4
0
I have a text file from a legacy source which contains corrupted characters.
At first I thought the corruption was just gobbledygook, but it appears upon closer examination that some of the corrupted text could probably be reconstructed.
In order to focus my efforts, it would be helpful to understand what the original looked like, even if I cannot reconstruct it fully.
Unfortunately, the document is from a collection which I cannot share freely, but here is a snippet. The message has been converted to UTF-8, but the conversion failed somewhere, so it is mostly illegible. Fragments of text in Czech are visible, where the accented Czech characters have been replaced with Cyrillic characters (which were probably something completely different before the conversion).
0001f80: 33d1 936e 6576 79d1 87d0 bd7a 656e d18c 3..nevy....zen..
0001f90: 6368 7e58 3833 d193 7e58 3945 d19b d0b1 ch~X83..~X9E....
0001fa0: 646f 7374 d0bd 7e58 3833 d193 6e61 7e58 dost..~X83..na~X
0001fb0: 3833 d193 7ad1 87d0 bd7a 656e 20d0 bd7e 83..z....zen ..~
0001fc0: 5838 33d1 936e 6562 6f7e 5838 33d1 9370 X83..nebo~X83..p
0001fd0: d187 656b 6cd0 b164 6b75 7e58 3833 d193 ..ekl..dku~X83..
0001fe0: 7465 6c65 666f 6e6e d0bd 7e58 3833 d193 telefonn..~X83..
0001ff0: 7374 616e 6963 657e 5838 33d1 9376 207e stanice~X83..v ~
0002000: 5838 33d1 9372 6567 696f 6e75 7e58 3833 X83..regionu~X83
0002010: d193 5072 6168 617e 5838 33d1 9365 7669 ..Praha~X83..evi
0002020: 6475 6a65 7e58 3833 d193 5350 547e 5838 duje~X83..SPT~X8
0002030: 33d1 9354 656c 6563 6f6d 2e7e 5838 33d1 3..Telecom.~X83.
0002040: 934e 617e 5838 33d1 9364 6e65 7e58 2039 .Na~X83..dne~X 9
0002050: 41d1 996e d0bd 7e58 3833 d193 7469 736b A..n..~X83..tisk
0002060: 6f76 d0b9 7e58 3833 d193 6b6f 6e66 6572 ov..~X83..konfer
0002070: 656e 6369 7e58 3833 d193 746f 7e58 3833 enci~X83..to~X83
0002080: d193 d187 656b 6c7e 5838 33d1 93d1 8765 ....ekl~X83....e
I'm vaguely speculating that the encoding might be related to ISO-2022, but I am not familiar enough with it to really be sure. It has obviously gone through at least one broken filter, possibly multiple, before ending up like this.
Looking at the first line, d1 93 is ѓ and was probably a single 8-bit byte before the conversion. A general pattern seems to be ~XFF followed by a signal byte, where the FF is some hex sequence in plain ASCII (mostly 83 here, but generally from 80 through 9E in the entire sample), and the final byte is now an UTF-8 character. (It could have been multiple bytes in the input as well, of course.) This sequence appears between words (always ~X83ѓ?), and sometimes within words.
Here is the same fragment as just text, as it renders under UTF-8 now.
3ѓnevyчнzenьch~X83ѓ~X9Eћбdostн~X83ѓna~X83ѓzчнzen н~X83ѓnebo
~X83ѓpчeklбdku~X83ѓtelefonnн~X83ѓstanice~X83ѓv ~X83ѓregionu
~X83ѓPraha~X83ѓeviduje~X83ѓSPT~X83ѓTelecom.~X83ѓNa~X83ѓdne~
X 9Aљnн~X83ѓtiskovй~X83ѓkonferenci~X83ѓto~X83ѓчekl~X83ѓчe
I have other samples in other languages so getting the Czech sorted out is not really my focus. Here is the beginning of one in, I don't know, probably some Far Eastern language?
X1B%0 ~XD0^?~X98^?~XD0^?^?^?~X82^?~XD0^?~XB5^?^?~X80^?^?~X84^?~XD0^?~XB0^?~XD0
^?^?^?~X81^? ~XD0^?~XB1^?^?~X83^?~XD0^?^?~XD0^?~XB2^?~XD0^?~XB0^?~XD0^?^?^?~X8C
^?~XD0^?^?~XD0^?~XBE^? ~XD0^?~XB7^?~XD0^?~XB0^? ~XD0^?^?~XD0^?~XB5^?^?~X81^?~XD
0^?^?~XD0^?~XBE^?~XD0^?^?^?~X8C^?~XD0^?^?~XD0^?~XBE^? ~XD0^?^?~XD0^?~XB8^?~XD0^
?^?^?~X83^?^?~X82^? ~XD0^?~XB4^?~XD0^?~XBE^? ^?~X81^?~
(The ^?:s are literal DEL characters, ASCII 0x7F.)
