I've read that the transfer overhead between CPU and GPU is a big bottleneck in achieving high performance in GPU/CPU applications. Why is this so?
There are two senses to your question:
- Why is this (the transfer) the bottleneck?
- What are the physical reasons for it?
In the first sense, it's because everything else on your machine moves soooo much faster:
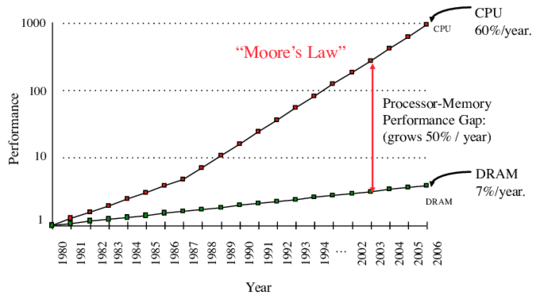
While this chart is for the CPU and memory, similar charts hold true for the GPU. The upshot of this is that if you want to get good performance, you need to make as much use out of each memory load as possible.
You can plot this with the roofline model:
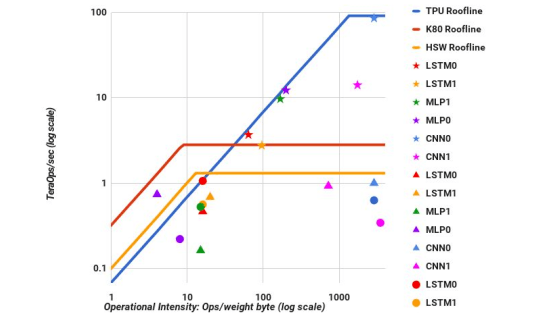
The x-axis shows how many times each byte is used when loaded from memory. The y-axis is performance in operations per second. The diagonal lines on the left-hand side are regions where the speed of memory limits computation.
In that region you can achieve greater performance by using faster memory (like the GPU's local memory or the CPU's L3, L2, or L1 caches), so that a higher diagonal lines limits you, or by increasing arithmetic intensity, so you move to the right. The flat lines on the top are limits on raw computation speed once memory is loaded. There can be a line for straight floating-point operations, SSE2, AVX, &c. In this case, the diagram shows that some deep-learning kernels reuse their data a lot and can make full use of all the special math operators in a GPU, so the only way to make them faster is to build a new device: the TPU.
Your second question: why is the bus the bottleneck? There are a number of technological reasons, but ignore those. Intel's chips are approaching 8nm between transistors. GPUs are somewhere in that ballpark. The bus, on the other hand, is easily measured in inches: that's 25 million times farther.
Assuming a 3 GHz processor, it takes about 0.3ns to do an operation.
It takes 0.25ns for a bit to move down a 3 inch bus. Since each bit sent down the bus requires at least 1 cycle to send and 1 cycle to receive, a full bit transfer takes about 0.9ns. (This ignores quite a bit of additional overhead on messages which is capture by models like LogP.) Multiply this by 1MB and you get about 1ms for a data transfer. In the same time you were doing that transfer you could have done a million other operations. So physics says the bus is a fundamental limiter of performance.




