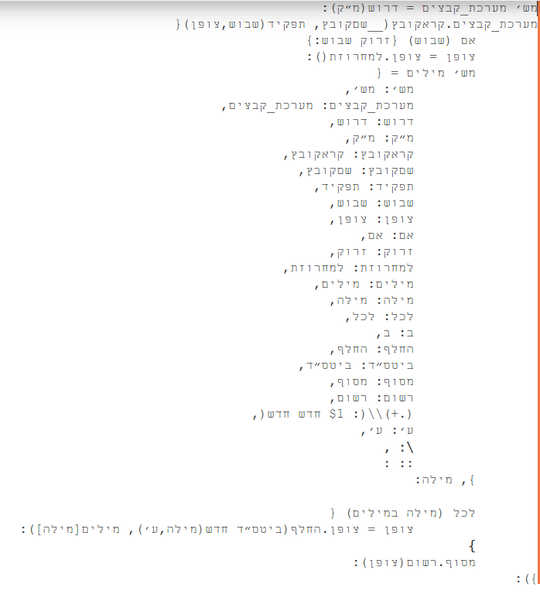
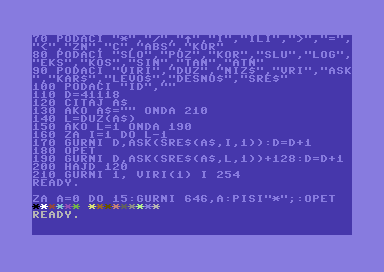
Ruby, Japanese - AkaDama
Ruby in Japanese is rubii (ルビー), which is boring, so I named it literally red gem.
In ruby, variables and methods are not restricted to ASCII, so something like
def フロートの文字化(フロート)
甲 = フロート.to_s.split(?.)
甲[0] = 整数の文字化(甲[0])
甲[1] = 甲[1].chars.map{|乙|R数字行列[乙]}.join
甲.join(?点)
end
is valid ruby. I'm using this as much as possible for obfuscation for all your bases.
I hope it's okay to use the gems for parsing ruby, it still required some ugly monkey-patching.
You can expand on the TRANS_TABLE to add translation for more methods. Everything that's not in the table is "translated" into Japanese loosely based upon its pronunciation (or more like spelling), so eat becomes えあと ("a-ah-toe").
Converts integers to a "very" practical notation.
# encoding:utf-8
require 'parser/current'
# super hack, don't try this at home!!
class Array
def freeze
self
end
end
class Hash
def freeze
self
end
end
class Parser::AST::Node
def freeze
self
end
end
require 'unparser'
class Parser::Source::Comment
def freeze
self
end
end
# translation memory
R翻訳メモリー = {}
# keyword translation
R鍵文字 = {
:BEGIN => [:K_PREEXE, :"コンパイル時に最初に登録"],
:END => [:K_POSTEXE, :"コンパイル時に最後に登録"],
:__ENCODING__ => [:K_ENCODING, :"__エンコーディング__"],
:__END__ => [:K_EEND, :"__終__"],
:__FILE__ => [:K_FILE, :"__ソースファイル名__"],
:alias => [:K_ALIAS, :"別名"],
:and => [:K_AND, :"且つ"],
:begin => [:K_BEGIN, :"開始"],
:break => [:K_BREAK, :"抜ける"],
:case => [:K_CASE, :"条件分岐"],
:class => [:K_CLASS, :"クラス"],
:def => [:K_DEF, :"定義"],
:define => [:K_DEFINE, :""],
:defined? => [:K_DEFINED, :"若し定義されたら"],
:do => [:K_DO, :"実行"],
:else => [:K_ELSE, :"違えば"],
:elsif => [:K_ELSIF, :"それとも"],
:end => [:K_END, :"此処迄"],
:ensure => [:K_ENSURE, :"必ず実行"],
:false => [:K_FALSE, :"偽"],
:for => [:K_FOR, :"変数"],
:if => [:K_IF, :"若し"],
:in => [:K_IN, :"の次の値ごとに"],
:module => [:K_MODULE, :"モジュール"],
:next => [:K_NEXT, :"次"],
:nil => [:K_NIL, :"無"],
:not => [:K_NOT, :"ノット"],
:or => [:K_OR, :"又は"],
:redo => [:K_REDO, :"遣り直す"],
:rescue => [:K_RESCUE, :"救出"],
:retry => [:K_RETRY, :"再び試みる"],
:return => [:K_RETURN, :"戻る"],
:self => [:K_SELF, :"自身"],
:super => [:K_SUPER, :"スーパー"],
:then => [:K_THEN, :"成らば"],
:true => [:K_TRUE, :"真"],
:undef => [:K_UNDEF, :"定義を取消す"],
:unless => [:K_UNLESS, :"若し違えば"],
:until => [:K_UNTIL, :"次の通りである限り"],
:when => [:K_WHEN, :"場合"],
:while => [:K_WHILE, :"次の通りで無い限り"],
:yield => [:K_YIELD, :"ブロックを呼び出す"],
}
R数字行列 = {
"0" => "零",
"1" => "壹",
"2" => "貮",
"3" => "參",
"4" => "肆",
"5" => "伍",
"6" => "陸",
"7" => "漆",
"8" => "捌",
"9" => "玖",
}
R翻訳行列 = {
# Symbols
:+ => :+,
:- => :-,
:/ => :/,
:* => :*,
:** => :**,
:! => :!,
:^ => :^,
:& => :&,
:| => :|,
:~ => :~,
:> => :>,
:< => :<,
:<< => :<<,
:% => :%,
:"!=" => :"!=",
:"=~" => :"=~",
:"~=" => :"~=",
:">=" => :">=",
:"<=" => :"<=",
:"=" => :"=",
:"==" => :"==",
:"===" => :"===",
