TL;DR
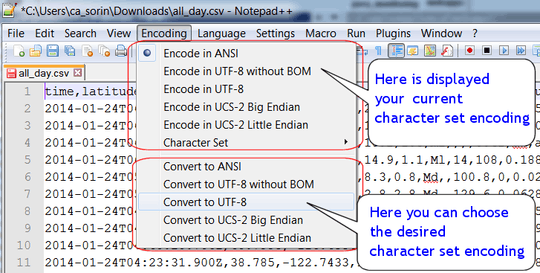
Select Convert to UTF-8 instead of Encode in UTF-8
UTF-8 is not a charset, just an encoding for Unicode. The first 128 byte values are just the same as ASCII (and most other sane character sets). However bytes with the high bit set (or ⩾ 0x80) are extended characters in ASCII while in UTF-8 they indicate a multi-byte sequence.
That's the case of 0x93 or 0x94 above. If you open the file in ANSI it'll use the current Windows codepage which is often Windows-1252 by default in the US and most Western European countries. In Windows-1252 those bytes are “smart quotes” (or curved quotes with different opening and closing forms) which you often see when using a rich text editor such as MS Word. However if you select Encoding > Encode in UTF-8 then the file will be treated as if it's been encoded in UTF-8. The Encode in... menu items are used to tell Notepad++ the real encoding if you have wrong characters being displayed1. Since 0x93 and 0x94 alone are ill-formed UTF-8 multi-byte sequences, they're left as-is in the editor
That means there's nothing strange in the file. It's just that you have chosen the wrong tool. You need to click on Convert to UTF-8 to transform the whole input byte sequence to the selected encoding
You also have a little confusion about ANSI and ASCII. ANSI is not a defined character set and can mean any codepages, although it often refers to Windows-1252. Windows-1252 is a superset of ISO-8859-1 (A.K.A Latin-1) and ISO-8859-1 is the first 256 codepoints of Unicode. ASCII is a 7-bit character set and is a subset of almost all ANSI code pages encoded in 8 bits or more. It's also sometimes referred to as ANSI, although not very correct
In general the relationship between the main character sets is as follow
ASCII < ISO-8859-1 < Windows-1252
^
Unicode
1 That unfortunate fact happens because there's no encoding information embedded in text files and we have to guess, but it's impossible to guess correctly every time and issues do happen, like the famous Bush hid the facts bug. See
Due to historical reasons Windows deals with both ANSI and Unicode text files at the same time. Hence to differentiate them it must use the byte order mark as a kind of signature to signify that it's a text file with a specific encoding. Despite the name it's not really for "byte order" marking purpose as Unix guys always claim but purely a signature. Having a signature is actually a good thing and every proper binary file formats do that. Without a BOM signature the encoding is ANSI, otherwise it's Unicode. Since Unices always use UTF-8 nowadays and don't really have to work with multitudes of text encodings, there are often no issues like on Windows





@UweKeim: quite bad, cause it is outdated. It claims that UTF-8 can take up to six bytes per codepoint, and recommends UCS-2 (!?) on server side (!?!?). – ybungalobill – 2015-06-27T20:33:13.693
I don't see what's weird in the latter image – phuclv – 2014-06-02T02:01:53.217
I meant the non-displayable characters. Any way to avoid this? – user3658425 – 2014-06-02T02:09:04.393
Did you edited the question? I think I see the images reversed – phuclv – 2014-06-02T02:10:57.250
1Yes sorry I pushed my last edit right after somebody added the images, hereby erasing the addition: if you can add them back that would be great! – user3658425 – 2014-06-02T02:12:23.143
4
Everything I learned about the topic, I learned from Joel's "The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)"
– Uwe Keim – 2014-06-02T06:40:01.737