The problem is, it depends on the task.
The notion behind hyperthreading is basically that all modern CPU's have more than one execution issue. Usually closer to a dozen or so now. Divided between Integer, floating point, SSE/MMX/Streaming (whatever it is called today).
Additionally, each unit has different speeds. I.e. It might take an integer math unit 3 cycle to process something, but a 64 bit floating point division might take 7 cycles. (These are mythical numbers not based on anything).
Out of order execution helps alot in keeping the various units as full as possible.
However any single task will not use every single execution unit every moment. Not even splitting threads can help entirely.
Thus the theory becomes by pretending there is a second CPU, another thread could run on it, using the available execution units not in use by say your Audio transcoding, which is 98% SSE/MMX stuff, and the int and float units are totally idle except for some stuff.
To me, this makes more sense in a single CPU world, there faking out a second CPU allows for threads to more easily cross that threshold with little (if any) extra coding to handle this fake second CPU.
In the 3/4/6/8 core world, having 6/8/12/16 CPU's, does it help? Dunno. As much? Depends on the tasks at hand.
So to actually answer your questions, it would depend on the tasks in your process, which execution units it is using, and in your CPU, which execution units are idle/underused and available for that second fake CPU.
Some 'classes' of computational stuff are said to benefit (vaguely generically). But there is no hard and fast rule, and for some classes, it slows things down.





Very late to this party, but still: Very nice answer, I finally understood what's the deal with this hyperthreading! Thanks! – sebhofer – 2017-09-12T15:51:23.933
Late to the party as well, but my understanding is that AMD CPUs handle hyper-threading in a different manner from Intel CPUs. I would be interested to see how this test looks when run on AMD hardware. Disclaimer: I do not work for or represent AMD, I'm just very curious. – dgnuff – 2018-12-14T00:10:08.390
Best answer :-) – Sklivvz – 2011-05-05T22:18:19.907
1What are the actual speeds of the algorithms, plotted against number of cores? I.e. what is the speed gain for the fastest algorithm in these tests? Just wondering :). – crazy2be – 2011-05-05T23:23:18.323
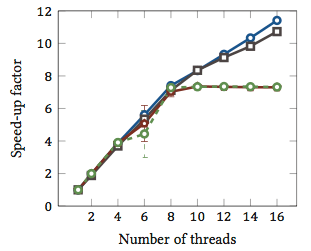
@crazy2be For the blue line (Horspool’s algorithm), the running time goes from 4.16 seconds down to 0.35 seconds with 16 threads. So the speed-up is 11.74. However, that’s with hyper-threading. When plotted against the number of cores, the speed-up of this algorithm is 7.17 on 8 cores.
– Konrad Rudolph – 2011-05-06T06:58:31.370@Konrad - That's an interesting paper, but this graph doesn't help us without the corresponding graph of run time against number of threads. Comparing algorithms by speedup factor only really works if they are of comparable speed in the first place. If the
Naivealgorithm takes twice as long to run as theShift-oralgorithm (for instance) then the hyper-threading might just be recouping some of the loss from using a less efficient algorithm. – Mark Booth – 2011-05-06T10:06:02.963@Mark I’m showcasing relative speed-up. The actual speed of these algorithms is really irrelevant for comparability. In particular, the input data is big enough so that there is guaranteed to be no “recouping some of the loss from using a less efficient algorithm” for multi-threading in general. The naive algorithm cannot magically recoup loss either, there has to be some mechanism for this, and in this case it’s reduced memory load. – Konrad Rudolph – 2011-05-06T10:30:55.690
@Mark But I get what you’re saying. I should mention that for the naive and Horspool’s algorithm the memory load fills the bus so the bandwidth is completely exploited. For the bit parallel algorithms this is no longer the case. – Konrad Rudolph – 2011-05-06T10:38:45.870
5the only problem with this answer is i can only upvote it once. Its a staggeringly objective answer for a subjective question ;) – Journeyman Geek – 2011-05-06T10:43:01.373
@Konrad - I understand that, but relative speed up is just one factor. If one algorithm runs 12x as fast with 16 hyper-threads, but still takes twice as long to run on one core as another which only scales up to the number of physical cores (7x), then the latter is still the better one to use, as it gets you your results 17% faster. I know my scientists would rather have data analysis complete in an hour than in 70 minutes. *8') – Mark Booth – 2011-05-06T10:50:20.320
@Mark “then the latter is still the better one to use” – of course. But that wasn’t the question (neither here nor in my thesis). ;-) – Konrad Rudolph – 2011-05-06T11:09:23.690
@Konrad - The question was "How much speedup does a hyper-thread give?" and your (IMHO correct) answer is "This depends entirely on the task". The problem is, you then go on to justify this with only half of the data needed. It is possible that for some algorithms, hyper-threading will result in a slow down (i.e. it will be slower using 16 hyper-threads than just using 8 real threads), which is why many people turn off hyper-threading in their BIOS, as they have benchmarked and found hyper-threading to be a disadvantage for their application. – Mark Booth – 2011-05-06T12:09:53.077
@Konrad- great answer! Could you please update your post with some useful information from the comments? On the side note - I think the timesdomatter. Bringing the speed down below 1 second makes the overhead comparable. If you could use the same algorithm but with heavier load such that max speed up resulted in 10 seconds - that would be, IMO, a better fraction to look at. – Mikhail – 2011-05-06T15:27:12.1202
@Konrad, could I interest you in writing a blog post about this answer?
– Ivo Flipse – 2011-05-12T14:02:12.160Spectacular answer @KonradRudolph! And interesting read for a thesis. I second @Ivo's request for a blog post regarding this. – James Mertz – 2011-05-12T18:41:08.060
@Ivo Angry Birds for Chrome just came out! But sure, I’ll see whether I can find some free time on the weekend. ;-) – Konrad Rudolph – 2011-05-13T07:13:21.893
The link to the thesis take 'forever' to load, and Firefox eventually gives up. – tshepang – 2013-11-25T20:16:23.450
@Tshepang Yes, unfortunately the website has been dead for months because my host’s technical contact doesn’t reply to requests and I’m too busy to take care of it, I currently haven’t got a replacement space for it. – Konrad Rudolph – 2013-11-25T20:20:09.723