for detecting burst errors, we now consider a family of binary cyclic codes named Fire Codes, which possess good single burst error correction capabilities. By single burst, say of length , we mean that all errors that a received codeword possess lie within a fixed span of digits.
Let be an irreducible polynomial of degree over , and let be the period of . The period of , and indeed of any polynomial, is defined to be the least positive integer such that Let be a positive integer satisfying and not divisible by , where is the period of . Define the Fire Code by the following generator polynomial:









We will show that is an -burst-error correcting code.
- Lemma 1.

- Proof. Let be the greatest common divisor of the two polynomials. Since is irreducible, or . Assume then for some constant . But, is a divisor of since is a divisor of . But this contradicts our assumption that does not divide Thus, proving the lemma.









- Lemma 2. If is a polynomial of period , then if and only if


- Proof. If , then . Thus,



- Now suppose . Then, . We show that is divisible by by induction on . The base case follows. Therefore, assume . We know that divides both (since it has period )




- But is irreducible, therefore it must divide both and ; thus, it also divides the difference of the last two polynomials, . Then, it follows that divides . Finally, it also divides: . By the induction hypothesis, , then .






A corollary to Lemma 2 is that since has period , then divides if and only if .


If we can show that all bursts of length or less occur in different cosets, we can use them as coset leaders that form correctable error patterns. The reason is simple: we know that each coset has a unique syndrome decoding associated with it, and if all bursts of different lengths occur in different cosets, then all have unique syndromes, facilitating error correction.
Proof of Theorem
Let and be polynomials with degrees and , representing bursts of length and respectively with The integers represent the starting positions of the bursts, and are less than the block length of the code. For contradiction sake, assume that and are in the same coset. Then, is a valid codeword (since both terms are in the same coset). Without loss of generality, pick . By the division theorem we can write: for integers and . We rewrite the polynomial as follows:















Notice that at the second manipulation, we introduced the term . We are allowed to do so, since Fire Codes operate on . By our assumption, is a valid codeword, and thus, must be a multiple of . As mentioned earlier, since the factors of are relatively prime, has to be divisible by . Looking closely at the last expression derived for we notice that is divisible by (by the corollary of Lemma 2). Therefore, is either divisible by or is . Applying the division theorem again, we see that there exists a polynomial with degree such that:





Then we may write:

Equating the degree of both sides, gives us Since we can conclude which implies and . Notice that in the expansion:






the term appears, but since , the resulting expression does not contain , therefore and subsequently This requires that , and . We can further revise our division of by to reflect that is . Substituting back into gives us,












Since , we have . But is irreducible, therefore and must be relatively prime. Since is a codeword, must be divisible by , as it cannot be divisible by . Therefore, must be a multiple of . But it must also be a multiple of , which implies it must be a multiple of but that is precisely the block-length of the code. Therefore, cannot be a multiple of since they are both less than . Thus, our assumption of being a codeword is incorrect, and therefore and are in different cosets, with unique syndromes, and therefore correctable.




Example: 5-burst error correcting fire code
With the theory presented in the above section, consider the construction of a -burst error correcting Fire Code. Remember that to construct a Fire Code, we need an irreducible polynomial , an integer , representing the burst error correction capability of our code, and we need to satisfy the property that is not divisible by the period of . With these requirements in mind, consider the irreducible polynomial , and let . Since is a primitive polynomial, its period is . We confirm that is not divisible by . Thus,






is a Fire Code generator. We can calculate the block-length of the code by evaluating the least common multiple of and . In other words, . Thus, the Fire Code above is a cyclic code capable of correcting any burst of length or less.

Binary Reed–Solomon codes
Certain families of codes, such as Reed–Solomon, operate on alphabet sizes larger than binary. This property awards such codes powerful burst error correction capabilities. Consider a code operating on . Each symbol of the alphabet can be represented by bits. If is an Reed–Solomon code over , we can think of as an code over .


The reason such codes are powerful for burst error correction is that each symbol is represented by bits, and in general, it is irrelevant how many of those bits are erroneous; whether a single bit, or all of the bits contain errors, from a decoding perspective it is still a single symbol error. In other words, since burst errors tend to occur in clusters, there is a strong possibility of several binary errors contributing to a single symbol error.
Notice that a burst of errors can affect at most symbols, and a burst of can affect at most symbols. Then, a burst of can affect at most symbols; this implies that a -symbols-error correcting code can correct a burst of length at most .








