Automatic parallelization tool
For several years parallel hardware was only available for distributed computing but recently it is becoming available for the low end computers as well. Hence it has become inevitable for software programmers to start writing parallel applications. It is quite natural for programmers to think sequentially and hence they are less acquainted with writing multi-threaded or parallel processing applications. Parallel programming requires handling various issues such as synchronization and deadlock avoidance. Programmers require added expertise for writing such applications apart from their expertise in the application domain. Hence programmers prefer to write sequential code and most of the popular programming languages support it. This allows them to concentrate more on the application. Therefore, there is a need to convert such sequential applications to parallel applications with the help of automated tools. The need is also non-trivial because large amount of legacy code written over the past few decades needs to be reused and parallelized.
Need for automatic parallelization
Past techniques provided solutions for languages like FORTRAN and C; however, these are not enough. These techniques dealt with parallelization sections with specific system in mind like loop or particular section of code. Identifying opportunities for parallelization is a critical step while generating multithreaded application. This need to parallelize applications is partially addressed by tools that analyze code to exploit parallelism. These tools use either compile time techniques or run-time techniques. These techniques are built-in in some parallelizing compilers but user needs to identify parallelize code and mark the code with special language constructs. The compiler identifies these language constructs and analyzes the marked code for parallelization. Some tools parallelize only special form of code like loops. Hence a fully automatic tool for converting sequential code to parallel code is required.[1]
General procedure of parallelization
1. The process starts with identifying code sections that the programmer feels have parallelism possibilities. Often this task is difficult since the programmer who wants to parallelize the code has not originally written the code under consideration. Another possibility is that the programmer is new to the application domain. Thus, though this first stage in the parallelization process and seems easy at first it may not be so.
2. The next stage is to shortlist code sections out of the identified ones that are actually parallelization. This stage is again most important and difficult since it involves lot of analysis. Generally for codes in C/C++ where pointers are involved are difficult to analyze. Many special techniques such as pointer alias analysis, functions side effects analysis are required to conclude whether a section of code is dependent on any other code. If the dependencies in the identified code sections are more the possibilities of parallelization decreases.
3. Sometimes the dependencies are removed by changing the code and this is the next stage in parallelization. Code is transformed such that the functionality and hence the output is not changed but the dependency, if any, on other code section or other instruction is removed.
4. The last stage in parallelization is generating the parallel code. This code is always functionally similar to the original sequential code but has additional constructs or code sections which when executed create multiple threads or processes.
Automatic parallelization technique
See also main article automatic parallelization.
Scan
This is the first stage where the scanner will read the input source files to identify all static and extern usages. Each line in the file will be checked against pre-defined patterns to segregate into tokens. These tokens will be stored in a file which will be used later by the grammar engine. The grammar engine will check patterns of tokens that match with pre-defined rules to identify variables, loops, controls statements, functions etc. in the code.....
Analyze
The analyzer is used to identify sections of code that can be executed concurrently. The analyzer uses the static data information provided by the scanner-parser. The analyzer will first find out all the functions that are totally independent of each other and mark them as individual tasks. Then analyzer finds which tasks are having dependencies.
Schedule
The scheduler will lists all the tasks and their dependencies on each other in terms of execution and start times. The scheduler will produce optimal schedule in terms of number of processors to be used or the total time of execution for the application.
Code Generation
The scheduler will generate list of all the tasks and the details of the cores on which they will execute along with the time that they will execute for. The code Generator will insert special constructs in the code that will be read during execution by the scheduler. These constructs will instruct the scheduler on which core a particular task will execute along with the start and end times......
Parallelization Tools
There are a number of Automatic Parallelization tools for Fortran, C, C++, and several other languages.
YUCCA
YUCCA is a Sequential to Parallel automatic code conversion tool developed by KPIT Technologies Ltd. Pune. It takes input as C source code which may have multiple source and header files. It gives output as transformed multi-threaded parallel code using pthreads functions and OpenMP constructs. The YUCCA tool does task and loop level parallelization.