:"<=>" => :"<=>",
:"[]" => :"[]",
:"[]=" => :"[]=",
:"!~" => :"!~",
# Errors
:ArgumentError => :引数エラー,
:EncodingError => :文字コードエラー,
:FiberError => :ファイバーエラー,
:IOError => :入出エラー,
:IndexError => :添字エラー,
:LoadError => :読込エラー,
:LocalJumpError => :エラー,
:NameError => :未定義エラー,
:NoMemoryError => :メモリー不足エラー,
:NotImplementedError => :未実装エラー,
:RangeError => :範囲エラー,
:RegexpError => :正規表現エラー,
:RuntimeError => :実行時エラー,
:ScriptError => :スクリプトエラー,
:SecurityError => :セキュリティエラー,
:StandardError => :通常エラー,
:SyntaxError => :シンタクスエラー,
:ThreadError => :スレッドエラー,
:TypeError => :タイプエラー,
:ZeroDivisionError => :零除算エラー,
# Constants
:Array => :配列,
:BasicObject => :基本オブジェクト,
:Bignum => :多倍長整数,
:Class => :クラス,
:Complex => :複素数,
:Exception => :例外,
:FalseClass => :偽クラス,
:File => :ファイル,
:Fiber => :ファイバー,
:Fixnum => :固定長整数,
:Float => :浮動小数点数,
:Hash => :ハッシュ表,
:Integer => :整数,
:IO => :入出,
:Kernel => :中核,
:Marshal => :元帥,
:Math => :数学,
:Module => :モジュール,
:NilClass => :無クラス,
:Numeric => :数値,
:Object => :オブジェクト,
:Prime => :素数,
:Proc => :プロック,
:Process => :プロセス,
:Random => :乱数,
:Range => :範囲,
:Rational => :有理数,
:Regexp => :正規表現,
:Set => :集合,
:Socket => :ソケット,
:String => :文字列,
:Symbol => :シンボル,
:Time => :時刻,
:Thread => :スレッド,
:TrueClass => :真クラス,
# Kernel
:inspect => :検査,
:p => :表示,
:print => :書く,
:puts => :言う,
:require => :取り込む,
# Object
:freeze => :凍結,
# String
:gsub => :全文字列置換,
:gsub! => :全文字列置換せよ,
}
INT_TABLE = [
[7, "倶胝"],
[14, "阿庾多"],
[28, "那由他"],
[56, "頻波羅"],
[112, "矜羯羅"],
[224, "阿伽羅"],
[448, "最勝"],
[896, "摩婆羅"],
[1792, "阿婆羅"],
[3584, "多婆羅"],
[7168, "界分"],
[14336, "普摩"],
[28672, "禰摩"],
[57344, "阿婆鈐"],
[114688, "弥伽婆"],
[229376, "毘攞伽"],
[458752, "毘伽婆"],
[917504, "僧羯邏摩"],
[1835008, "毘薩羅"],
[3670016, "毘贍婆"],
[7340032, "毘盛伽"],
[14680064, "毘素陀"],
[29360128, "毘婆訶"],
[58720256, "毘薄底"],
[117440512, "毘佉擔"],
[234881024, "称量"],
[469762048, "一持"],
[939524096, "異路"],
[1879048192, "顛倒"],
[3758096384, "三末耶"],
[7516192768, "毘睹羅"],
[15032385536, "奚婆羅"],
[30064771072, "伺察"],
[60129542144, "周広"],
[120259084288, "高出"],
[240518168576, "最妙"],
[481036337152, "泥羅婆"],
[962072674304, "訶理婆"],
[1924145348608, "一動"],
[3848290697216, "訶理蒲"],
[7696581394432, "訶理三"],
[15393162788864, "奚魯伽"],
[30786325577728, "達攞歩陀"],
[61572651155456, "訶魯那"],
[123145302310912, "摩魯陀"],
[246290604621824, "懺慕陀"],
[492581209243648, "瑿攞陀"],
[985162418487296, "摩魯摩"],
[1970324836974592, "調伏"],
[3940649673949184, "離憍慢"],
[7881299347898368, "不動"],
[15762598695796736, "極量"],
[31525197391593472, "阿麼怛羅"],
[63050394783186944, "勃麼怛羅"],
[126100789566373888, "伽麼怛羅"],
[252201579132747776, "那麼怛羅"],
[504403158265495552, "奚麼怛羅"],
[1008806316530991104, "鞞麼怛羅"],
[2017612633061982208, "鉢羅麼怛羅"],
[4035225266123964416, "尸婆麼怛羅"],
[8070450532247928832, "翳羅"],
[16140901064495857664, "薜羅"],
[32281802128991715328, "諦羅"],
[64563604257983430656, "偈羅"],
[129127208515966861312, "窣歩羅"],
[258254417031933722624, "泥羅"],
[516508834063867445248, "計羅"],