In general, a -error correcting Reed–Solomon code over can correct any combination of

or fewer bursts of length , on top of being able to correct -random worst case errors.

An example of a binary RS code
Let be a RS code over . This code was employed by NASA in their Cassini-Huygens spacecraft.[6] It is capable of correcting symbol errors. We now construct a Binary RS Code from . Each symbol will be written using bits. Therefore, the Binary RS code will have as its parameters. It is capable of correcting any single burst of length .







Interleaved codes
Interleaving is used to convert convolutional codes from random error correctors to burst error correctors. The basic idea behind the use of interleaved codes is to jumble symbols at the receiver. This leads to randomization of bursts of received errors which are closely located and we can then apply the analysis for random channel. Thus, the main function performed by the interleaver at transmitter is to alter the input symbol sequence. At the receiver, the deinterleaver will alter the received sequence to get back the original unaltered sequence at the transmitter.
Burst error correcting capacity of interleaver
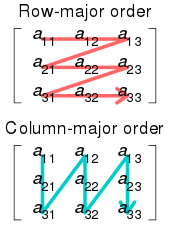
- Theorem. If the burst error correcting ability of some code is then the burst error correcting ability of its -way interleave is



- Proof: Suppose that we have an code that can correct all bursts of length Interleaving can provide us with a code that can correct all bursts of length for any given . If we want to encode a message of an arbitrary length using interleaving, first we divide it into blocks of length . We write the entries of each block into a matrix using row-major order. Then, we encode each row using the code. What we will get is a matrix. Now, this matrix is read out and transmitted in column-major order. The trick is that if there occurs a burst of length in the transmitted word, then each row will contain approximately consecutive errors (More specifically, each row will contain a burst of length at least and at most ). If then and the code can correct each row. Therefore, the interleaved code can correct the burst of length . Conversely, if then at least one row will contain more than consecutive errors, and the code might fail to correct them. Therefore, the error correcting ability of the interleaved code is exactly The BEC efficiency of the interleaved code remains the same as the original code. This is true because:













Block interleaver
The figure below shows a 4 by 3 interleaver.
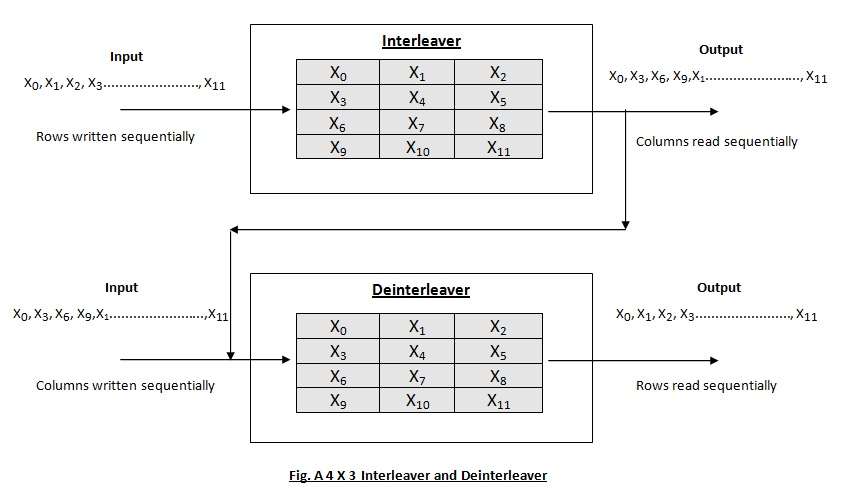
The above interleaver is called as a block interleaver. Here, the input symbols are written sequentially in the rows and the output symbols are obtained by reading the columns sequentially. Thus, this is in the form of array. Generally, is length of the codeword.


Capacity of block interleaver: For an block interleaver and burst of length the upper limit on number of errors is This is obvious from the fact that we are reading the output column wise and the number of rows is . By the theorem above for error correction capacity up to the maximum burst length allowed is For burst length of , the decoder may fail.