The space in the place of a tilde at the beginning might be a hint as to what went wrong in the conversion, but this is wild speculation.
ESC % 0 looks like the ISO-2022 code to "designate other coding system", but what does the 0 stand for here? I'm probably too dense to understand the Wikipedia article without further examples, and everything else I could find seems very focused on some subset such as ISO-2022-JP.
Does my analysis so far make sense to you? Can you help me figure out what happened, and perhaps even offer advice on how to revert the corruption?
I have posted hex dumps of extended fragments of these two examples at http://pastebin.com/ffn7CtdG

tripleee
Posted 2014-09-05T11:32:43.777
Reputation: 2 480

2It would help in the forensic work if you could extract the above fragment using an hex editor, store it as a binary file and post it somewhere. Make the fragment as large as you can, and start it if you can from the first byte of the file. Do you know under which operating system the files were generated? – harrymc – 2014-10-09T16:43:26.310
No, I don't know what sort of system this originally ran on. – tripleee – 2014-10-10T05:54:06.500
Thanks for the feedback! Added a Pastebin link to extended examples. – tripleee – 2014-10-10T06:55:36.217
Thank you, but I really meant the entire beginnings of files as they are, and not the output is from xxd that I can't use in my hex editor. Anyway, one obvious thing I noticed from your example is that the "~X83.." part should rightly be a blank. For example, "SPT Telecom" is well-known in Czech. Any additional information you have about the origin of these files will help. – harrymc – 2014-10-10T07:40:27.987
For licensing reasons, I am uncertain whether I can post a file in its entirety. You can easily turn the fragments into binary with something like
perl -lne '@s = m/: ((\X\X ?){16})/; $s = join ("", @s); $s =~ s/ //g; print pack("H*", $s)'– tripleee – 2014-10-10T08:20:06.883I don't know about the licensing of a file that seems to contain a list of past events, but do your best to post a couple. Again, any information you can add will help. For example, if they came from Windows then the original code-page most likely was Windows-1250, but not if they came from a Mac. Their age may also help, in view of text editors that existed at that time. One theory is that some of the strange codes inbetween the words may have originally been binary formatting bytes by an old text-editor. – harrymc – 2014-10-10T09:14:28.773
This is Reuters newswire from 1996-1997. It's almost certainly from some reasonably big iron. There's an obscure comment about processing by a then-subsidiary called Factiva. It's completely out of the question that any single 8-bit character set could have been used -- the system handled Russian, Chinese, Japanese, English, French, Spanish, Italian, and a number of other languages --, though ISO-2022 can be used to encode combinations of legacy character sets and would likely have been a reasonably popular choice at the time.
– tripleee – 2014-10-10T10:17:54.557All european languages have once used 8-bit characters under the correct code-page, before Unicode. I hope these are not teleprinter files - in 1996 the Internet already existed. Your theory of ISO-2022 does not explain why for example d193 is repeated so many times, either alone or with other repeating sequences, but never with an ISO-2022 escape character. – harrymc – 2014-10-10T10:54:06.013
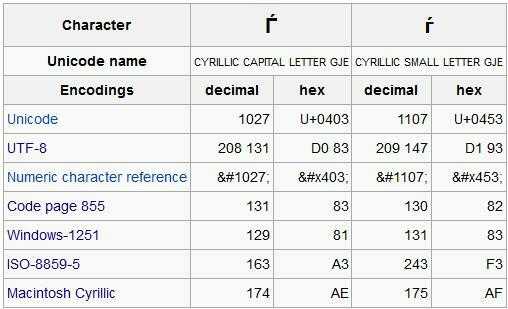
I note that d193 is the Cyrillic letter small gje whose differing code-page representations are in the link. The other sequences can also be back-mapped to 8-bit characters, assuming that the utf-8 conversion was incorrectly applied to these files, but we don't know which code-page to use. It might even be that there is no one common code-page, but several, depending on whether the files had a uniform source.
– harrymc – 2014-10-10T10:56:15.683Let us continue this discussion in chat.
– tripleee – 2014-10-10T11:03:15.957Without some example files, I'm afraid that there's not much more that I can do. – harrymc – 2014-10-10T11:06:45.413