[1033017668127734890496, "細羅"],
[2066035336255469780992, "睥羅"],
[4132070672510939561984, "謎羅"],
[8264141345021879123968, "娑攞荼"],
[16528282690043758247936, "謎魯陀"],
[33056565380087516495872, "契魯陀"],
[66113130760175032991744, "摩睹羅"],
[132226261520350065983488, "娑母羅"],
[264452523040700131966976, "阿野娑"],
[528905046081400263933952, "迦麼羅"],
[1057810092162800527867904, "摩伽婆"],
[2115620184325601055735808, "阿怛羅"],
[4231240368651202111471616, "醯魯耶"],
[8462480737302404222943232, "薜魯婆"],
[16924961474604808445886464, "羯羅波"],
[33849922949209616891772928, "訶婆婆"],
[67699845898419233783545856, "毘婆羅"],
[135399691796838467567091712, "那婆羅"],
[270799383593676935134183424, "摩攞羅"],
[541598767187353870268366848, "娑婆羅"],
[1083197534374707740536733696, "迷攞普"],
[2166395068749415481073467392, "者麼羅"],
[4332790137498830962146934784, "駄麼羅"],
[8665580274997661924293869568, "鉢攞麼陀"],
[17331160549995323848587739136, "毘迦摩"],
[34662321099990647697175478272, "烏波跋多"],
[69324642199981295394350956544, "演説"],
[138649284399962590788701913088, "無尽"],
[277298568799925181577403826176, "出生"],
[554597137599850363154807652352, "無我"],
[1109194275199700726309615304704, "阿畔多"],
[2218388550399401452619230609408, "青蓮華"],
[4436777100798802905238461218816, "鉢頭摩"],
[8873554201597605810476922437632, "僧祇"],
[17747108403195211620953844875264, "趣"],
[35494216806390423241907689750528, "至"],
[70988433612780846483815379501056, "阿僧祇"],
[141976867225561692967630759002112, "阿僧祇転"],
[283953734451123385935261518004224, "無量"],
[567907468902246771870523036008448, "無量転"],
[1135814937804493543741046072016896, "無辺"],
[2271629875608987087482092144033792, "無辺転"],
[4543259751217974174964184288067584, "無等"],
[9086519502435948349928368576135168, "無等転"],
[18173039004871896699856737152270336, "不可数"],
[36346078009743793399713474304540672, "不可数転"],
[72692156019487586799426948609081344, "不可称"],
[145384312038975173598853897218162688, "不可称転"],
[290768624077950347197707794436325376, "不可思"],
[581537248155900694395415588872650752, "不可思転"],
[1163074496311801388790831177745301504, "不可量"],
[2326148992623602777581662355490603008, "不可量転"],
[4652297985247205555163324710981206016, "不可説"],
[9304595970494411110326649421962412032, "不可説転"],
[18609191940988822220653298843924824064, "不可説不可説"],
[37218383881977644441306597687849648128, "不可説不可説転"],
].reverse
Rしヴぁう = {
:b => :u,
:c => :u,
:d => :o,
:f => :u,
:g => :u,
:h => :u,
:j => :u,
:k => :u,
:l => :u,
:m => :u,
:n => :u,
:p => :u,
:q => :u,
:r => :u,
:s => :u,
:t => :o,
:v => :u,
:w => :u,
:x => :u,
:y => :u,
:z => :u,
}
R平 = {
:a => :あ, :i => :い, :u => :う, :e => :え, :o => :お,
:ba => :ば, :bi => :び, :bu => :ぶ, :be => :べ, :bo => :ぼ,
:ca => :か, :ci => :き, :cu => :く, :ce => :け, :co => :こ,
:da => :だ, :di => :どぃ, :du => :どぅ, :de => :で, :do => :ど,
:fa => :ふぁ, :fi => :ふぃ, :fu => :ふ, :fe => :ふぇ, :fo => :ふぉ,
:ga => :が, :gi => :ぎ, :gu => :ぐ, :ge => :げ, :go => :ご,
:ha => :は, :hi => :ひ, :hu => :ふ, :he => :へ, :ho => :ほ,
