19
6
Some PDF files produce garbage ("mojibake") when you copy text (even though they render OK). This makes it impossible to search them (whatever you search for will not match the garbage).
Does anyone have an easy workaround?
Examples:
- TEAC TV manual EU2816STF (yields above problems in Adobe Reader on both Windows and a Mac, but works fine in Preview on a Mac)
- Leadtek Winfast PVR2 manual (FTP link; also has problems in Preview on a Mac)
- Swann TV tuner card manual (FTP link; also has problems in Preview on a Mac)
- Phonedisc license agreement (from the now-defunct DTMS)
- Macquarie IFP quarterly fund review
- BAN-TACS Small Business Booklet (archived version)
- Easterfest 2004 flyer (also from the archive)
I am using Adobe Reader (latest version) for Windows - perhaps an alternative viewer might help? I'm looking for a free solution for Windows. Open-source would be even better.
Edit: The docs for the Multivalent Extract Text tool have a good summary of why things can go wrong, including: (quoted document last modified Jan 2006)
- Text may not have a Unicode mapping. PDF Type 3 fonts often do not, and TeX DVI has characters that do not have Unicode equivalents.
- The Unicode encoding may be buggy. Open Office maps some characters into the same Unicode, resulting in apparant letter dropping and doubling.
I guess the ultimate solution in these cases would be to OCR each glyph in a font to figure out what character it really is. Note that this would be easier than OCRing a noisy scanned document because the exact shape of the glyph is available (at infinite resolution since it's a "vector" image).

Hugh Allen
Posted 2010-03-13T03:05:41.377
Reputation: 8 620





Using
– Arjan – 2010-03-16T09:16:35.403clipbrd.exe(see http://www.mydigitallife.info/2008/11/06/how-to-view-windows-clipboard-contents-easily-in-windows-xp-and-vista/) you can see what's on the clipboard. What does that give you?@Arjan van Bentem: it gives me exactly the same garbage that I get when pasting into Notepad. – Hugh Allen – 2010-03-16T11:29:47.657
Any details on the format? I'm on a Mac, but I assume Windows would tell you if something is an image or text, and then for text maybe also reveals something about the encoding? – Arjan – 2010-03-16T23:28:08.243
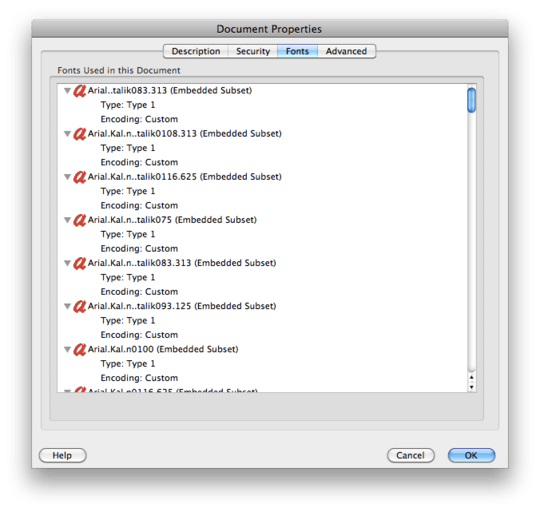
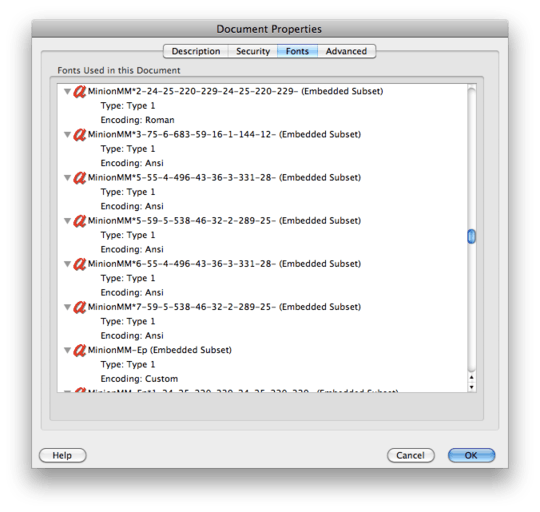
For the TV Manual example: same issue in Adobe Reader 8.1.2 on a Mac, but no problems using the Mac's Preview to copy or search text. Its document properties shows "Encoding: Custom" for the fonts (see http://img.skitch.com/20100318-827uckkb5i326eta291f3qig3u.png). Other PDF documents show things like "Encoding: Ansi" or "Roman" and have no issues in Adobe Reader on a Mac (like http://www.adobe.com/education/pdf/type_primer.pdf yields http://img.skitch.com/20100318-tbyjrny9bsg684eqhr7b3au7fb.png).
– Arjan – 2010-03-18T22:43:43.783Do you have any other examples? I don't know if this implies anything, but given your and mine examples:
file type_primer.pdfyieldstype_primer.pdf: PDF document, version 1.5, andfile product_manual_281.pdfgives meproduct_manual_281.pdf: PDF document, version 1.3. – Arjan – 2010-03-18T22:48:44.987Hmm, both your new Leadtek and Swann example give problems in Preview on a Mac as well. (And, in case it matters: both show "Encoding: Identity-H", and
PDF document, version 1.3, and both have been created using CorelDRAW.) All your examples show "Clipboard contents: rich text (RTF)" on a Mac, so that's not a lot of info either. – Arjan – 2010-03-19T07:32:50.9031
Also, http://pdftextonline.com/ cannot fetch the text from the TV Manual nor the Phonedisc document (did not try the others). But sending to Gmail and then viewing as HTML does work for the TV Manual (just like Preview has no issues with that document)...
– Arjan – 2010-03-23T11:41:32.243