37
18
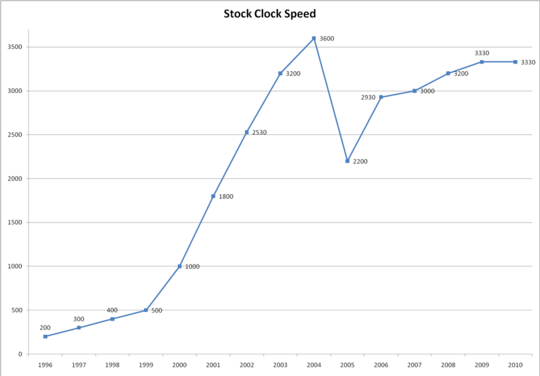
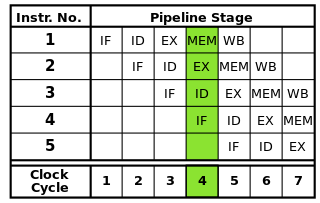
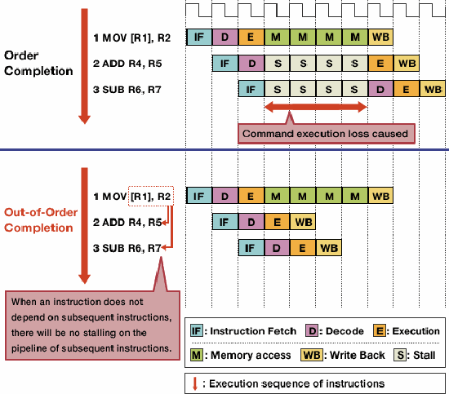
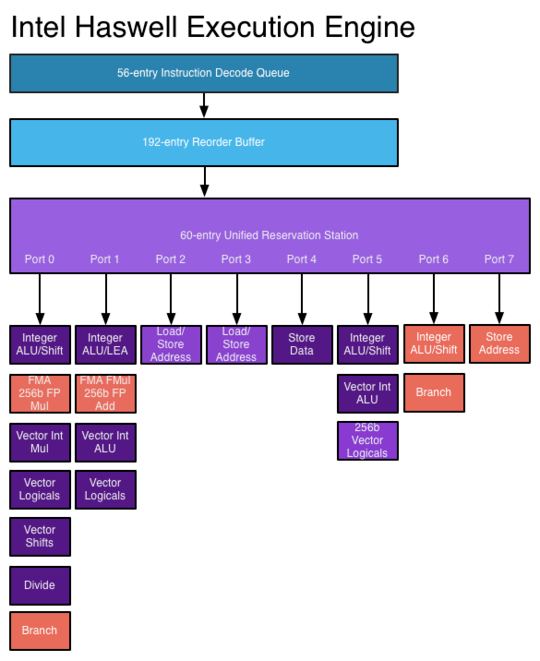
Why, for example, would a 2.66 GHz dual-core Core i5 be faster than a 2.66 GHz Core 2 Duo, which is also dual-core?
Is this because of newer instructions that can process information in fewer clock cycles? What other architectural changes are involved?
This question comes up often and the answers are usually the same. This post is meant to provide a definitive, canonical answer for this question. Feel free to edit the answers to add additional details.

agz
Posted 2013-01-29T23:56:01.007
Reputation: 6 820





{kind=link}
Also better instruction set and more registers. e.g. MMX (very old now), and x86_64 (When AMD invented x86_64 they added some compatibility breaking improvements, when in 64 bit mode. They realised that comparability would be broken anyway). – ctrl-alt-delor – 2015-07-21T20:34:49.123
For real big improvements of x86 architecture, a new instruction set is needed, but if that was done then it would not be an x86 any more. It would be a PowerPC, mips, Alpha, … or ARM. – ctrl-alt-delor – 2015-07-21T20:37:01.173
Related: Instruction per Cycle vs Increased Cycle Count
– Ƭᴇcʜιᴇ007 – 2013-01-30T01:41:02.170Wow both breakthroughs and david's are great answers...I dont know which to pick as correct :P – agz – 2013-01-30T02:42:43.563