:ja => :じぁ, :ji => :じ, :ju => :じぅ, :je => :じぇ, :jo => :じぉ,
:ka => :か, :ki => :き, :ku => :く, :ke => :け, :ko => :こ,
:la => :ら, :li => :り, :lu => :る, :le => :れ, :lo => :ろ,
:ma => :ま, :mi => :み, :mu => :む, :me => :め, :mo => :も,
:na => :な, :ni => :に, :nu => :ぬ, :ne => :ね, :no => :の,
:pa => :ぱ, :pi => :ぴ, :pu => :ぷ, :pe => :ぺ, :po => :ぽ,
:qa => :か, :qi => :き, :qu => :く, :qe => :け, :qo => :こ,
:ra => :ら, :ri => :り, :ru => :る, :re => :れ, :ro => :ろ,
:sa => :さ, :si => :すぃ, :su => :す, :se => :せ, :so => :そ,
:ta => :た, :ti => :てぃ, :tu => :とぅ, :te => :て, :to => :と,
:va => :ヴぁ, :vi => :ヴぃ, :vu => :ヴぅ, :ve => :ヴぇ, :vo => :ヴぉ,
:wa => :わ, :wi => :ゐ, :wu => :ゐぅ, :we => :ゑ, :wo => :を,
:xa => :くさ, :xi => :くすぃ, :xu => :くす, :xe => :くせ, :xo => :くそ,
:ya => :いぁ, :yi => :いぃ, :yu => :いぅ, :ye => :いぇ, :yo => :いぉ,
:za => :ざ, :zi => :ずぃ, :zu => :ず, :ze => :ぜ, :zo => :ぞ,
}
R片 = {
:が => :ガ,:ぎ => :ギ,:ぐ => :グ,:げ => :ゲ,:ご => :ゴ,
:ざ => :ザ,:じ => :ジ,:ず => :ズ,:ぜ => :ゼ,:ぞ => :ゾ,
:だ => :ダ,:ぢ => :ヂ,:づ => :ヅ,:で => :デ,:ど => :ド,
:ば => :バ,:び => :ビ,:ぶ => :ブ,:べ => :ベ,:ぼ => :ボ,
:ぱ => :パ,:ぴ => :ピ,:ぷ => :プ,:ぺ => :ペ,:ぽ => :ポ,
:あ => :ア,:い => :イ,:う => :ウ,:え => :エ,:お => :オ,
:か => :カ,:き => :キ,:く => :ク,:け => :ケ,:こ => :コ,
:さ => :サ,:し => :シ,:す => :ス,:せ => :セ,:そ => :ソ,
:た => :タ,:ち => :チ,:つ => :ツ,:て => :テ,:と => :ト,
:な => :ナ,:に => :ニ,:ぬ => :ヌ,:ね => :ネ,:の => :ノ,
:は => :ハ,:ひ => :ヒ,:ふ => :フ,:へ => :ヘ,:ほ => :ホ,
:ま => :マ,:み => :ミ,:む => :ム,:め => :メ,:も => :モ,
:ら => :ラ,:り => :リ,:る => :ル,:れ => :レ,:ろ => :ロ,
:わ => :ワ,:を => :ヲ,:ゑ => :ヱ,:ゐ => :ヰ,:ヴ => :ヴ,
:ぁ => :ァ,:ぃ => :ィ,:ぅ => :ゥ,:ぇ => :ェ,:ぉ => :ォ,
:ゃ => :ャ,:ゅ => :ュ,:ょ => :ョ,
:や => :ヤ,:ゆ => :ユ,:よ => :ヨ,
:ん => :ン,:っ => :ッ,:ゎ => :ヮ,
}
def 鍵文字を登録
R鍵文字.each_pair do |甲,乙|
Unparser::Constants.const_set 乙[0], 乙[1].to_s
Unparser::Emitter::REGISTRY[乙[1].to_sym] = Unparser::Emitter::REGISTRY[甲.to_sym]
end
Unparser::Emitter::Repetition::MAP[:while] = R鍵文字[:while][1].to_s
Unparser::Emitter::Repetition::MAP[:until] = R鍵文字[:until][1].to_s
Unparser::Emitter::FlowModifier::MAP[:return] = R鍵文字[:return][1].to_s
Unparser::Emitter::FlowModifier::MAP[:next] = R鍵文字[:next][1].to_s
Unparser::Emitter::FlowModifier::MAP[:break] = R鍵文字[:break][1].to_s
Unparser::Emitter::FlowModifier::MAP[:or] = R鍵文字[:or][1].to_s
Unparser::Emitter::FlowModifier::MAP[:and] = R鍵文字[:and][1].to_s
Unparser::Emitter::FlowModifier::MAP[:BEGIN] = R鍵文字[:BEGIN][1].to_s
Unparser::Emitter::FlowModifier::MAP[:END] = R鍵文字[:END][1].to_s
end
class Float
def inspect
フロートの文字化(self)
end
end
class BigDecimal
def inspect
フロートの文字化(self.to_s('F'))
end
end
class Integer
def inspect
整数の文字化(self)
end
end
class Fixnum
def inspect
整数の文字化(self)
end
end
class Bignum
def inspect
整数の文字化(self)
end
end
def 整数の文字化(整数)
数字 = 整数.to_s
if 数字.size <= 7
return 数字.chars.map{|甲|R数字行列[甲]}.join
else
乙 = INT_TABLE.find{|甲|甲[0] < 数字.size}
整数の文字化(数字[0...-乙[0]]) + 乙[1] + 整数の文字化(数字[(-乙[0])..-1])
end
end
def フロートの文字化(フロート)
甲 = フロート.to_s.split(?.)