Par4All
Par4All is an automatic parallelizing and optimizing compiler (workbench) for C and Fortran sequential programs. The purpose of this source-to-source compiler is to adapt existing applications to various hardware targets such as multicore systems, high performance computers and GPUs. It creates a new source code and thus allows the original source code of the application to remain unchanged.
Cetus
Cetus is a compiler infrastructure for the source-to-source transformation of software programs. This project is developed by Purdue University. Cetus is written in Java. It provides basic infrastructure for writing automatic parallelization tools or compilers. The basic parallelizing techniques Cetus currently implements are privatization, reduction variables recognition and induction variable substitution.
A new graphic user interface (GUI) was added in Feb 2013. Speedup calculations and graph display were added in May 2013. A Cetus remote server in a client-server model was added in May 2013 and users can optionally transform C Code through the server. This is especially useful when users run Cetus on a non-Linux platform. An experimental Hubzero version of Cetus was also implemented in May 2013 and users can also run Cetus through a web browser.
PLUTO
PLUTO is an automatic parallelization tool based on the polyhedral model. The polyhedral model for compiler optimization is a representation for programs that makes it convenient to perform high-level transformations such as loop nest optimizations and loop parallelization. Pluto transforms C programs from source to source for coarse-grained parallelism and data locality simultaneously. The core transformation framework mainly works by finding affine transformations for efficient tiling and fusion, but not limited to those. OpenMP parallel code for multicores can be automatically generated from sequential C program sections.
Polaris compiler
The Polaris compiler takes a Fortran77 program as input, transforms this program so that it runs efficiently on a parallel computer, and outputs this program version in one of several possible parallel FORTRAN dialects. Polaris performs its transformations in several "compilation passes". In addition to many commonly known passes, Polaris includes advanced capabilities performing the following tasks: Array privatization, Data dependence testing, Induction variable recognition, Inter procedural analysis, and symbolic program analysis.
Intel C++ Compiler
The auto-parallelization feature of the Intel C++ Compiler automatically translates serial portions of the input program into semantically equivalent multi-threaded code. Automatic parallelization determines the loops that are good work sharing candidates, performs the data-flow analysis to verify correct parallel execution, and partitions the data for threaded code generation as is needed in programming with OpenMP directives. The OpenMP and Auto-parallelization applications provide the performance gains from shared memory on multiprocessor systems.
Intel Advisor
The Intel Advisor 2017 is a vectorization optimization and thread prototyping tool. It integrates several steps into its workflow to search for parallel sites, enable users to mark loops for vectorization and threading, check loop-carried dependencies and memory access patterns for marked loops, and insert pragmas for vectorization and threading.
AutoPar
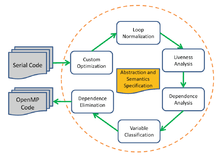
AutoPar is a tool which can automatically insert OpenMP pragmas into input serial C/C++ codes. For input programs with existing OpenMP directives, the tool will double check the correctness when the right option is turned on. Compared to conventional tools, AutoPar can incorporate user knowledge (semantics) to discover more parallelization opportunities.
iPat/OMP
This tool provides users with the assistance needed for OpenMP parallelization of a sequential program. This tool is implemented as a set of functions on the Emacs editor. All the activities related to program parallelization, such as selecting a target portion of the program, invoking an assistance command, and modifying the program based on the assistance information shown by the tool, can be handled in the source program editor environment.[2]
Vienna Fortran compiler(VFC)
It is a new source-to-source parallelization system for HPF+ (optimized version of HPF), which addresses the requirements of irregular applications.
SUIF compiler
SUIF (Stanford University Intermediate Format) is a free infrastructure designed to support collaborative research in optimizing and parallelizing compilers. SUIF is a fully functional compiler that takes both Fortran and C as input languages. The parallelized code is output as an SPMD (Single Program Multiple Data) parallel C version of the program that can be compiled by native C compilers on a variety of architectures.[3]
Omni OpenMP Compiler
It translates C and Fortran programs with OpenMP pragmas into C code suitable for compiling with a native compiler linked with the Omni OpenMP runtime library. It does for loop parallelization.
