3-Base Periodicity Property
The three-base periodicity property in the field of Genomics is a property that is characteristic of protein-coding DNA sequences. The existence of this property can be shown by performing Fourier analysis on signals derived from segments of DNA sequences. Because of its predictive power, it has been used as a preliminary indicator in gene prediction.
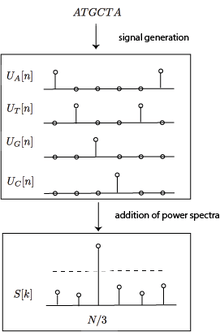
DNA sequences are inherently signals as they are functions of an independent variable, position on the sequence.[1] Thus, signal processing methods can be applied to them after the symbolic string is properly mapped to one (or more) numerical sequences. The reason for this periodicity is due to the biased distribution towards codon triplets, which is a consequence of genetic code degeneracy; while non-coding segments are uniformly randomly distributed and produce no significant signal in the frequency space.
History
This property has been dissected, tested and derived in a chronology of papers from different universities. The initial discovery was made in 1980 by Trifonov and Sussman who observed periodicity in DNA sequences by applying the autocorrelation function to chromatin DNA.[2] Silverman and Linsker defined the Fourier transform of a sequence of bases, described how to "fourier analyze" it and proposed sample applications of this technique.[3] Tsonis, Elsner and Tsonis did Fourier analysis of coding, non-coding and random sequences and proposed a reason for the 3-periodicity property found in coding sequences.[4] Dodin proposed a method for analyzing the periodicity of DNA sequences based on the correlation function of the symbolic sequence.[5] Tiwari, Ramachandran, Bhattacharya and Ramaswamy examined the signal-to-noise ratio of the period-3 peak within a sliding window over a sequence to identify likely coding regions.[6]
Coding vs. Non-Coding DNA
DNA stores the information required to assemble, maintain and reproduce every living organism. A protein is a large molecule ("macromolecule") made up of smaller subunits, amino acids. DNA sequences are made up of codons, three-long nucleotide stretches, that correspond to specific amino acids. DNA creates RNA which then helps synthesize proteins. Thus, coding DNA is defined as the sections of the genome that are actually transcribed into amino acids in proteins. Noncoding DNA is sections of a DNA sequence that don't necessarily code for proteins. Identification of coding regions is important, as this information can be used in gene identification and then more generally full-genome annotation.
Formal Statement of the Property
The 3-periodicity property states that the spectral energy

derived from the DFT's of the four binary signals representing a DNA protein coding region of length , exhibits a peak at discrete frequency .[7]


Technical Details
DNA Sequences as Numerical Sequences
Formally, a DNA sequence is an ordered list of symbols from a dictionary of nucleotides . There are multiple ways to view this as a numerical sequence, and they will all be applied to the same example:



- Binary Projection
Define a binary signal for each nucleotide, , which is 0 when the i-th position in the sequence is the nucleotide and 1 otherwise. Formally,



This creates four signals which encode the position of the four nucleotides in the sequence. For the above example, the projected signals would be
ATGCAGC, = 1000100, = 0001001, = 0100000, = 0010010




- Correlation Function
Let be a function that is 1 if and otherwise. Let . In other words, it counts the number of times that the nucleotide at a position is equal to the nucleotide t-away on the sequence. It is invariant to changing the labeling of the bases. will always be equal to the length of the sequence. For the above example, the projected signals would be





, , , , , ,







- Linear Map
For mathematical purposes, a gene sequence could be viewed as a signal by mapping each nucleotide into the range [1,4]. For the example above and map , the sequence would manifest itself as .


This process generates a single signal for the sequence, but raises questions such as which out of 24 (4!) maps should be used and what effect does this map have on our analysis. Unlike the other two mapping methods, this one is not invariant to changing the labeling of the bases but having the same structure (i.e. AACA -> TTGT), which could be detrimental for some applications.
Spectral Analysis of DNA Sequences
Once the DNA sequence has been converted into a numerical sequence, spectral analysis can be performed on that sequence. Recall the DFT is defined by the analysis equation

and produces a N-long complex signal that represents the spectrum of the signal. The index of the frequency response corresponds to an angular frequency of . For the 3-base periodicity property, the frequency content at should be analyzed as it corresponds to a period of 3.




Recall that the power spectra of a sequence is equal to the magnitude of the frequency vector squared,

Tiwari applied the DFT to analysis of DNA sequences using the binary projection operator.[6] They calculated the spectra of the four projected nucleotide sequences using the DFT. Call them . Then, the power spectra of all the signals were combined,


Then, they calculated the Signal-to-Noise ratio of this signal and performed a threshold test on that value to determine whether or not that stretch of DNA is coding.
Anti-Notch Filter
Instead of computing a Discrete Fourier Transform on different segments of the signal, the analysis can be performed in the time-domain through the use of an anti-notch filter at frequency , which is much faster and performs a similar operation. An anti-notch filter applied to the signals essentially approximates the magnitude of the DFT at , and a similar method is used to threshold this value to determine whether or not the window is coding or non-coding. Vaidyanathan and Yoon implemented and evaluated this method.[8] An ideal anti-notch filter at frequency has an impulse response of


and thus the frequency content of the output of an anti-notch filtered signal is if and 0 otherwise. By taking the magnitude of the time-domain signal, and invoking Parseval's Theorem, we get the magnitude of the frequency response. By the above logic, this is just which is the quantity of interest.