甲[0] = 整数の文字化(甲[0])
甲[1] = 甲[1].chars.map{|乙|R数字行列[乙]}.join
甲.join(?点)
end
def 文字を翻訳(文字)
平片 = :hira
文字.scan(/([^aeiou])?(\1)?([yj])?([aeiou])?/i).map do |子音甲,子音乙,子音丙,母音|
母音 = 母音.to_s
if 子音甲.nil? && 母音.empty?
nil
else
平片 = :kata if (子音甲||母音).downcase!=(子音甲||母音)
子音甲,子音乙,子音丙,母音 = [子音甲,子音乙,子音丙,母音].map{|x| x ? x.downcase : x }
if 母音.empty?
母音 = Rしヴぁう[子音甲.to_sym].to_s
end
# hu => ひゅ, qu => きゅ
if 母音=="u" && (子音甲=="h"||子音甲=="q")
子音丙 = "y"
end
# ja,ju,jo => じゃ、じゅ,じょ
if (母音=="a"||母音=="u"||母音=="o") && 子音甲 == "j"
子音丙 = "y"
end
# 拗音
if 子音丙
if [:a,:u,:o].include?(母音)
子音丙 = case 母音
when :a ; :ゃ
when :u ; :ゅ
when :o ; :ょ
end
母音 = :i
else
子音丙 = nil
end
end
# basic syllable
仮名 = R平[(子音甲.to_s+母音).to_sym].to_s
# 促音
if 子音乙
if %w[ま み む め も な に ぬ ね の].include?(子音乙)
仮名 = "ん" + 仮名
else
仮名 = "っ" + 仮名
end
end
# 拗音
if 子音丙
仮名 = 仮名 + 子音丙
end
# lowercase => hiragana, uppercase => katakana
if 平片==:kata
仮名 = 仮名.gsub(/./){|丁|R片[丁.to_sym]}.to_s
end
仮名
end
end.compact.join
end
def 文を翻訳(文)
文.scan(/(([a-z]+|[0-9]+|[^a-z0-9]+))/i).map do |文字,_|
if 文字.index(/[a-z]/i)
文字を翻訳(文字)
elsif 文字.index(/[0-9]/)
整数の文字化(文字)
else
文字
end
end.compact.join
end
def 翻訳(文章=nil)
if 文章.empty? || 文章.nil?
文章
else
if 甲 = R翻訳行列[文章.to_sym]
甲
elsif 甲 = R翻訳メモリー[文章]
甲
else
甲 = 文を翻訳(文章.to_s)
R翻訳メモリー[文章] = 甲
end
end
end
def ノード毎に(幹,&塊)
if 幹.is_a? Parser::AST::Node
子供 = 幹.children
yield 幹.type,子供
幹.children.each{|甲|ノード毎に(甲,&塊)}
if 甲 = R鍵文字[幹.type]
幹.instance_variable_set(:@type,甲[1]) if [:self,:true,:false,:nil].include?(幹.type)
end
end
end
def 幹を翻訳(幹)
ノード毎に(幹) do |類,子|
case 類
when :arg
子[0] = 翻訳(子[0]).to_sym
when :blockarg
子[0] = 翻訳(子[0]).to_sym
when :casgn
子[1] = ('C_'+翻訳(子[1]).to_s).to_sym
when :const
子[1] = 翻訳(子[1]).to_sym
when :def
子[0] = 翻訳(子[0]).to_sym
when :int
when :kwoptarg
子[0] = 翻訳(子[0]).to_sym
when :lvar
子[0] = 翻訳(子[0]).to_sym
when :lvasgn
子[0] = 翻訳(子[0]).to_sym
when :optarg
子[0] = 翻訳(子[0]).to_sym
when :restarg
子[0] = 翻訳(子[0]).to_sym
when :send
子[1] = 翻訳(子[1]).to_sym
when :str
子[0] = 翻訳(子[0]).to_s
when :sym
子[0] = 翻訳(子[0]).to_sym
end
end
end
def ノートを翻訳(ノート)
ノート.each do |子|
テキスト = 子.text
if テキスト[0] == '#'
子.instance_variable_set(:@text,"#" + 翻訳(テキスト[1..-1]))
else
子.instance_variable_set(:@text,"=開始\n" + 翻訳(テキスト[6..-6]) + "\n=此処迄\n")
end
end
end
########
# main #
########
# register keywords
鍵文字を登録
# read input, translate, and print result
コード = STDIN.read
コード.encode(Encoding::UTF_8)
コード = "#encoding:utf-8\n" + コード
幹, ノート = Parser::CurrentRuby.parse_with_comments(コード)
幹を翻訳(幹)
ノートを翻訳(ノート)
STDOUT.write Unparser.unparse(幹,ノート)
Run on itself, omitting some translation tables etc:
#えぬこどぃぬぐ:うとふ-捌
# えぬこどぃぬぐ:うとふ-捌
取り込む("ぱるせる/くっれぬと")