Timing-Architects Optimizer
It uses a simulation based approach to improve task allocation and task parallelization to multiple cores. By use of a simulation based performance and real-time analysis, different task allocation alternatives are benchmarked against each other. Dependencies as well as processor platform specific effects are considered. TA Optimizer is used in embedded system engineering.
TRACO
It uses the Iteration Space Slicing and Free Schedule Framework. The core is based on the Presburger Arithmetic and the transitive closure operation. Loop dependencies are represented with relations. TRACO uses the Omega Calculator, CLOOG and ISL libraries, and the Petit dependence analyser. The compiler extracts better locality with fine- and coarse-grained parallelism for C/C++ applications. The tool is developed by the West-Pomeranian University of Technology team; (Bielecki, Palkowski, Klimek and other authors) http://traco.sourceforge.net.
SequenceL
SequenceL is a general purpose functional programming language and auto-parallelizing tool set, whose primary design objectives are performance on multi-core processor hardware, ease of programming, platform portability/optimization, and code clarity and readability. Its main advantage is that it can be used to write straightforward code that automatically takes full advantage of all the processing power available, without programmers needing to be concerned with identifying parallelisms, specifying vectorization, avoiding race conditions, and other challenges of manual directive-based programming approaches such as OpenMP.
Programs written in SequenceL can be compiled to multithreaded code that runs in parallel, with no explicit indications from a programmer of how or what to parallelize. As of 2015, versions of the SequenceL compiler generate parallel code in C++ and OpenCL, which allows it to work with most popular programming languages, including C, C++, C#, Fortran, Java, and Python. A platform-specific runtime manages the threads safely, automatically providing parallel performance according to the number of cores available.
OMP2MPI
OMP2MPI[4] Automatically generates MPI source code from OpenMP. Allowing that the program exploits non shared-memory architectures such as cluster, or Network-on-Chip based(NoC-based) Multiprocessors-System-onChip (MPSoC). OMP2MPI gives a solution that allow further optimization by an expert that want to achieve better results.
OMP2HMPP
OMP2HMPP,[5] a tool that, automatically translates a high-level C source code(OpenMP) code into HMPP. The generated version rarely will differs from a hand-coded HMPP version, and will provide an important speedup, near 113%, that could be later improved by hand-coded CUDA.
emmtrix Parallel Studio
emmtrix Parallel Studio is a source-to-source parallelization tool combined with an interactive GUI developed by emmtrix Technologies GmbH. It takes C, MATLAB, Simulink, Scilab or Xcos source code as input and generates parallel C code as output. It relies on static schedule and a message passing API for the parallel program. The whole parallelization process is controlled and visualized in an interactive GUI enabling parallelization decisions by the end user. It targets embedded multicore architectures combined with GPU and FPGA accelerators.
CLAW Compiler
The CLAW Compiler translates Fortran programs with claw pragmas into Fortran code suitable for a specific supercomputer target augmented with OpenMP or OpenACC pragmas.
References
- “Increasing Parallelism on Multicore Processors Using Induced Parallelism”, by Vinay G. Vaidya, PushpRaj Agrawal, Aditi Athavale, Anish Sane, Sudhakar Sah and Priti Ranadive
- “Development and Implementation of an Interactive Parallelization Assistance Tool for OpenMP: iPat/OMP” by Makoto Ishihara,Hiroki Honda and Mitsuhisa Sato
- "An Overview of the SUIF Compiler for Scalable Parallel Machines”,In Proceedings of the Seventh SIAM Conference on Parallel Processing for Scientific Computing,1993 by Saman P. Amarasinghe,Jennifer M. Anderson,Monica S. Lam,Chauwen Tseng
- Albert Saa-Garriga, David Castells-Rufas, and Jordi Carrabina. 2015. OMP2MPI: Automatic MPI code generation from OpenMP programs. In High Performance Energy Efficient Embedded Systems. ACM.
- Albert Saa-Garriga, David Castells-Rufas, and Jordi Carrabina. 2014. OMP2HMPP: HMPP Source Code Generation from Programs with Pragma Extensions. In High Performance Energy Efficient Embedded Systems. ACM.