Technically, compressed files do not compress further, something about an entropy limit or such, I forget the details, but the most you'd ever get is less than 2% that I've seen.
Most good compressors check the compression and simply store uncompressible files since compressing then would add overhead and increase the size.
Of course, there's the work & time of looking at the file in the first place.
As discussed in other answers, performing multiple passes over your fileset is probably going to be the best solution and is easily scriptable.
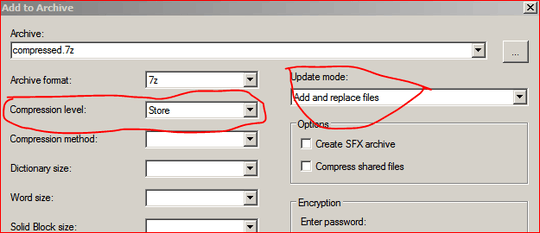
Create the 7z archive and add everything BUT the compressed files in one pass, then append the pre-compressed files as non-compressed data. (I'd do it this way since the compressible stuff would then be at the beginning of the archive and the non-compressible all at the end. It would stream off drive faster since it's contiguous)
(used 'compress...' too much!)





@ssokolow: It's been 4 years and I guess I never answered your question, but there can be other reasons such as minimizing damage from corruption and also making it easier to recover data in a disaster. – user541686 – 2015-12-17T11:52:52.930
Connected question: http://unix.stackexchange.com/questions/241898/zip-several-soundfile-formats-without-deflate
– bohdan_trotsenko – 2016-01-31T22:54:55.100Is there a specific reason (saving every little bit of processing time possible, reading them without having to bundle the 7z binary or re-implement LZMA, etc.) that you want to do this? Generally speaking, most compression tools I've run into tend to be smart enough to automatically store things uncompressed if they find a file responds poorly to an attempt to compress it further. – ssokolow – 2011-09-19T02:38:22.323