# すぺる はくく, どぬ'と とる とひす あと ほめ!!
クラス 配列
定義 凍結
自身
此処迄
此処迄
クラス ハッシュ表
定義 凍結
自身
此処迄
此処迄
クラス パルセル::アスト::ノデ
定義 凍結
自身
此処迄
此処迄
取り込む("うぬぱるせる")
クラス パルセル::ソウルケ::コッメヌト
定義 凍結
自身
此処迄
此処迄
定義 鍵文字を登録
ル鍵文字.えあくふ_ぱいる 実行 |甲, 乙|
ウヌパルセル::コヌスタヌトス.こぬすと_せと(乙[零], 乙[壹].と_す)
ウヌパルセル::エミッテル::レギストル[乙[壹].と_すむ] = ウヌパルセル::エミッテル::レギストル[甲.と_すむ]
此処迄
ウヌパルセル::エミッテル::レペティティオヌ::マプ[:ゐぅひれ] = ル鍵文字[:ゐぅひれ][壹].と_す
ウヌパルセル::エミッテル::レペティティオヌ::マプ[:うぬてぃる] = ル鍵文字[:うぬてぃる][壹].と_す
ウヌパルセル::エミッテル::フロヰゥモドィフィエル::マプ[:れとぅるぬ] = ル鍵文字[:れとぅるぬ][壹].と_す
ウヌパルセル::エミッテル::フロヰゥモドィフィエル::マプ[:ねくすと] = ル鍵文字[:ねくすと][壹].と_す
ウヌパルセル::エミッテル::フロヰゥモドィフィエル::マプ[:ぶれあく] = ル鍵文字[:ぶれあく][壹].と_す
ウヌパルセル::エミッテル::フロヰゥモドィフィエル::マプ[:おる] = ル鍵文字[:おる][壹].と_す
ウヌパルセル::エミッテル::フロヰゥモドィフィエル::マプ[:あぬど] = ル鍵文字[:あぬど][壹].と_す
ウヌパルセル::エミッテル::フロヰゥモドィフィエル::マプ[:ベギヌ] = ル鍵文字[:ベギヌ][壹].と_す
ウヌパルセル::エミッテル::フロヰゥモドィフィエル::マプ[:エヌド] = ル鍵文字[:エヌド][壹].と_す
此処迄
クラス 浮動小数点数
定義 検査
フロートの文字化(自身)
此処迄
此処迄
クラス ビグデキマル
定義 検査
フロートの文字化(自身.と_す("フ"))
此処迄
此処迄
クラス 整数
定義 検査
整数の文字化(自身)
此処迄
此処迄
クラス 固定長整数
定義 検査
整数の文字化(自身)
此処迄
此処迄
クラス 多倍長整数
定義 検査
整数の文字化(自身)
此処迄
此処迄
定義 整数の文字化(整数)
数字 = 整数.と_す
若し (数字.すぃぜ <= 漆)
戻る 数字.くはるす.まぷ 実行 |甲|
ル数字行列[甲]
此処迄.じぉいぬ
違えば
乙 = イヌト_タブレ.ふぃぬど 実行 |甲|
甲[零] < 数字.すぃぜ
此処迄
(整数の文字化(数字[零...(-乙[零])]) + 乙[壹]) + 整数の文字化(数字[(-乙[零])..壹])
此処迄
此処迄
定義 フロートの文字化(フロート)
甲 = フロート.と_す.すぷりと(".")
甲[零] = 整数の文字化(甲[零])
甲[壹] = 甲[壹].くはるす.まぷ 実行 |乙|
ル数字行列[乙]
此処迄.じぉいぬ
甲.じぉいぬ("点")
此処迄
定義 文字を翻訳(文字)
平片 = :ひら
文字.すかぬ(/([^あえいおう])?(\壹)?([いぅ])?([あえいおう])?/i).まぷ 実行 |子音甲, 子音乙, 子音丙, 母音|
母音 = 母音.と_す
若し (子音甲.にる? && 母音.えむぷと?)
無
違えば
若し ((子音甲 || 母音).どゐぅぬかせ != (子音甲 || 母音))
平片 = :かた
此処迄
子音甲, 子音乙, 子音丙, 母音 = [子音甲, 子音乙, 子音丙, 母音].まぷ 実行 |くす|
若し くす
くす.どゐぅぬかせ
違えば
くす
此処迄
此処迄
若し 母音.えむぷと?
