24
3
I've become alarmed with the growing hatred of spaces and this answer has inspired me to make sure Morse code is safe from this insidious removal of whitespace.
So, your task will be to create a program that can successfully translate Morse code with all of the spaces removed.
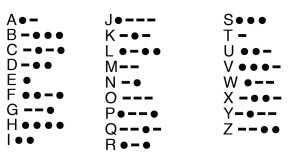
Rules:
Input will be a string consisting only of dashes and dots (ASCII 2D and 2E). Output is undefined for input containing any other characters. Feel free to use any method convenient to your language of choice to receive the input (stdin, text file, prompt user, whatever). You can assume that the Morse code input only consists of the letters A-Z, and matching numbers or punctuation is not required.
Output should include only words contained in this dictionary file (again, feel free to use any convenient method to access the dictionary file). All valid decodings should be output to stdout, and all dots and dashes in the input must be used. Each matched word in the output should be separated by a space, and each possible decoding should separated by a newline. You can use upper case, lower case, or mixed case output as convenient.
All restrictions on standard loopholes apply with one exception as noted above, you may access the dictionary file referenced in requirement 2 via an internet connection if you really want to. URL shortening is acceptable, I believe that goo.gl/46I35Z is likely the shortest.
This is code golf, shortest code wins.
Note: Posting the dictionary file on Pastebin changed all of the line endings to Windows style 0A 0E sequences. Your program can assume line endings with 0A only, 0E only or 0A 0E.
Test Cases:
Input:
......-...-..---.-----.-..-..-..
Output must contain:
hello world
Input:
.--..-.-----..-..-----..-.--..--...---..--...-.......--.-..-.-.----...--.---.-....-.
Output must contain:
programming puzzles and code golf
Input:
-.....--.-..-..-.-.-.--....-.---.---...-.----..-.---..---.--....---...-..-.-......-...---..-.---..-----.
Output must contain:
the quick brown fox jumps over the lazy dog

Comintern
Posted 2014-08-24T17:02:38.540
Reputation: 3 632







{kind=link}
@seequ
egis not in the list, butateandweare. ;)eisner a go mae a eresounds nice. – Titus – 2017-02-04T09:39:43.333What do You want with all the irish family names in the word list? What are we supposed to do with the
'? My code will take it as end of word. – Titus – 2017-02-04T10:57:51.5103How can you tell between
AN (.- -.)andEG (. --.)? – seequ – 2014-08-24T18:06:53.610@Sieg You look up possible combinations in the dictionary – Beta Decay – 2014-08-24T18:09:30.947
@Sieg - That is the crux of the challenge. EG isn't in the word file - AN is. If there are multiple valid decodings, you output them all. Although I would be extremely impressed if somebody checks for valid grammar as well. – Comintern – 2014-08-24T18:09:52.950
@Comintern I bet there are words where similar problem arises. – seequ – 2014-08-24T19:25:32.277
2@Sieg - The output would then need to include both valid decodings. – Comintern – 2014-08-24T19:31:07.773
Can I strip the carriage returns from the dictionary> – Dennis – 2014-08-24T19:34:07.123
@Dennis - To be fair, I'd have to say not before inputing it. Otherwise, I can envision several ways in which preprocessing the file could give an undo advantage. – Comintern – 2014-08-24T19:50:16.440
I could too. That's why I asked specifically about the line endings. Oh well, I'll deal with the pesky Windows format... :P – Dennis – 2014-08-24T19:52:03.563
1@Dennis - Ahhh... I'll bet that either Pastebin or my browser did that. My source file doesn't have them. You can change the line delimiter to a system appropriate one, no other changes. I'll edit into the question when I'm not on my phone. – Comintern – 2014-08-24T19:58:17.217
1
I'm afraid this challenge does not work as expected: For the "hello world" morse code example my Python prototype yields hundreds or maybe thousands of possible translations: http://pastebin.com/baveM1FH, all of which seem to be valid. I mean, technically that might be a valid solution...
– Falko – 2014-08-24T20:47:23.7732@Falko that's correct behavior. Note that the problem says your output must include "hello world", not that it's limited to that. It should print all valid decodings. – hobbs – 2014-08-25T02:55:36.543
@Falko By my count, the "hello world" example has 403,856 lines of output, eventually degenerating to stuff like "i i it i et it met to et it it i" – hobbs – 2014-08-25T13:31:49.017
2(almost poetic, really) – hobbs – 2014-08-25T13:32:32.880
1For the first input, there are 403856 answers. For the second input, there are 2889424682038128 valid answers. For the third output, there are 4986181473975221635 answers... – Ray – 2014-08-25T22:13:54.163