Efficiency of block interleaver (): It is found by taking ratio of burst length where decoder may fail to the interleaver memory. Thus, we can formulate as


Drawbacks of block interleaver : As it is clear from the figure, the columns are read sequentially, the receiver can interpret single row only after it receives complete message and not before that. Also, the receiver requires a considerable amount of memory in order to store the received symbols and has to store the complete message. Thus, these factors give rise to two drawbacks, one is the latency and other is the storage (fairly large amount of memory). These drawbacks can be avoided by using the convolutional interleaver described below.
Convolutional interleaver
Cross interleaver is a kind of multiplexer-demultiplexer system. In this system, delay lines are used to progressively increase length. Delay line is basically an electronic circuit used to delay the signal by certain time duration. Let be the number of delay lines and be the number of symbols introduced by each delay line. Thus, the separation between consecutive inputs = symbols. Let the length of codeword Thus, each symbol in the input codeword will be on distinct delay line. Let a burst error of length occur. Since the separation between consecutive symbols is the number of errors that the deinterleaved output may contain is By the theorem above, for error correction capacity up to , maximum burst length allowed is For burst length of decoder may fail.







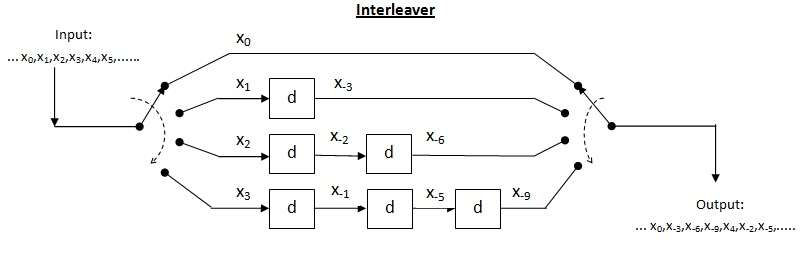

Efficiency of cross interleaver (): It is found by taking the ratio of burst length where decoder may fail to the interleaver memory. In this case, the memory of interleaver can be calculated as

Thus, we can formulate as follows:

Performance of cross interleaver : As shown in the above interleaver figure, the output is nothing but the diagonal symbols generated at the end of each delay line. In this case, when the input multiplexer switch completes around half switching, we can read first row at the receiver. Thus, we need to store maximum of around half message at receiver in order to read first row. This drastically brings down the storage requirement by half. Since just half message is now required to read first row, the latency is also reduced by half which is good improvement over the block interleaver. Thus, the total interleaver memory is split between transmitter and receiver.
Applications
Compact disc
Without error correcting codes, digital audio would not be technically feasible.[7] The Reed–Solomon codes can correct a corrupted symbol with a single bit error just as easily as it can correct a symbol with all bits wrong. This makes the RS codes particularly suitable for correcting burst errors.[5] By far, the most common application of RS codes is in compact discs. In addition to basic error correction provided by RS codes, protection against burst errors due to scratches on the disc is provided by a cross interleaver.[3]
Current compact disc digital audio system was developed by N. V. Philips of The Netherlands and Sony Corporation of Japan (agreement signed in 1979).
A compact disc comprises a 120 mm aluminized disc coated with a clear plastic coating, with spiral track, approximately 5 km in length, which is optically scanned by a laser of wavelength ~0.8 μm, at a constant speed of ~1.25 m/s. For achieving this constant speed, rotation of the disc is varied from ~8 rev/s while scanning at the inner portion of the track to ~3.5 rev/s at the outer portion. Pits and lands are the depressions (0.12 μm deep) and flat segments constituting the binary data along the track (0.6 μm width).[8]
The CD process can be abstracted as a sequence of the following sub-processes: -> Channel encoding of source of signals -> Mechanical sub-processes of preparing a master disc, producing user discs and sensing the signals embedded on user discs while playing – the channel -> Decoding the signals sensed from user discs
The process is subject to both burst errors and random errors.[7] Burst errors include those due to disc material (defects of aluminum reflecting film, poor reflective index of transparent disc material), disc production (faults during disc forming and disc cutting etc.), disc handling (scratches – generally thin, radial and orthogonal to direction of recording) and variations in play-back mechanism. Random errors include those due to jitter of reconstructed signal wave and interference in signal. CIRC (Cross-Interleaved Reed–Solomon code) is the basis for error detection and correction in the CD process. It corrects error bursts up to 3,500 bits in sequence (2.4 mm in length as seen on CD surface) and compensates for error bursts up to 12,000 bits (8.5 mm) that may be caused by minor scratches.
Encoding: Sound-waves are sampled and converted to digital form by an A/D converter. The sound wave is sampled for amplitude (at 44.1 kHz or 44,100 pairs, one each for the left and right channels of the stereo sound). The amplitude at an instance is assigned a binary string of length 16. Thus, each sample produces two binary vectors from or 4 bytes of data. Every second of sound recorded results in 44,100 × 32 = 1,411,200 bits (176,400 bytes) of data.[5] The 1.41 Mbit/s sampled data stream passes through the error correction system eventually getting converted to a stream of 1.88 Mbit/s.