母音 = ルしヴぁう[子音甲.と_すむ].と_す
此処迄
# ふ => ひゅ, く => きゅ
若し ((母音 == "う") && ((子音甲 == "ふ") || (子音甲 == "く")))
子音丙 = "いぅ"
此処迄
# じぁ,じぅ,じぉ => じゃ、じゅ,じょ
若し ((((母音 == "あ") || (母音 == "う")) || (母音 == "お")) && (子音甲 == "じぅ"))
子音丙 = "いぅ"
此処迄
# 拗音
若し 子音丙
若し [:あ, :う, :お].いぬくるで?(母音)
子音丙 = 条件分岐 母音
場合 :あ
:ゃ
場合 :う
:ゅ
場合 :お
:ょ
此処迄
母音 = :い
違えば
子音丙 = 無
此処迄
此処迄
# ばすぃく すっらぶれ
仮名 = ル平[(子音甲.と_す + 母音).と_すむ].と_す
# 促音
若し 子音乙
若し ["ま", "み", "む", "め", "も", "な", "に", "ぬ", "ね", "の"].いぬくるで?(子音乙)
仮名 = ("ん" + 仮名)
違えば
仮名 = ("っ" + 仮名)
此処迄
此処迄
# 拗音
若し 子音丙
仮名 = (仮名 + 子音丙)
此処迄
# ろゑるかせ => ひらがな, うっぺるかせ => かたかな
若し (平片 == :かた)
仮名 = 仮名.全文字列置換(/./) 実行 |丁|
ル片[丁.と_すむ]
此処迄.と_す
此処迄
仮名
此処迄
此処迄.こむぱくと.じぉいぬ
此処迄
定義 文を翻訳(文)
文.すかぬ(/(([あ-ず]+|[零-玖]+|[^あ-ず零-玖]+))/i).まぷ 実行 |文字, _|
若し 文字.いぬでくす(/[あ-ず]/i)
文字を翻訳(文字)
違えば
若し 文字.いぬでくす(/[零-玖]/)
整数の文字化(文字)
違えば
文字
此処迄
此処迄
此処迄.こむぱくと.じぉいぬ
此処迄
定義 翻訳(文章 = 無)
若し (文章.えむぷと? || 文章.にる?)
文章
違えば
若し (甲 = ル翻訳行列[文章.と_すむ])
甲
違えば
若し (甲 = ル翻訳メモリー[文章])
甲
違えば
甲 = 文を翻訳(文章.と_す)
ル翻訳メモリー[文章] = 甲
此処迄
此処迄
此処迄
此処迄
定義 ノード毎に(幹, &塊)
若し 幹.いす_あ?(パルセル::アスト::ノデ)
子供 = 幹.くひるどれぬ
ブロックを呼び出す(幹.とぺ, 子供)
幹.くひるどれぬ.えあくふ 実行 |甲|
ノード毎に(甲, &塊)
此処迄
若し (甲 = ル鍵文字[幹.とぺ])
若し [:せるふ, :とるえ, :ふぁるせ, :にる].いぬくるで?(幹.とぺ)
幹.いぬすたぬけ_ヴぁりあぶれ_せと(:@とぺ, 甲[壹])
此処迄
此処迄
此処迄
此処迄
定義 幹を翻訳(幹)
ノード毎に(幹) 実行 |類, 子|
条件分岐 類
場合 :あるぐ
子[零] = 翻訳(子[零]).と_すむ
場合 :ぶろくかるぐ
子[零] = 翻訳(子[零]).と_すむ
場合 :かすぐぬ
子[壹] = ("ク_" + 翻訳(子[壹]).と_す).と_すむ
場合 :こぬすと
子[壹] = 翻訳(子[壹]).と_すむ
場合 :でふ
子[零] = 翻訳(子[零]).と_すむ
場合 :いぬと
場合 :くをぷたるぐ
子[零] = 翻訳(子[零]).と_すむ
場合 :るヴぁる
子[零] = 翻訳(子[零]).と_すむ
場合 :るヴぁすぐぬ
子[零] = 翻訳(子[零]).と_すむ
場合 :おぷたるぐ
子[零] = 翻訳(子[零]).と_すむ
場合 :れすたるぐ
子[零] = 翻訳(子[零]).と_すむ
場合 :せぬど
子[壹] = 翻訳(子[壹]).と_すむ
場合 :すとる
子[零] = 翻訳(子[零]).と_す
場合 :すむ
子[零] = 翻訳(子[零]).と_すむ
此処迄
此処迄
此処迄
定義 ノートを翻訳(ノート)
ノート.えあくふ 実行 |子|
テキスト = 子.てくすと
若し (テキスト[零] == "#")
子.いぬすたぬけ_ヴぁりあぶれ_せと(:@てくすと, "#" + 翻訳(テキスト[壹..壹]))
違えば
子.いぬすたぬけ_ヴぁりあぶれ_せと(:@てくすと, ("=開始\n" + 翻訳(テキスト[陸..陸])) + "\n=此処迄\n")
此処迄
此処迄
此処迄
########
# まいぬ #
########
# れぎすてる けいぅをるどす
鍵文字を登録
# れあど いぬぷと, とらぬすらて, あぬど ぷりぬと れすると
コード = ストドィヌ.れあど
コード.えぬこで(エヌコドィヌグ::ウトフ_捌)
コード = ("#えぬこどぃぬぐ:うとふ-捌\n" + コード)
幹, ノート = パルセル::クッレヌトルブ.ぱるせ_ゐとふ_こっめぬとす(コード)
幹を翻訳(幹)
ノートを翻訳(ノート)
ストドウト.ゐぅりて(ウヌパルセル.うぬぱるせ(幹, ノート))
or
# Output "I love Ruby"
say = "I love Ruby"
puts say
# Output "I *LOVE* RUBY"
say['love'] = "*love*"
puts say.upcase
# Output "I *love* Ruby"
# five times
5.times { puts say }
becomes
#えぬこどぃぬぐ:うとふ-捌
# オウトプト "イ ろヴぇ ルブ"
さいぅ = "イ ろヴぇ ルブ"
言う(さいぅ)
# オウトプト "イ *ロヴェ* ルブ"
さいぅ["ろヴぇ"] = "*ろヴぇ*"
言う(さいぅ.うぷかせ)
# オウトプト "イ *ろヴぇ* ルブ"
# ふぃヴぇ てぃめす
伍.てぃめす 実行
言う(さいぅ)
此処迄
























{kind=link}
translates its own source code--meaning it has to read its own file, or can the source code be given on stdin? – DLosc – 2015-06-01T06:08:26.227It doesn't matter how it generates the output as long as it solves the challenge. It may not read a pre-translated version of itself, however! Answering your specific question, both reading its own source from storage or memory is allowed as is passing it through on stdin. – CJ Dennis – 2015-06-01T06:19:40.393
4"print" would become "imprimer" (as in "printer"), not "empreinte" (as in "footprint") :) – Quentin – 2015-06-01T12:02:46.257
4@Quentin I never claimed it was good French! – CJ Dennis – 2015-06-01T12:25:36.270
13I think it's bad enough that Excel has native language support.. :(. Makes debugging formulas so much harder – Mave – 2015-06-01T13:42:49.507
