Aggregate (data warehouse)
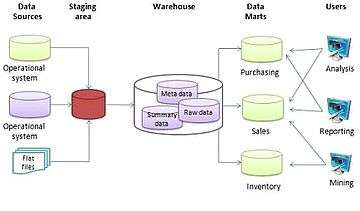
Aggregates are used in dimensional models of the data warehouse to produce positive effects on the time it takes to query large sets of data. At the simplest form an aggregate is a simple summary table that can be derived by performing a Group by SQL query. A more common use of aggregates is to take a dimension and change the granularity of this dimension. When changing the granularity of the dimension the fact table has to be partially summarized to fit the new grain of the new dimension, thus creating new dimensional and fact tables, fitting this new level of grain. Aggregates are sometimes referred to as pre-calculated summary data, since aggregations are usually precomputed, partially summarized data, that are stored in new aggregated tables. When facts are aggregated, it is either done by eliminating dimensionality or by associating the facts with a rolled up dimension. Rolled up dimensions should be shrunken versions of the dimensions associated with the granular base facts. This way, the aggregated dimension tables should conform to the base dimension tables.[1] So the reason why aggregates can make such a dramatic increase in the performance of the data warehouse is the reduction of the number of rows to be accessed when responding to a query.[2]
Ralph Kimball, who is widely regarded as one of the original architects of data warehousing, says:[3]
The single most dramatic way to affect performance in a large data warehouse is to provide a proper set of aggregate (summary) records that coexist with the primary base records. Aggregates can have a very significant effect on performance, in some cases speeding queries by a factor of one hundred or even one thousand. No other means exist to harvest such spectacular gains.
Having aggregates and atomic data increases the complexity of the dimensional model. This complexity should be transparent to the users of the data warehouse, thus when a request is made, the data warehouse should return data from the table with the correct grain. So when requests to the data warehouse are made, aggregate navigator functionality should be implemented, to help determine the correct table with the correct grain. The number of possible aggregations is determined by every possible combination of dimension granularities. Since it would produce a lot of overhead to build all possible aggregations, it is a good idea to choose a subset of tables on which to make aggregations. The best way to choose this subset and decide which aggregations to build is to monitor queries and design aggregations to match query patterns.[4]
Aggregate navigator
Having aggregate data in the dimensional model makes the environment more complex. To make this extra complexity transparent to the user, functionality known as aggregate navigation is used to query the dimensional and fact tables with the correct grain level. The aggregate navigation essentially examines the query to see if it can be answered using a smaller, aggregate table.[5]
Implementations of aggregate navigators can be found in a range of technologies:
- OLAP engines
- Materialized views
- Relational OLAP (ROLAP) services
- BI application servers or query tools
It is generally recommended to use either of the first three technologies, since the benefits in the latter case is restricted to a single front end BI tool[6]
Problems/challenges
- Since dimensional models only gain from aggregates on large data sets, at what size of the data sets should one start considering using aggregates?
- Similarly, is a data warehouse always handling data sets that are too large for direct queries, or is it sometimes a good idea to omit the aggregate tables when starting a new data warehouse project? Thus, will omitting aggregates in the first iteration of building a new data warehouse make the structure of the dimensional model simpler?
References
- Ralph Kimball; Margy Ross (2002). The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling (Second ed.). Wiley Computer Publishing. p. 356. ISBN 0-471-20024-7.
- Christopher Adamson, Mastering Data Warehouse Aggregates: Solutions for Star Schema Performance, Wiley Publishing, Inc., 2006 ISBN 978-0-471-77709-0, Page 23
- "Aggregate Navigation With (Almost) No Metadata". 1995-08-15. Archived from the original on 2010-12-11. Retrieved 2010-11-22.
- Kimball & Data Warehouse Toolkit, p. 355.
- Kimball & Data Warehouse Toolkit, p. 137.
- Kimball & Data Warehouse Toolkit, p. 354.