Input for the encoder consists of input frames each of 24 8-bit symbols (12 16-bit samples from the A/D converter, 6 each from left and right data (sound) sources). A frame can be represented by where and are bytes from the left and right channels from the sample of the frame.




Initially, the bytes are permuted to form new frames represented by where represent left and right samples from the frame after 2 intervening frames.


Next, these 24 message symbols are encoded using C2 (28,24,5) Reed–Solomon code which is a shortened RS code over . This is two-error-correcting, being of minimum distance 5. This adds 4 bytes of redundancy, forming a new frame: . The resulting 28-symbol codeword is passed through a (28.4) cross interleaver leading to 28 interleaved symbols. These are then passed through C1 (32,28,5) RS code, resulting in codewords of 32 coded output symbols. Further regrouping of odd numbered symbols of a codeword with even numbered symbols of the next codeword is done to break up any short bursts that may still be present after the above 4-frame delay interleaving. Thus, for every 24 input symbols there will be 32 output symbols giving . Finally one byte of control and display information is added.[5] Each of the 33 bytes is then converted to 17 bits through EFM (eight to fourteen modulation) and addition of 3 merge bits. Therefore, the frame of six samples results in 33 bytes × 17 bits (561 bits) to which are added 24 synchronization bits and 3 merging bits yielding a total of 588 bits.




Decoding: The CD player (CIRC decoder) receives the 32 output symbol data stream. This stream passes through the decoder D1 first. It is up to individual designers of CD systems to decide on decoding methods and optimize their product performance. Being of minimum distance 5 The D1, D2 decoders can each correct a combination of errors and erasures such that .[5] In most decoding solutions, D1 is designed to correct single error. And in case of more than 1 error, this decoder outputs 28 erasures. The deinterlever at the succeeding stage distributes these erasures across 28 D2 codewords. Again in most solutions, D2 is set to deal with erasures only (a simpler and less expensive solution). If more than 4 erasures were to be encountered, 24 erasures are output by D2. Thereafter, an error concealment system attempts to interpolate (from neighboring symbols) in case of uncorrectable symbols, failing which sounds corresponding to such erroneous symbols get muted.



Performance of CIRC:[7] CIRC conceals long bust errors by simple linear interpolation. 2.5 mm of track length (4000 bits) is the maximum completely correctable burst length. 7.7 mm track length (12,300 bits) is the maximum burst length that can be interpolated. Sample interpolation rate is one every 10 hours at Bit Error Rate (BER) and 1000 samples per minute at BER = Undetectable error samples (clicks): less than one every 750 hours at BER = and negligible at BER = .



See also
References
- Coding Bounds for Multiple Phased-Burst Correction and Single Burst Correction Codes
- The Theory of Information and Coding: Student Edition, by R. J. McEliece
- Ling, San, and Chaoping Xing. Coding Theory: A First Course. Cambridge, UK: Cambridge UP, 2004. Print
- Moon, Todd K. Error Correction Coding: Mathematical Methods and Algorithms. Hoboken, NJ: Wiley-Interscience, 2005. Print
- Lin, Shu, and Daniel J. Costello. Error Control Coding: Fundamentals and Applications. Upper Saddle River, NJ: Pearson-Prentice Hall, 2004. Print
- http://quest.arc.nasa.gov/saturn/qa/cassini/Error_correction.txt Archived 2012-06-27 at the Wayback Machine
- Algebraic Error Control Codes (Autumn 2012) – Handouts from Stanford University
- McEliece, Robert J. The Theory of Information and Coding: A Mathematical Framework for Communication. Reading, MA: Addison-Wesley Pub., Advanced Book Program, 1977. Print