ADALINE
ADALINE (Adaptive Linear Neuron or later Adaptive Linear Element) is an early single-layer artificial neural network and the name of the physical device that implemented this network.[1][2][3][4][5] The network uses memistors. It was developed by Professor Bernard Widrow and his graduate student Ted Hoff at Stanford University in 1960. It is based on the McCulloch–Pitts neuron. It consists of a weight, a bias and a summation function.
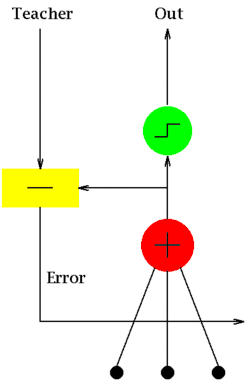
The difference between Adaline and the standard (McCulloch–Pitts) perceptron is that in the learning phase, the weights are adjusted according to the weighted sum of the inputs (the net). In the standard perceptron, the net is passed to the activation (transfer) function and the function's output is used for adjusting the weights.
A multilayer network of ADALINE units is known as a MADALINE.
Definition
Adaline is a single layer neural network with multiple nodes where each node accepts multiple inputs and generates one output. Given the following variables as:
- is the input vector
- is the weight vector
- is the number of inputs
- some constant
- is the output of the model





then we find that the output is . If we further assume that



then the output further reduces to:

Learning algorithm
Let us assume:
- is the learning rate (some positive constant)
- is the output of the model
- is the target (desired) output


then the weights are updated as follows . The ADALINE converges to the least squares error which is .[6] This update rule is in fact the stochastic gradient descent update for linear regression.[7]


MADALINE
MADALINE (Many ADALINE[8]) is a three-layer (input, hidden, output), fully connected, feed-forward artificial neural network architecture for classification that uses ADALINE units in its hidden and output layers, i.e. its activation function is the sign function.[9] The three-layer network uses memistors. Three different training algorithms for MADALINE networks, which cannot be learned using backpropagation because the sign function is not differentiable, have been suggested, called Rule I, Rule II and Rule III.
MADALINE Rule 1 (MRI) - The first of these dates back to 1962 and cannot adapt the weights of the hidden-output connection.[10]
MADALINE Rule 2 (MRII) - The second training algorithm improved on Rule I and was described in 1988.[8] The Rule II training algorithm is based on a principle called "minimal disturbance". It proceeds by looping over training examples, then for each example, it:
- finds the hidden layer unit (ADALINE classifier) with the lowest confidence in its prediction,
- tentatively flips the sign of the unit,
- accepts or rejects the change based on whether the network's error is reduced,
- stops when the error is zero.
MADALINE Rule 3 - The third "Rule" applied to a modified network with sigmoid activations instead of signum; it was later found to be equivalent to backpropagation.[10]
Additionally, when flipping single units' signs does not drive the error to zero for a particular example, the training algorithm starts flipping pairs of units' signs, then triples of units, etc.[8]
See also
References
- Anderson, James A.; Rosenfeld, Edward (2000). Talking Nets: An Oral History of Neural Networks. ISBN 9780262511117.
- Youtube: widrowlms: Science in Action
- 1960: An adaptive "ADALINE" neuron using chemical "memistors"
- Youtube: widrowlms: The LMS algorithm and ADALINE. Part I - The LMS algorithm
- Youtube: widrowlms: The LMS algorithm and ADALINE. Part II - ADALINE and memistor ADALINE
- "Adaline (Adaptive Linear)" (PDF). CS 4793: Introduction to Artificial Neural Networks. Department of Computer Science, University of Texas at San Antonio.
- Avi Pfeffer. "CS181 Lecture 5 — Perceptrons" (PDF). Harvard University.
- Rodney Winter; Bernard Widrow (1988). MADALINE RULE II: A training algorithm for neural networks (PDF). IEEE International Conference on Neural Networks. pp. 401–408. doi:10.1109/ICNN.1988.23872.
- Youtube: widrowlms: Science in Action (Madaline is mentioned at the start and at 8:46)
- Widrow, Bernard; Lehr, Michael A. (1990). "30 years of adaptive neural networks: perceptron, madaline, and backpropagation". Proceedings of the IEEE. 78 (9): 1415–1442. doi:10.1109/5.58323.
External links
- "Delta Learning Rule: ADALINE". Artificial Neural Networks. Universidad Politécnica de Madrid. Archived from the original on 2002-06-15.
- "Memristor-Based Multilayer Neural Networks With Online Gradient Descent Training". Implementation of the ADALINE algorithm with memristors in analog computing.