30
1
Here is a simple ASCII art ruby:
___
/\_/\
/_/ \_\
\ \_/ /
\/_\/
As a jeweler for the ASCII Gemstone Corporation, your job is inspect the newly acquired rubies and leave a note about any defects that you find.
Luckily, only 12 types of defects are possible, and your supplier guarantees that no ruby will have more than one defect.
The 12 defects correspond to the replacement of one of the 12 inner _, /, or \ characters of the ruby with a space character (). The outer perimeter of a ruby never has defects.
The defects are numbered according to which inner character has a space in its place:
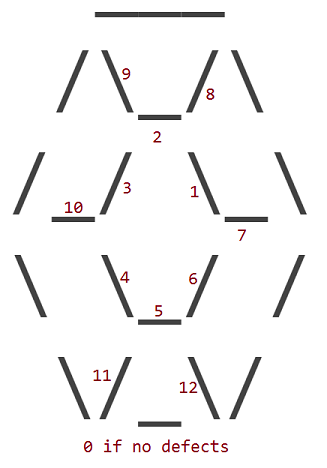
So a ruby with defect 1 looks like this:
___
/\_/\
/_/ _\
\ \_/ /
\/_\/
A ruby with defect 11 looks like this:
___
/\_/\
/_/ \_\
\ \_/ /
\ _\/
It's the same idea for all other defects.
Challenge
Write a program or function that takes in the string of a single, potentially defective ruby. The defect number should be printed or returned. The defect number is 0 if there is no defect.
Take input from a text file, stdin, or a string function argument. Return the defect number or print it to stdout.
You may assume that the ruby has a trailing newline. You may not assume that it has any trailing spaces or leading newlines.
The shortest code in bytes wins. (Handy byte counter.)
Test Cases
The 13 exact types of rubies, followed directly by their expected output:
___
/\_/\
/_/ \_\
\ \_/ /
\/_\/
0
___
/\_/\
/_/ _\
\ \_/ /
\/_\/
1
___
/\ /\
/_/ \_\
\ \_/ /
\/_\/
2
___
/\_/\
/_ \_\
\ \_/ /
\/_\/
3
___
/\_/\
/_/ \_\
\ _/ /
\/_\/
4
___
/\_/\
/_/ \_\
\ \ / /
\/_\/
5
___
/\_/\
/_/ \_\
\ \_ /
\/_\/
6
___
/\_/\
/_/ \ \
\ \_/ /
\/_\/
7
___
/\_ \
/_/ \_\
\ \_/ /
\/_\/
8
___
/ _/\
/_/ \_\
\ \_/ /
\/_\/
9
___
/\_/\
/ / \_\
\ \_/ /
\/_\/
10
___
/\_/\
/_/ \_\
\ \_/ /
\ _\/
11
___
/\_/\
/_/ \_\
\ \_/ /
\/_ /
12

Calvin's Hobbies
Posted 2015-04-07T02:33:00.663
Reputation: 84 000











To clarify, the ruby cannot have any trailing spaces, right ? – Optimizer – 2015-04-07T05:44:49.593
@Optimizer Correct – Calvin's Hobbies – 2015-04-07T06:02:18.090
@Calvin'sHobbies May we also assume the input does not have a trailing newline? – orlp – 2015-04-07T08:39:23.973
@orlp Yes. That's the whole point of may. – Calvin's Hobbies – 2015-04-07T09:19:44.317
The rubies are symmetrical. So shouldn't error #7 be the same as error #10, for example? – DavidC – 2015-04-07T23:18:58.570
@DavidCarraher That's really a matter of convention. So no. – Calvin's Hobbies – 2015-04-08T00:11:28.243