Repeatable items are stored in a dictionary and a code is assigned as a substitute.
THIS IS AN OVER SIMPLIFICATION
aaaaaaaaaaaaaaaaaaaaaaaa 0001
bbbbbbbbbbbbbbbbbbbbbbbb 0002
alsdjl;asjdfkl;asdfjkljj 0003
instead of the whole line it just put the code in its place. The larger the dictionary the more codes it can handle. Normally, when a dictionary becomes full it starts a new one on the fly. When it starts a new one it is blank and new codes are assigned to detected patterns.
Generally, the larger the better to a point. The entire dictionary is held in memory so you need more RAM than the dictionary size.
The dictionary size depends on the compressibility of your data, the number of files, size, and overall size.
Generally, 32mb is more than enough, but if your compressing numerous multi-gig files then a much higher number can be used. Larger dictionaries often make the process slower, but the results in a smaller file.
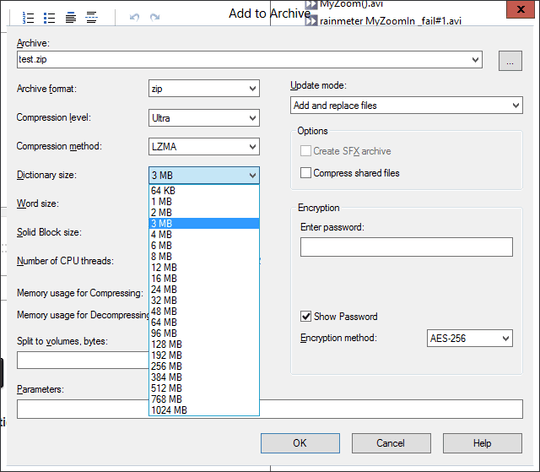



2Yes, that is since the whole file is in memory. However, this may not be possible if dealing with multi-gig files. The return on investment diminishes the higher you go. If you need that last 1% then size=file size. Note: When you have a much larger data set a 128mb+ dictionary size will increase the time it takes to compress files significantly. – cybernard – 2013-07-08T04:40:58.803