Spectrograms
Spectrograms are a good way to view how the frequency content of a signal changes over time. The most common way to compute a spectrogram is to compute a Fourier transform over different segments of the signals, convert the frequency magnitude plot into an image, and concatenate those images. This is a useful way to visually identify coding and non-coding regions of DNA and to inspect other patterns that might exist.[9]
As a Feature in Gene Identification
Identifying genes in a DNA sequence is harder than just finding what segments are coding and near impossible to identify by visually inspecting spectrograms. Genes are made up of both coding and non-coding regions, called introns and exons. Thus, the transition between coding and non-coding regions must be examined and analyzed properly to identify genes. Computing the "level" of 3-periodicity over different (possibly overlapping) windows of the sequence generates a plot of 3-periodicity over time.[10]
These long stretches of coding vs. non-coding can then be classified as introns or exons and the entire segment heuristically labeled as gene or non-gene.
Why Can it Discriminate Coding from Non-Coding?
Binary signals can be parsed into something called a position count function (PCF), which counts the number of one's at phase at positions that are multiples of . This is expressed mathematically for a binary signal as



For , there are three PCFs , and which each count the number of one's at positions , , respectively. It can be shown that the magnitude of the DFT at is in fact directly related to the PCF and is equal to








In other words, the spectral power at in the DFT depends only on the difference between the PCFs at different phases. This relation here is the fundamental to the explanation for why this method can identify coding regions. This is because the spectral power at will be determined by how the codons that make up the sequence are sampled.
If the codons are sampled uniformly at random, as they would be in a noncoding segment of DNA, there is a high chance that the PCFs would not differ by a significant amount and the power at that frequency will be low.
However, in a protein-coding sequence, the DNA sequence is made up of a string of codons which correspond to amino acids. Because the genetic code is degenerate (more than one codon map to a single amino acid) and samples from the amino acids rather than the codons, the codons are not sampled uniformly thus leading to differences in the PCFs.
There is also empirical evidence for why this method works. In other words, over multiple studies this method has been able to discriminate coding vs. non-coding DNA segments. These are discussed in the next section.
Experiments
This method has been applied to sequence data from a number of organisms, details of which can be found in the references section. A few will be summarized here.
Tiwari, who wrote the paper to first apply DFT to analyzing periodicity of DNA sequences, applied this method to S.cerevisiae and H.influenzuae. For S.cerevisiae, they were able to locate 413 out of 483 probable genes (ORFs). For H.influenzuae, they were able to locate 167 out of 194 identified genes. In both studies, they had a zero false-positive rate.
Datta and Asif analyzed the algorithm's ability to identify coding regions of different lengths in chromosome III of C. elegans. Longer coding sequences are detected with higher probability. This seems to be a consequence of the Uncertainty principle (shorter-time signals spread out in frequency content) and the fact that fewer codons are provided in shorter sequences.
Pros and Cons of the Property
Pros
- Requires no training data
The method can be run on any DNA sequence, where as other methods such as BLAST, FASTA and Smith-Waterman require empirical data.
- Independent of variations in base compositions
This is because the total spectral power is

and no one base contributes more than another.
- Low false-positive rate
- Robust to sequencing errors resulting in frameshifts
This is due to the property that shifting a sequence does not change the magnitude of its Discrete Fourier Transform.


Cons
- Three-base periodicity found to be lacking in some genes
- Outperformed by modern empirical and specialized gene prediction methods
References
- Oppenheim, Alan; Willsky, Alan; Nawab, S. (1996). Signals and Systems (2nd ed.).
- Trifonov, Edward N.; Sussman, Joel L. (July 1980). "The pitch of chromatin DNA is reflected in its nucleotide sequence". Proceedings of the National Academy of Sciences of the United States of America. 77 (7): 3816–20. doi:10.1073/pnas.77.7.3816. PMC 349717. PMID 6933438.
- Silverman B. D.; Linsker R. (25 September 1985). "A Measure of DNA Periodicity". Journal of Theoretical Biology, 1986.
- Tsonis, Anastasios A.; Elsner, James B.; Tsonis, Panagiotis A. (25 March 1991). "Periodicity in DNA Coding Sequences: Implications in Gene Evolution". Journal of Theoretical Biology, 1991.
- Dodin, Guy; Vandergheynst, Pierre; Levoir, Patrick; Cordier, Christine; Marcourt, Laurence. (19 June 2000). "Fourier and Wavelet Transform Analysis, a Tool for Visualizing Regular Patterns in DNA Sequences". Journal of Theoretical Biology, 2000.
- Tiwari, Shrish; Ramachandran, S.; Bhattacharya, Alok; Bhattacharya, Sudha; Ramaswamy, Ramakrishna. (31 December 1996). "Prediction of probable genes by Fourier analysis of genomic sequences". CABIOS, 1996.
- Chechetkin, V.R.; Turygin, A.Yu. (1995). "Size-dependence of three-periodicity and long-range correlations in DNA sequences". Physics Letters A, 1995.
- Vaidyanathan, P. P.; Yoon, Byung-Jun. (6 November 2002). "Digital filters for gene prediction applications". Signals, Systems and Computers (IEEE), 2002.
- Anastassiou, Dimitris. (July 2001). "Genomic Signal Processing". IEEE Signal Processing, 2001.
- Yin, Changchuan. (2012). "Denoising the 3-Base Periodicity Walks of DNA Sequences in Gene Finding".
- Datta, Suprakash; Asif, Amir. (2005) "A Fast DFT Based Gene Prediction Algorithm for Identification of Protein Coding Regions".