1@Quentin I'm now wondering if the French verbs should use the imperative instead of the infinitive. The only problem is my French isn't good enough for that! – CJ Dennis – 2015-06-01T15:36:03.383
3@CJDennis In French pseudocode I've always seen the infinitive, but I can give a hand if needed :p – Quentin – 2015-06-01T15:43:18.513
@Quentin Would it be
imprimeandtraduis? Or pehapsimprimezandtraduites? Although I think a computer should be subordinate to a person, so maybe the former? – CJ Dennis – 2015-06-01T15:52:02.213@CJDennis Yeah, I guess I'd say "tu" to a computer, not "vous". It's "traduisez", though :) – Quentin – 2015-06-01T15:53:31.710
Can I write a code in a language that translates another language? – Ismael Miguel – 2015-06-02T09:32:20.910
@IsmaelMiguel Unless you can give me a really good reason I'll say no. So far all the submissions have worked on the same language. – CJ Dennis – 2015-06-02T11:45:29.240
@CJDennis The only reason was that I have a syntax highlighter for SQL (written in Javascript) and I would use to translate it in Portuguese. But I realized that that (yes, I meant to repeat that) is not the spirit of this challenge. – Ismael Miguel – 2015-06-02T11:57:33.567
@IsmaelMiguel You meant to repeat that that? – CJ Dennis – 2015-06-02T13:13:34.690
@CJDennis Exactly. That that was intentionally repeated. It isn't a mistake. – Ismael Miguel – 2015-06-02T13:17:17.980
1
It's only tangentially related but you might be interested in http://en.wikipedia.org/wiki/Logo_(programming_language) The English-language article does not really explain it but it was intended to be (and has actually been) translated in various languages so that the primitives match the user's natural language. We used a French version of this language in primary school.
– Relaxed – 2015-06-03T18:13:53.200@Relaxed Thanks for that! I want to post a few answers myself later and I was considering Logo so if I go ahead with that one I'll check which languages it has already been translated into! – CJ Dennis – 2015-06-04T05:16:09.730
1I would like to see an "ouroboros program" that translates its source code into a foreign language, which, when compiled/interpreted on the appropriate foreign language compiler/interpreter, is a program that outputs the original English source code. – John Peter Thompson Garcés – 2015-06-04T18:19:40.363
1
In case anyone's interested in real non-English programming languages (sorry @Mave!) : here's one in my native tongue Tamil, and here's a bunch more in several different languages.
– sundar - Reinstate Monica – 2015-06-05T11:55:13.037@IsmaelMiguel — I don't understand what you want to do. Can you give an example? – Nicolas Barbulesco – 2015-06-07T00:52:59.530
@NicolasBarbulesco What do you mean? – Ismael Miguel – 2015-06-07T00:55:33.010
@NicolasBarbulesco I believe Ismael Miguel wanted to use Javascript to translate SQL. He would have to use SQL to translate SQL. – CJ Dennis – 2015-06-07T05:56:15.890
This reminds me of the Arabic Lisp someone made (reddit). It has syntactic features that aren't possible in Latin print, like lining things up by stretching out letters.
– Joey Adams – 2015-06-09T17:07:57.577There are plenty of programming languages in which you can write a useful program that uses no keywords (and as written, the null program is a valid solution in all the languages where it acts like
catby default). This is likely going to have to require at least one keyword to be translated. – None – 2017-04-11T02:36:08.247